


[ad_1]
In machine studying, one methodology that has persistently demonstrated its price throughout numerous functions is the Help Vector Machine (SVM). Identified for its adeptness at parsing by high-dimensional areas, SVM is designed to attract an optimum dividing line, or hyperplane, between information factors belonging to totally different courses. This hyperplane is important because it permits predictions about new, unseen information, emphasizing SVM’s power in creating fashions that generalize properly past the coaching information.
A persistent problem inside SVM approaches considerations learn how to deal with samples which are both misclassified or lie too near the margin, basically, the buffer zone across the hyperplane. Conventional loss capabilities utilized in SVM, such because the hinge loss and the 0/1 loss, are pivotal for formulating the SVM optimization drawback however falter when information is just not linearly separable. In addition they exhibit a heightened sensitivity to noise and outliers throughout the coaching information, affecting the classifier’s efficiency and generalization to new information.
SVMs have leveraged quite a lot of loss capabilities to measure classification errors. These capabilities are important in organising the optimization drawback for the SVM, directing it in the direction of minimizing misclassifications. Nonetheless, typical loss capabilities have limitations. As an example, they should penalize misclassified samples adequately or those who fall throughout the margin regardless of being accurately categorized, the important boundary that delineates courses. This shortfall can detrimentally have an effect on the classifier’s generalization capacity, rendering it much less efficient when uncovered to new or unseen information.
A analysis staff from Tsinghua College has launched a Slide loss perform to assemble an SVM classifier. This progressive perform considers the severity of misclassifications and the proximity of accurately categorized samples to the choice boundary. This methodology, by the idea of proximal stationary level and properties of Lipschitz continuity, defines Slide loss perform help vectors and a working set for (Slide loss function-SVM), together with a quick alternating route methodology of multipliers (Slide loss function-ADMM) for environment friendly dealing with. By penalizing these elements in a different way, the Slide loss perform goals to refine the classifier’s accuracy and generalization capacity.
The Slide loss perform distinguishes itself by penalizing misclassified and accurately classifying samples that linger too near the choice boundary. This nuanced penalization method fosters a extra strong and discriminative mannequin. By doing so, the strategy seeks to mitigate the restrictions posed by conventional loss capabilities, providing a path to extra dependable classification even within the presence of noise and outliers.
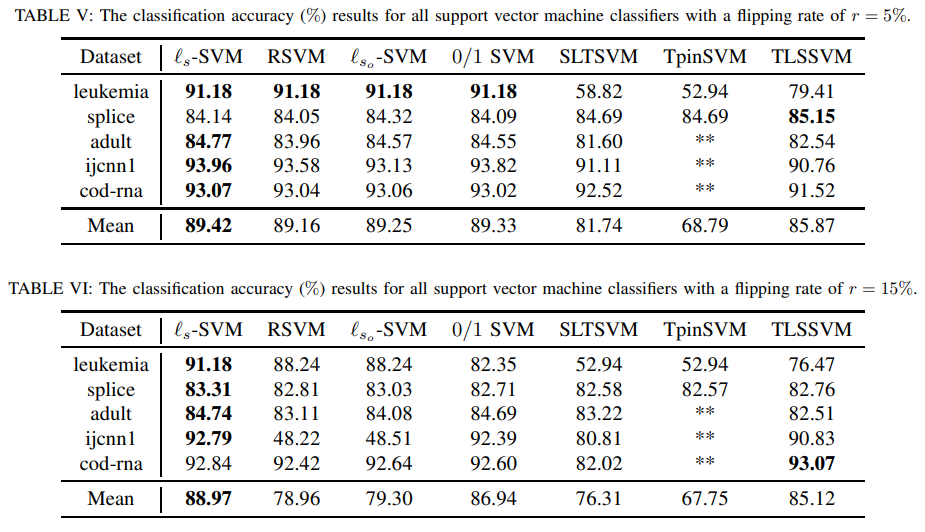
The findings have been compelling for the present analysis: the Slide loss perform SVM demonstrated a marked enchancment in generalization capacity and robustness in comparison with six different SVM solvers. It showcased superior efficiency in managing datasets with noise and outliers, underscoring its potential as a big development in SVM classification strategies.

In conclusion, the innovation of the Slide loss perform SVM addresses a important hole within the SVM methodology: the nuanced penalization of samples based mostly on their classification accuracy and proximity to the choice boundary. This method enhances the classifier’s robustness towards noise and outliers and its generalization capability, making it a noteworthy contribution to machine studying. By meticulously penalizing misclassified samples and people throughout the margin based mostly on their confidence ranges, this methodology opens new avenues for growing SVM classifiers which are extra correct and adaptable to numerous information situations.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 39k+ ML SubReddit
Hi there, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about know-how and wish to create new merchandise that make a distinction.
[ad_2]
Source link
