


[ad_1]
The capability of a mannequin to make use of inputs at inference time to switch its conduct with out updating its weights to sort out issues that weren’t current throughout coaching is called in-context studying or ICL. Neural community architectures, notably created and skilled for few-shot information the flexibility to study a desired conduct from a small variety of examples, had been the primary to exhibit this functionality. For the mannequin to carry out properly on the coaching set, it needed to keep in mind exemplar-label mappings from context to make predictions sooner or later. In these circumstances, coaching meant rearranging the labels akin to enter exemplars on every “episode.” Novel exemplar-label mappings had been equipped at take a look at time, and the community’s process was to categorize question exemplars utilizing these.
ICL analysis developed on account of the transformer’s growth. It was famous that the authors didn’t particularly attempt to encourage it by way of the coaching purpose or knowledge; fairly, the transformer-based language mannequin GPT-3 demonstrated ICL after being skilled auto-regressively at an acceptable measurement. Since then, a considerable quantity of analysis has examined or documented cases of ICL. On account of these convincing discoveries, emergent capabilities in large neural networks have been the topic of examine. Nonetheless, latest analysis has demonstrated that coaching transformers solely typically end in ICL. Researchers found that emergent ICL in transformers is considerably influenced by sure linguistic knowledge traits, resembling burstiness and its extremely skewed distribution.
The researchers from UCL and Google Deepmind found that transformers sometimes resorted to in-weight studying (IWL) when skilled on knowledge missing these traits. As an alternative of utilizing freshly equipped in-context data, the transformer within the IWL regime makes use of knowledge that’s saved within the mannequin’s weights. Crucially, ICL and IWL appear to be at odds with each other; ICL appears to emerge extra simply when coaching knowledge is bursty, that’s, when objects seem in clusters fairly than randomly—and has a excessive variety of tokens or courses. It’s important to conduct managed investigations utilizing established data-generating distributions to grasp the ICL phenomena in transformers higher.
Concurrently, an auxiliary corpus of analysis examines the emergence of gigantic fashions skilled instantly on natural web-scale knowledge, concluding that outstanding options like ICL usually tend to come up in huge fashions skilled on a better quantity of information. Nonetheless, the dependence on massive fashions presents vital pragmatic obstacles, together with fast innovation, energy-efficient coaching in low-resource environments, and deployment effectivity. Consequently, a considerable physique of analysis has focused on growing smaller transformer fashions which will present equal efficiency, together with emergent ICL. At present, the popular technique for growing compact but efficient converters is overtraining. These tiny fashions compute price range and are skilled on extra knowledge—probably repeatedly—than what scaling guidelines want.
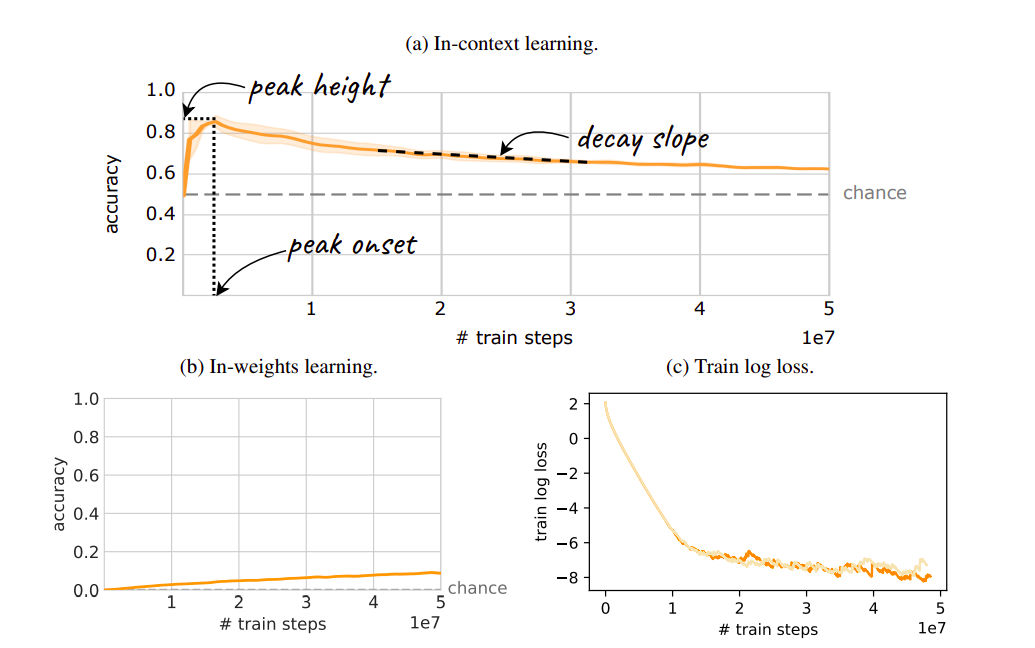
(c) Lack of coaching logs. Two hues signify the 2 experimental seeds.
Basically, overtraining is based on a premise inherent in most up-to-date investigations of ICL in LLMs, if not all of them: persistence. It’s believed {that a} mannequin can be saved throughout coaching so long as it has been taught sufficient for an ICL-dependent functionality to come up, as long as the coaching loss retains getting much less. Right here, the analysis workforce disproves the widespread perception that persistence exists. The analysis workforce do that by modifying a typical image-based few-shot dataset, which permits us to evaluate ICL totally in a managed setting. The analysis workforce supplies easy eventualities by which ICL seems after which vanishes because the lack of the mannequin retains declining.
To place it one other approach, even whereas ICL is well known as an rising phenomenon, the analysis workforce must also think about the likelihood that it could solely final quickly (Determine 1). The analysis workforce found that transience occurs for numerous mannequin sizes, dataset sizes, and dataset sorts, though the analysis workforce additionally confirmed that sure attributes can delay transience. Usually talking, networks which can be skilled irresponsibly for prolonged durations uncover that ICL might vanish simply as rapidly because it seems, depriving fashions of the talents that individuals are coming to anticipate from modern AI methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to hitch our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with folks and collaborate on attention-grabbing tasks.
[ad_2]
Source link
