

[ad_1]
Current developments in Massive Language Fashions (LLMs) have demonstrated their spectacular problem-solving means throughout a number of fields. LLMs can embody tons of of billions of parameters and are educated on monumental textual content corpora.
Research present that in LLM inference, reminiscence bandwidth, not CPU, is the important thing efficiency limitation for generative duties. This means that the speed at which parameters will be loaded and saved for memory-bound conditions, relatively than arithmetic operations, turns into the important thing latency barrier. Nevertheless, progress in reminiscence bandwidth know-how has lagged far behind computation, giving rise to a phenomenon often called the Reminiscence Wall.
Quantization is a promising methodology that entails storing mannequin parameters with much less accuracy than the standard 16 or 32 bits used throughout coaching. Regardless of latest developments like LLaMA and its instruction-following variations, it’s nonetheless troublesome to attain good quantization efficiency, particularly with decrease bit precision and comparatively modest fashions (e.g., 50B parameters).
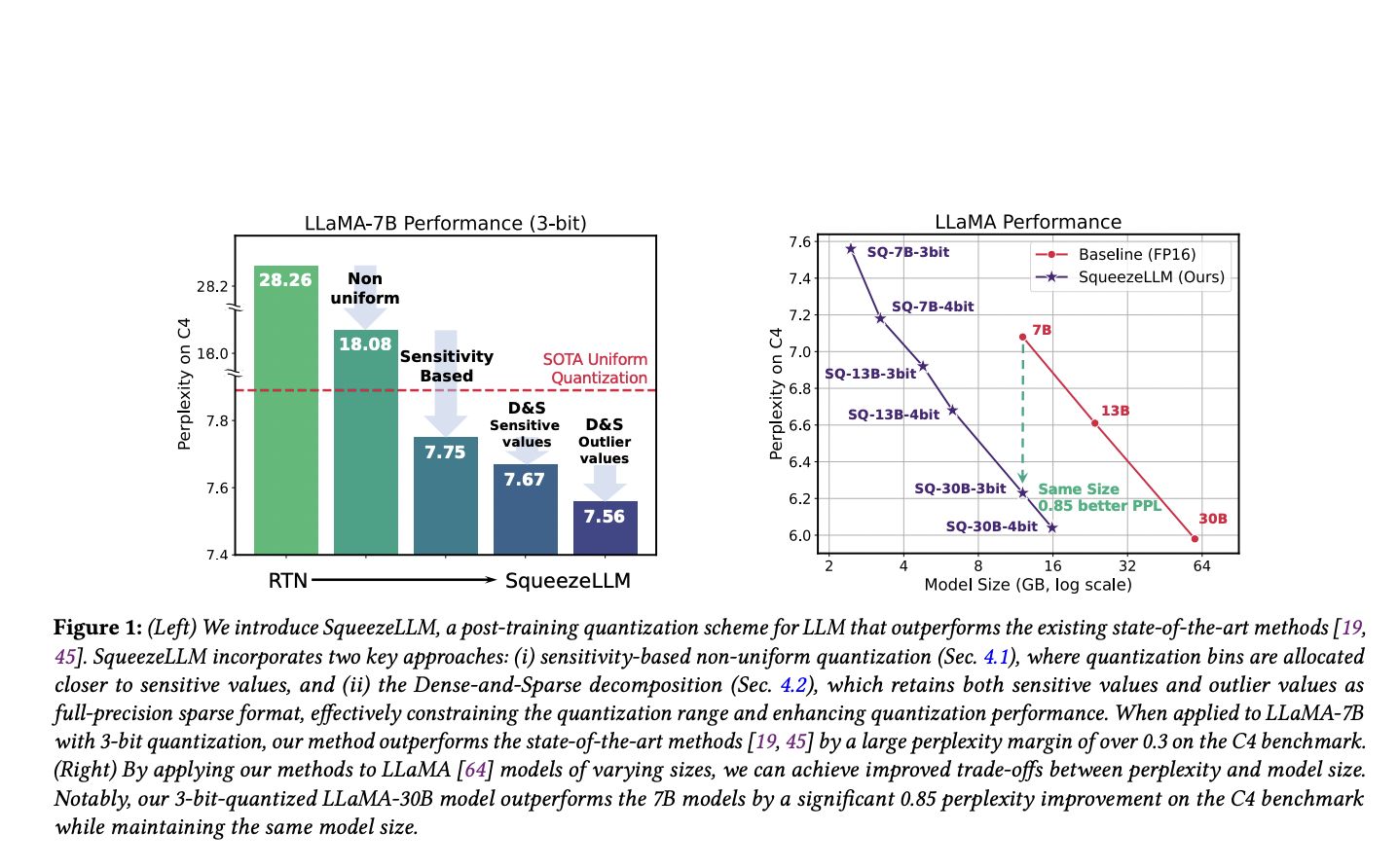
A brand new research from UC Berkeley investigates low-bit precision quantization in depth to disclose the shortcomings of present strategies. Primarily based on these findings, the researchers introduce SqueezeLLM, a post-training quantization framework that mixes a Dense-and-Sparse decomposition method with a novel sensitivity-based non-uniform quantization technique. These strategies allow quantization with ultra-low-bit precision whereas preserving aggressive mannequin efficiency, drastically slicing down on mannequin sizes and inference time prices. Their methodology reduces the LLaMA-7B mannequin’s perplexity at 3-bit precision from 28.26 with uniform quantization to 7.75 on the C4 dataset, which is a substantial enchancment.
By means of complete testing on the C4 and WikiText2 benchmarks, the researchers found that SqueezeLLM constantly outperforms present quantization approaches by a large margin throughout completely different bit precisions when utilized to LLaMA-7B, 13B, and 30B for language modeling duties.
In response to the crew, the low-bit precision quantization of many LLMs is especially troublesome as a result of substantial outliers within the weight matrices. These outliers likewise affect their non-uniform quantization method since they bias the allocation of bits towards extraordinarily excessive or low values. To remove the outlier values, they supply an easy methodology that splits the mannequin weights into dense and sparse parts. By isolating the intense values, the central area shows a narrower vary of as much as 10, leading to higher quantization precision. With environment friendly sparse storage strategies like Compressed Sparse Rows (CSR), the sparse knowledge will be stored in full precision. This methodology incurs low overhead by utilizing environment friendly sparse kernels for the sparse half and parallelizing the computation alongside the dense half.
The crew demonstrates their framework’s potential quantizing IF fashions by making use of SqueezeLLM to the Vicuna-7B and 13B fashions. They evaluate two programs of their checks. To start, they use the MMLU dataset, a multi-task benchmark that measures a mannequin’s data and problem-solving skills, to gauge the standard of the generated output. In addition they use GPT-4 to rank the era high quality of the quantized fashions relative to the FP16 baseline, utilizing the analysis methodology offered in Vicuna. In each benchmarks, SqueezeLLM often outperforms GPTQ and AWQ, two present state-of-the-art approaches. Notably, in each assessments, the 4-bit quantized mannequin performs simply in addition to the baseline.
The work reveals appreciable latency reductions and advances in quantization efficiency with their fashions operating on A6000 GPUs. The researchers reveal speedups of as much as 2.3 in comparison with the baseline FP16 inference for LLaMA-7B and 13B. Moreover, the proposed methodology achieves as much as 4x faster latency than GPTQ, demonstrating its efficacy in quantization efficiency and inference effectivity.
Verify Out The Paper and Github. Don’t neglect to hitch our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra. If in case you have any questions relating to the above article or if we missed something, be at liberty to electronic mail us at Asif@marktechpost.com
Featured Instruments From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Know-how(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in numerous fields. She is captivated with exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
