

[ad_1]
One large leap ahead in creating generalist fashions is the looks of Giant Language Fashions (LLMs). Their astounding textual content understanding and technology performances are sometimes primarily based on the Transformer structure and a single next-token prediction purpose. Nevertheless, they’re at the moment hampered by their incapacity to entry info outdoors the textual content. This emphasizes the requirement for dependable multimodal fashions able to performing varied duties utilizing varied modalities.
Latest efforts have sought to enhance process/modality-specific strategies by setting up multimodal fashions with extra energy. Just a few of those strategies search to incorporate greater than two modalities, similar to picture/video-text, though most of those efforts are dedicated to image-text jobs.
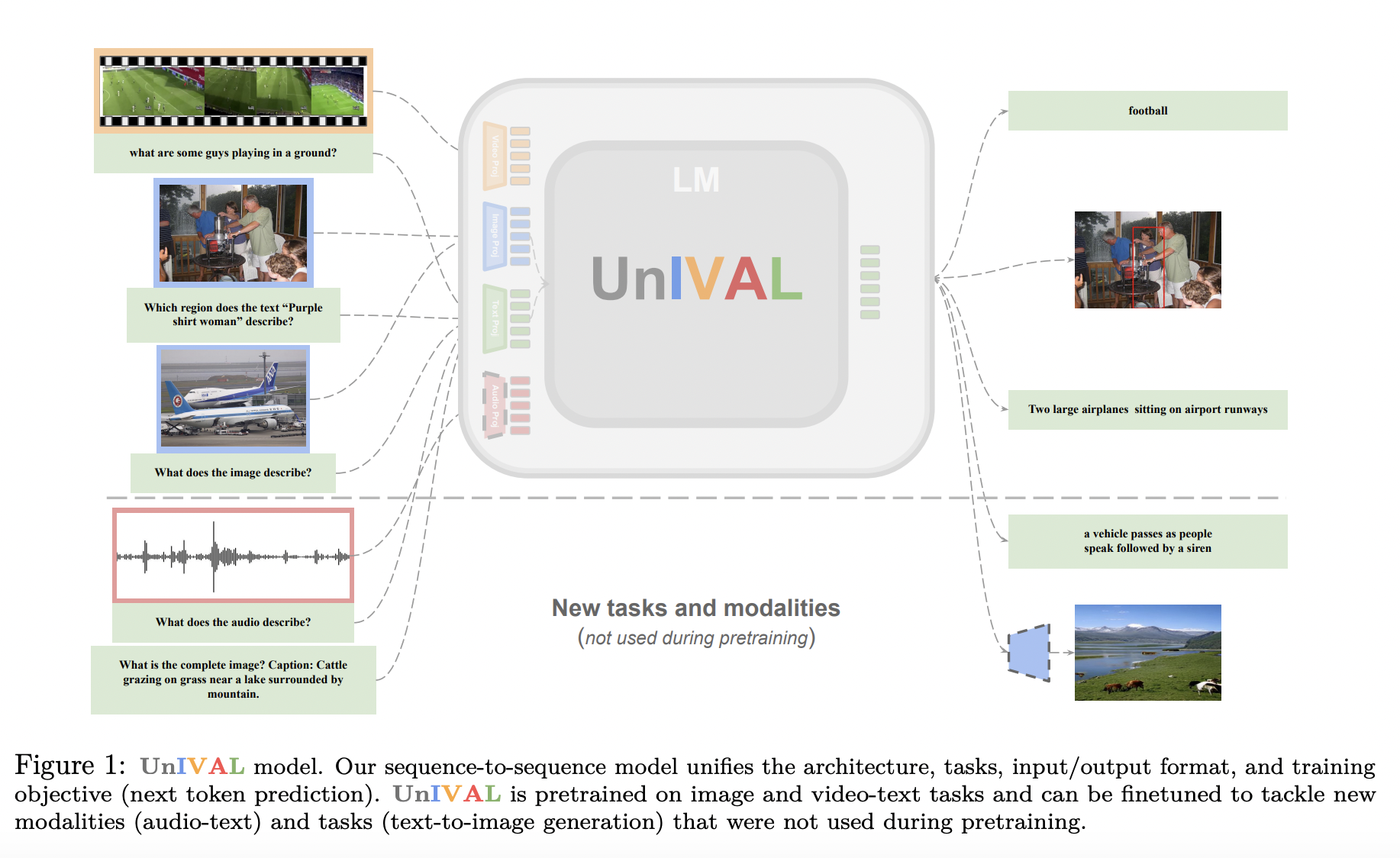
To handle this downside, the researchers at Sorbonne College started by creating general-purpose fashions that may deal with any downside. They introduce UnIVAL, a way that avoids counting on any single modality. UnIVAL integrates two modalities and all 4 (textual content, footage, video, and audio).
UnIVAL is the primary mannequin to unravel image, video, and audio language challenges with a unified structure, vocabulary, enter/output format, and coaching purpose with out requiring huge quantities of information for coaching or huge mannequin measurement. The 0.25 billion parameter mannequin delivers efficiency on par with prior artwork tailor-made to a sure modality. The researchers obtained new SoTA on a number of jobs with equally sized fashions.
Their analysis into the interaction and switch of data between pretrained duties and modalities demonstrates the worth of multitask pretraining in comparison with conventional single-task pretraining. In addition they uncover that pretraining the mannequin on extra modalities improves its generalization to untrained modalities. Particularly, when fine-tuned on audio-text issues, UnIVAL can obtain aggressive efficiency to SoTA with out audio pretraining.
Primarily based on earlier research, the workforce additionally presents a brand new investigation into merging multimodal fashions by weight interpolation. They display that interpolation within the weight house might efficiently mix the abilities of the a number of fine-tuned weights, creating extra strong multitask fashions with none inference overhead when utilizing the unified pretrained mannequin for varied multimodal duties. The range of multimodal actions can thus be used and recycled by averaging varied fine-tuned weights and multitasking pretraining. Weight interpolation has by no means been examined with multimodal baseline fashions earlier than, however this analysis is the primary to efficiently achieve this.
The researchers additionally point out two important drawbacks of UnIVAL:
- UnIVAL is vulnerable to hallucinations. Particularly, it could invent new objects in visible descriptions (object bias), giving extra weight to consistency than accuracy.
- It has bother following elaborate instructions. They discovered that the mannequin underperformed when given complicated directions, similar to selecting out one object from a bunch of comparable ones, discovering issues which are far-off or extraordinarily shut, or recognizing numbers.
The researchers hope their findings will inspire different scientists and velocity up the method of constructing new modality-agnostic generalist assistant brokers.
Take a look at the Project, Paper, and GitHub. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Dhanshree Shenwai is a Pc Science Engineer and has expertise in FinTech corporations protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in functions of AI. She is obsessed with exploring new applied sciences and developments in right now’s evolving world making everybody’s life straightforward.
[ad_2]
Source link
