


[ad_1]

Illustration by Creator | Supply: Flaticon.
Are you curious about mastering statistics for standing out in a knowledge science interview? If it’s sure, you shouldn’t do it just for the interview. Understanding Statistics may help you in getting deeper and extra effective grained insights out of your knowledge.
On this article, I’m going to point out probably the most essential statistics ideas that must be identified for getting higher at fixing knowledge science issues.
When you concentrate on Statistics, what’s your first thought? You could consider info expressed numerically, resembling frequencies, percentages and common. Simply wanting on the TV information and newspaper, you’ve got seen the inflation knowledge on the earth, the variety of employed and unemployed folks in your nation, the info about mortal incidents on the street and the chances of votes for every political occasion from a survey. All these examples are statistics.
The manufacturing of those statistics is probably the most evident utility of a self-discipline, known as Statistics. Statistics is a science involved with growing and learning strategies for accumulating, deciphering and presenting empirical knowledge. Furthermore, you may divide the sphere of Statistics into two totally different sectors: Descriptive Statistics and Inferential Statistics.
The yearly census, the frequency distributions, the graphs and the numerical summaries are a part of the Descriptive Statistics. For Inferential Statistics, we check with the set of strategies that permit to generalise outcomes primarily based on part of the inhabitants, known as Pattern.
In knowledge science tasks, we’re more often than not coping with samples. So, the outcomes we receive with machine studying fashions are approximated. A mannequin may match effectively on that exact pattern, however it doesn’t imply that it’s going to have good performances on a brand new pattern. All the things relies on our coaching pattern, that must be consultant, to generalise effectively the traits of the inhabitants.
Within the knowledge science undertaking, exploratory knowledge evaluation is an important step, which allows us to carry out preliminary investigations on the info with the assistance of abstract statistics and graphical representations. It additionally permits us to find patterns, spot anomalies and examine assumptions. Furthermore, it helps to search out errors that you could be discover in knowledge.
In EDA, the centre of the eye is on the variables, that may be of two sorts:
- numerical if the variable is measured on a numerical scale. It may be additional categorised into discrete and steady. It’s discrete when there are distinct portions. Examples of discrete variables are the diploma grade and the numbers of individuals in a household. After we are coping with a steady variable, the set of doable values is inside a finite or infinite interval, resembling the peak, the burden and the age.
- categorical if the variable is usually constituted by two or extra classes, just like the occupation standing (employed, unemployed and folks trying to find a job) and the kind of the job. Because the numerical variables, the explicit variables will be break up into two differing types: ordinal and nominal. A variable is ordinal when there’s a pure ordering of the classes. An instance will be the wage with low, medium and excessive ranges. When the explicit variable doesn’t comply with any order, it’s nominal. A easy instance of a nominal variable is the gender with ranges Feminine and Male.
EDA of Univariate Knowledge
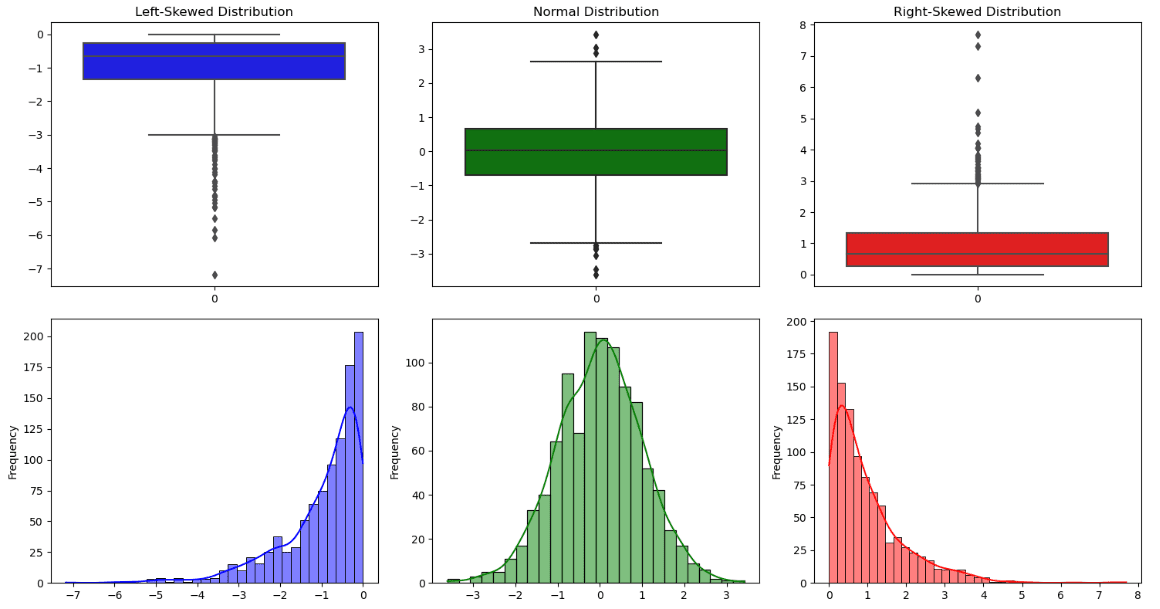
Distribution Form. Illustration by Creator.
To grasp the numerical options, we usually use df.describe() to have an summary of the statistics for every variable. The output comprises the rely, the common, the usual deviation, the minimal, the utmost, the median, the primary and the third quantile.
All this info will also be seen in a graphical illustration, known as boxplot. The road throughout the field is the median, whereas the decrease hinge and higher hinge correspond respectively to the primary and the third quartile. Along with the data offered by the field, there are two traces, additionally known as whiskers, that symbolize the 2 tails of the distribution. All the info factors exterior the boundary of the whiskers are outliers
From this plot, it will also be doable to look at if the distribution is symmetric or uneven:
- A distribution is symmetric when there’s a bell form, the median coincides roughly to the imply and the whiskers have the identical size.
- A distribution is skewed to the appropriate (optimistic skewed) if the median is close to the third quartile.
- A distribution is skewed to the left (unfavourable skewed) if the median is close to the primary quartile.
Different vital points of the distribution will be visualised from a histogram that counts what number of knowledge factors fall in every interval. It’s doable to note 4 forms of shapes:
- one peak/mode
- two peaks/modes
- three or extra peaks/modes
- uniform with no evident mode
When the variables are categorical, one of the simplest ways is to look at the frequency desk for every issue of the function. For a extra intuitive visualisation, we will make use of the bar chart, with vertical or horizontal bars relying on the variable.
EDA of Bivariate Knowledge
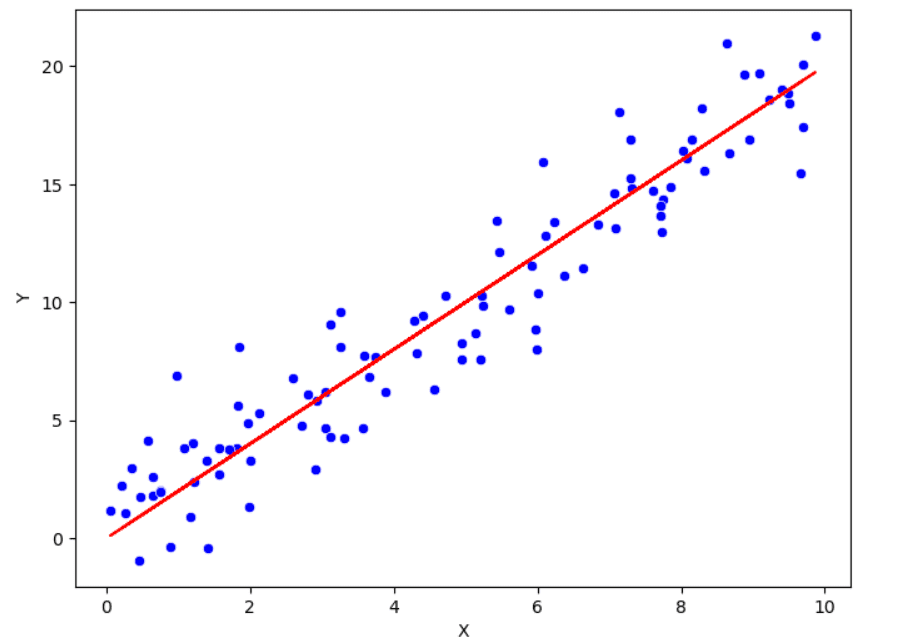
Scatterplot that reveals the optimistic linear relationship between x and y. Illustration by Creator.
Beforehand now we have listed the approaches to grasp the univariate distribution. Now, it’s time to review the relationships between the variables. For this function, it’s frequent to calculate Pearson correlation, which is a measure of the linear relationship between two variables. The vary of this correlation coefficient is inside -1 and 1. The extra the worth of the correlation is close to to one in all these two extremes, the extra the connection is robust. If it’s close to to 0, there’s a weak relationship between the 2 variables.
Along with the correlation, there’s the scatter plot to visualise the connection between two variables. On this graphical illustration, every level corresponds to a particular statement. It’s usually not very informative when there’s a variety of variability throughout the knowledge. To seize extra info from the pair of variables is by including smoothed traces and remodeling the info.
The information of Likelihood distributions could make the distinction when working with knowledge.
These are probably the most used chance distributions in knowledge science:
- Regular distribution
- Chi-squared distribution
- Uniform distribution
- Poisson distribution
- Exponential distribution
Regular distribution
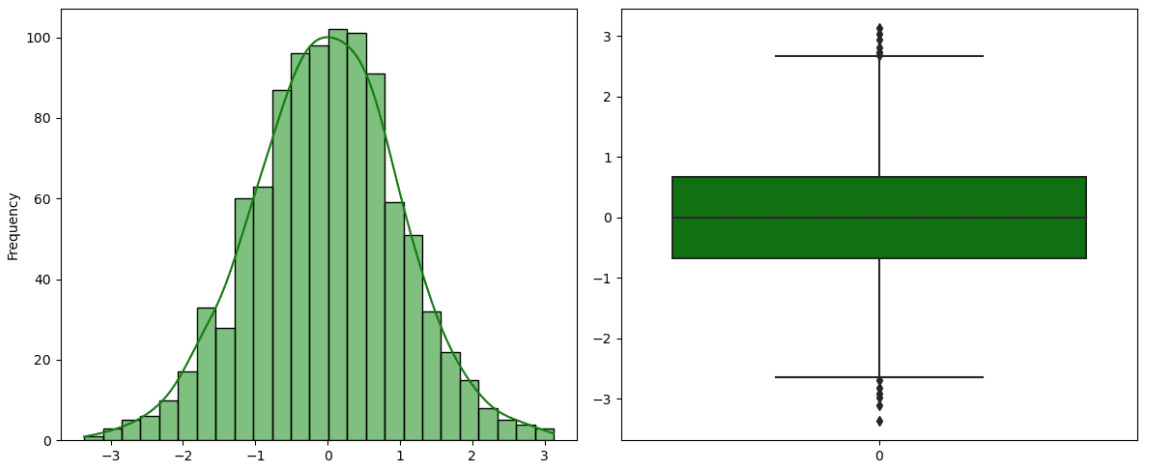
Instance of Regular distribution. Illustration by Creator.
The traditional distribution, also referred to as Gaussian Distribution, is the most well-liked distribution in statistics. It’s characterised by a bell curve for its specific form, tall within the center and tails in direction of the top. It’s symmetric and unimodal with a peak. Furthermore, there are two parameters which have a vital function in regular distribution: the imply and the usual deviation. The imply coincides with the height, whereas the width of the curve is represented by the usual deviation. There’s a specific sort of Regular distribution, known as Commonplace Regular Distribution, with imply equal to 0 and variance equal to 1. It’s obtained by subtracting the imply from the unique worth and, then, dividing by the usual deviation.
Scholar’s t Distribution
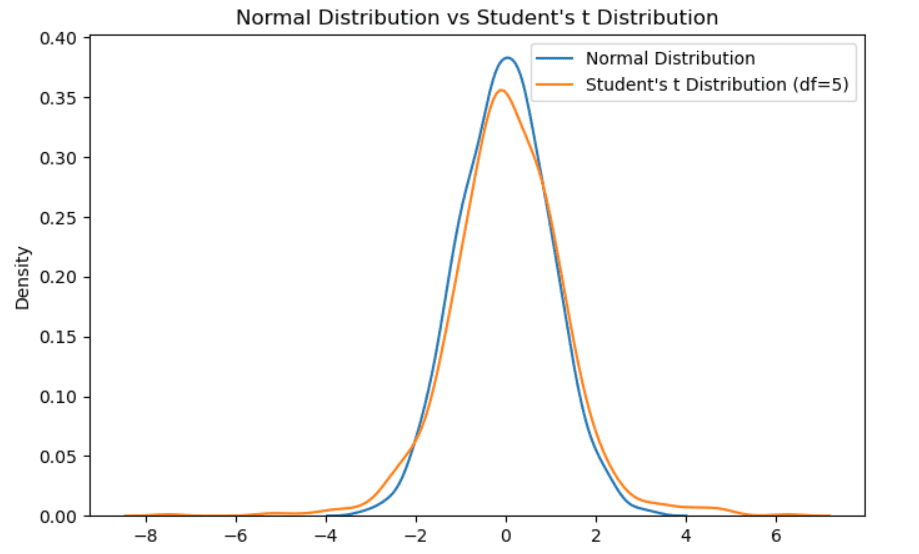
Instance of Scholar’s t distribution. Illustration by Creator.
Additionally it is known as t-distribution with v levels of freedom. Like the usual regular distribution, it’s unimodal and symmetric round zero. It barely differs from the gaussian distribution as a result of it has much less mass within the center and there are extra plenty within the tails. It’s thought of when now we have a small pattern dimension. The extra the pattern dimension will increase, the extra the t-distribution will converge to a standard distribution.
Chi-squared distribution
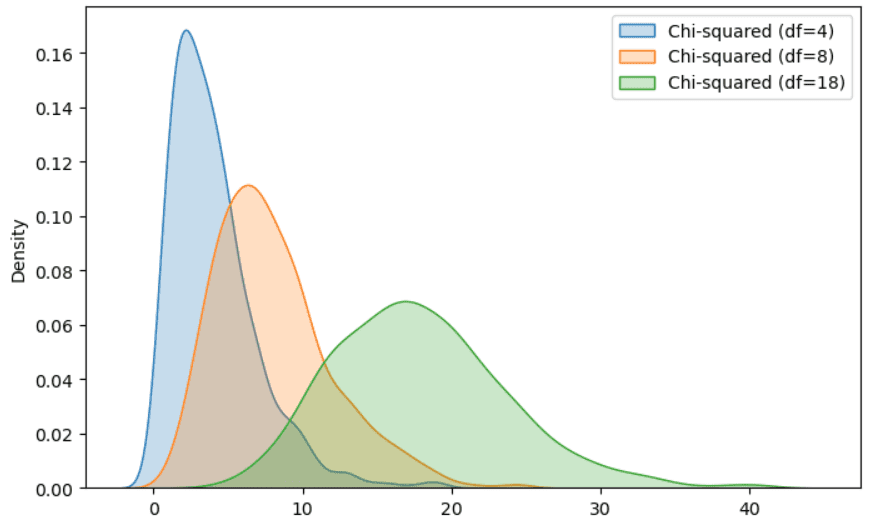
Instance of Chi-squared distribution. Illustration by Creator.
It’s a particular case of Gamma distribution, very identified for its functions in speculation testing and confidence intervals. If now we have a set of usually distributed and impartial random variables, we compute the sq. worth for every random variable and we sum each squared worth, the ultimate random worth follows a chi-squared distribution.
Uniform distribution
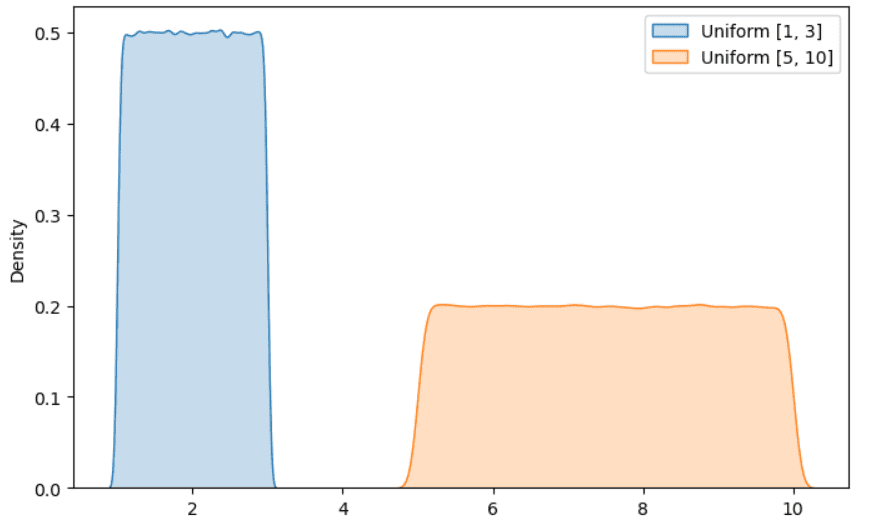
Instance of Uniform distribution. Illustration by Creator.
It’s one other common distribution that you’ve got certainly met when engaged on a knowledge science undertaking. The concept is that every one the outcomes have an equal chance of occurring. A preferred instance consists in rolling a six-faced die. As it’s possible you’ll know, every face of the die has an equal chance of occuring, then the result follows an uniform distribution.
Poisson distribution
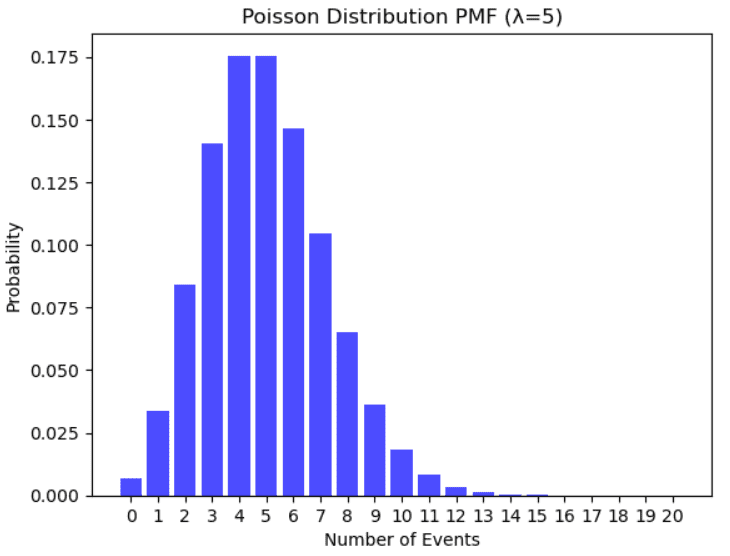
Instance of Poisson distribution. Illustration by Creator.
It’s used to mannequin the variety of occasions that happen randomly many instances inside a particular time interval. Examples that comply with a Poisson distribution are the variety of folks in a group which can be older than 100 years, the variety of failures per day of a system, the variety of cellphone calls arriving on the helpline in a particular timeframe.
Exponential distribution
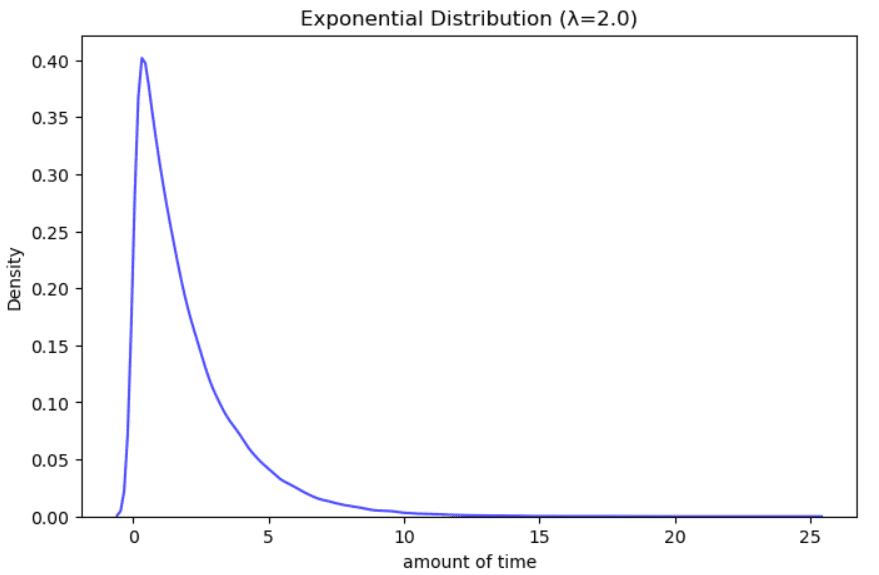
Instance of Exponential distribution. Illustration by Creator.
It’s used to mannequin the period of time between occasions that happen randomly many instances inside a particular time interval. Examples will be the time on maintain at a helpline, the time till the subsequent earthquake, the remaining years of life for a most cancers affected person.
The speculation testing is a statistical methodology that permits to formulate and consider an speculation in regards to the inhabitants primarily based on pattern knowledge. So, it’s a type of inferential statistics. This course of begins with a speculation of the inhabitants parameters, additionally known as null speculation, that must be examined, whereas the choice speculation (H1) represents the other assertion. If the info may be very totally different from the assumptions we had, then the null speculation (H0) is rejected and the result is alleged to be “statistically important”.
As soon as the 2 speculation are specified, there are different steps to comply with:
- Arrange the significance stage, which is a standards used for rejecting the null speculation. The everyday values are 0.05 and 0.01. This parameter ? determines how robust the empirical proof is towards the null speculation till this latter is rejected.
- Calculate the statistic, which is the numerical amount computed from the pattern. It helps us to find out a rule of choice to restrict as a lot as doable the chance of error.
- Compute the p-value, which is the chance of acquiring a statistic that’s totally different from the parameter specified within the null speculation. If it’s much less or equal to the importance stage (ex: 0.05), we reject the null speculation. In case the p-value is greater than the importance stage, we will’t reject the null speculation.
There’s a large number of speculation assessments. Let’s suppose that we’re engaged on a knowledge science undertaking and we wish to use the linear regression mannequin, which is thought for having robust assumptions of normality, independence and linearity. Earlier than making use of the statistical mannequin, we desire to examine the normality of a function that regards the burden of grownup ladies with diabete. The Shapiro-Wilk take a look at can come to our rescue. There’s additionally a Python library, known as Scipy, with the implementation of this test, through which the null speculation is that the variable follows a standard distribution. We reject the speculation if the p-value is smaller or equal to the importance stage (ex: 0.05). We are able to settle for the null speculation, which signifies that the variable has a standard distribution, if the p-value is larger than the importance stage.
I hope you’ve got discovered this introduction helpful. I feel that mastering statistics is feasible if idea is adopted by sensible examples. There are certainly different vital statistics ideas I didn’t cowl right here, however I most well-liked to deal with ideas that I’ve discovered helpful throughout my expertise as a knowledge scientist. Have you learnt different statistical strategies that helped you together with your work? Drop them within the feedback when you have insightful options.
Assets:
Eugenia Anello is at the moment a analysis fellow on the Division of Info Engineering of the College of Padova, Italy. Her analysis undertaking is targeted on Continuous Studying mixed with Anomaly Detection.
[ad_2]
Source link
