

[ad_1]
The sphere of analysis in pose-guided particular person picture synthesis has made vital progress lately, specializing in producing pictures of an individual with the identical look however beneath a distinct pose. This know-how has broad purposes in e-commerce content material era and might enhance downstream duties like particular person re-identification. Nevertheless, it faces a number of challenges, primarily on account of inconsistencies between the supply and goal poses.
Researchers have explored varied GAN-based, VAE-based, and flow-based strategies to deal with pose-guided particular person picture synthesis challenges. GAN-based approaches require secure coaching and should produce unrealistic outcomes. VAE-based strategies could blur particulars and misalign poses, whereas flow-based fashions can introduce artifacts. Some strategies use parsing maps however battle with type and texture. Diffusion fashions present promise however face challenges associated to pose inconsistencies, which should be addressed for improved outcomes.
To deal with these points, a just lately printed paper introduces Progressive Conditional Diffusion Fashions (PCDMs), which progressively generate high-quality pictures in three levels: predicting world options, establishing dense correspondences, and refining pictures for higher texture and element consistency.
The proposed methodology gives vital contributions in pose-guided particular person picture synthesis. It introduces a easy prior conditional diffusion mannequin that generates world goal picture options by revealing the alignment between supply picture look and goal pose coordinates. An revolutionary inpainting conditional diffusion mannequin establishes dense correspondences, remodeling unaligned image-to-image era into an aligned course of. Moreover, a refining conditional diffusion mannequin enhances picture high quality and constancy.
(PCDMs) include three key levels, every contributing to the general picture synthesis course of:
2) Prior Conditional Diffusion Mannequin: Within the first stage, the mannequin predicts the worldwide options of the goal picture by leveraging the alignment relationship between pose coordinates and picture look. The mannequin makes use of a transformer community conditioned on the pose of the supply and goal pictures and the supply picture. The worldwide picture embedding, obtained from CLIP picture encoder, guides the goal picture synthesis. The loss operate for this stage encourages the mannequin to foretell the un-noised picture embedding instantly. This stage bridges the hole between the supply and goal pictures on the function stage.
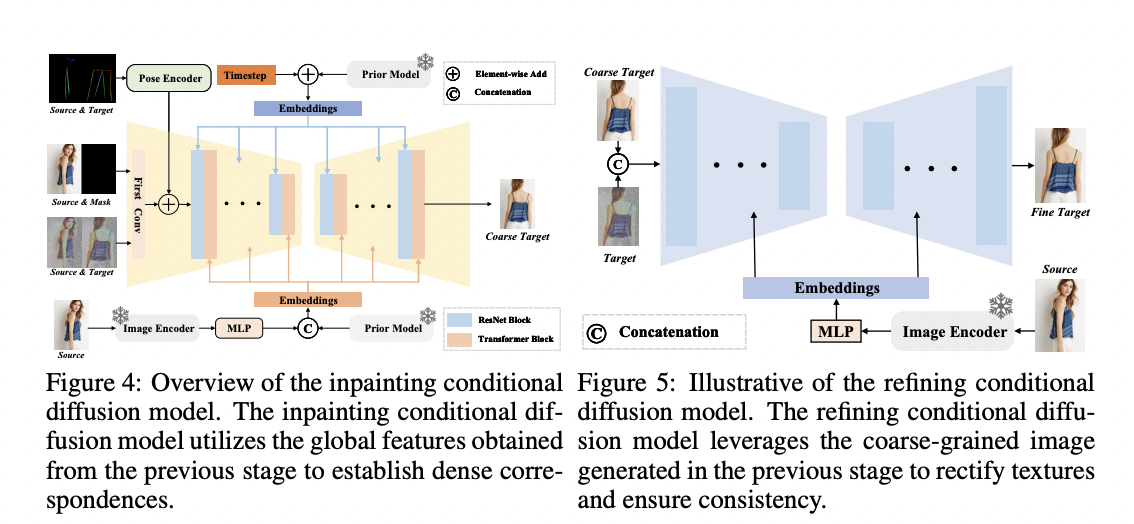
2) Inpainting Conditional Diffusion Mannequin: The inpainting conditional diffusion mannequin is launched within the second stage. It leverages the worldwide options obtained within the prior stage to determine dense correspondences between the supply and goal pictures, successfully remodeling the unaligned image-to-image era job into an aligned one. This stage ensures that the supply and goal pictures and their respective poses are aligned at a number of ranges, together with picture, pose, and have. It goals to enhance the alignment between supply and goal pictures and is essential for producing sensible outcomes.
3) Refining Conditional Diffusion Mannequin: After producing a preliminary coarse-grained goal picture within the earlier stage, the refining conditional diffusion mannequin enhances picture high quality and element texture. This stage makes use of the coarse-grained picture generated over the past stage as a situation to enhance picture constancy and texture consistency additional. It includes modifying the primary convolutional layer and utilizing a picture encoder to extract options from the supply picture. The cross-attention mechanism infuses texture options into the community for texture restore and element enhancement.
The strategy is validated by means of complete experiments on public datasets, demonstrating aggressive efficiency by way of quantitative metrics (SSIM, LPIPS, FID). A consumer research additional validated the tactic’s effectiveness. An ablation research examined the impression of particular person levels of the PCDMs, highlighting their significance. Lastly, the applicability of PCDMs in particular person re-identification was demonstrated, showcasing improved re-identification efficiency in comparison with baseline strategies.
In conclusion, PCDMs current a notable breakthrough in pose-guided particular person picture synthesis. Utilizing a multi-stage strategy, PCDMs successfully handle alignment and pose consistency points, producing high-quality, sensible pictures. The experiments showcase their superior efficiency in quantitative metrics and consumer research, and their applicability to particular person re-identification duties additional highlights their sensible utility. PCDMs supply a promising answer for a variety of purposes, advancing the sphere of pose-guided picture synthesis.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Mahmoud is a PhD researcher in machine studying. He additionally holds a
bachelor’s diploma in bodily science and a grasp’s diploma in
telecommunications and networking programs. His present areas of
analysis concern pc imaginative and prescient, inventory market prediction and deep
studying. He produced a number of scientific articles about particular person re-
identification and the research of the robustness and stability of deep
networks.
[ad_2]
Source link
