


[ad_1]

Picture by writer
TF-IDF. You’re most likely learn blogs and seen this phrase being thrown right here and there. Otherwise you’re most likely at the moment studying about it in Machine Studying. This text is an outline of what TF-IDF is.
TF-IDF stands for time period frequency-inverse doc frequency.
TF-IDF is usually used within the machine studying world and knowledge retrieval.
TF-IDF is a numerical statistic that measures the significance of string representations akin to phrases, phrases and extra in a corpus (doc).
Let’s break the abbreviation up and go into additional understanding.
In relation to the artwork of language or Pure Language Processing in machine studying, a corpus is a set of textual content or audio which has been organized right into a dataset.

Sarah Mae through Unsplash
Let’s take this image of this poem on a chunk of paper for instance. The corpus of this poem in a code format would appear to be this:
corpus = [
"Little feet.",
"A tempered foot,",
"found new ground.",
"A future unravled,",
"in the gypsy's palm.",
"A blade of grass",
"reflected in a crystal ball,",
"somehow fit the mold.",
"This daughter was leaving home.",
"A dark hair twitched, upon the mole.",
"From maiden to mother to crone",
"the moon takes us,",
"each month",
"a new spell.",
"an untold dimension.",
"Flattery fell in the folding of wings,",
"an angel over a city,",
"an orb, over the sea.",
"somehow, Seattle spoke to me."
]
That is the mathematical equation to outline TF IDF:
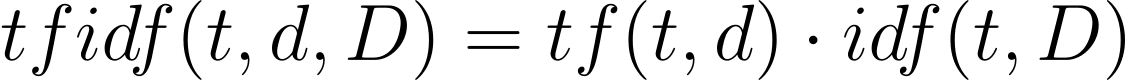
- t stands for time period
- d stands for doc
- D stands for set of paperwork
TF is time period frequency. It measures precisely what it says – the frequency of a selected time period. The variety of instances a selected time period is obtainable in a corpus can assist us to measure the significance of that string.
You possibly can measure the frequency within the following methods:
- Uncooked depend – You may do a uncooked depend by counting manually what number of instances a phrase seems within the corpus.
- Boolean frequency – a Boolean information sort is when there are two potential values – true/false, sure/no, 0/1. You should utilize 1 if the time period happens or 0 if the time period doesn’t happen
- Logarithmic scale – through the use of and displaying numerical information over a variety of values.
Mathematical equation for TF:
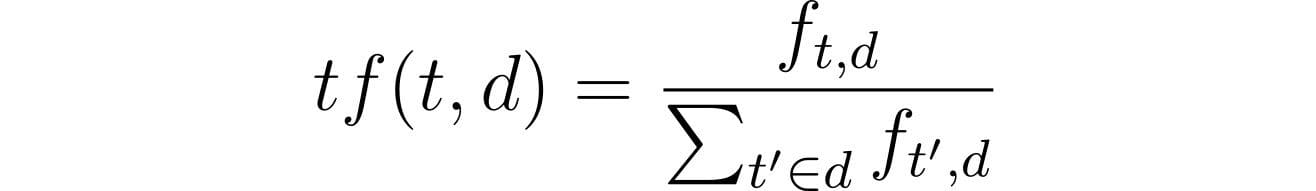
- t stands for time period
- f stands for frequency
- d stands for doc
IDF is inverse doc frequency. This goes additional into how widespread a phrase is present in a corpus – or how unusual a phrase is present in a corpus.
IDF is essential. Let’s take the English language for instance, phrases akin to “the”, “it”, “as”, “or” which seem incessantly in lots of varieties of paperwork. Inverse doc frequency basically minimizes the burden of frequency phrases akin to these and places phrases which aren’t as frequent on the forefront to have the next impression.
Mathematical equation for IDF:
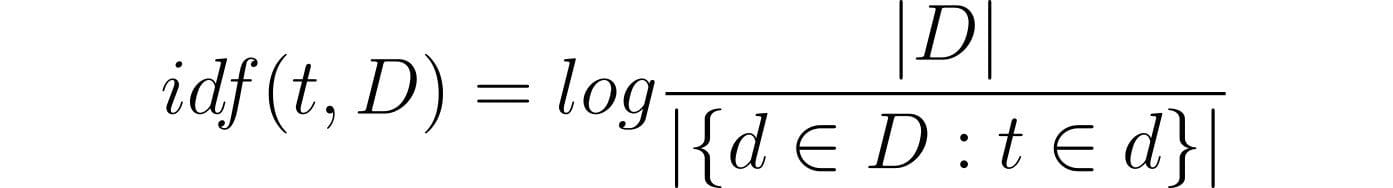
- t stands for time period
- d stands for doc
- D stands for set of paperwork
For IDF, you’re most likely asking these questions:
1. Why can we take the inverse?
It’s because we wish to give the phrases which are unusual the next worth compared to the phrases which are far more widespread.. If we didn’t take the inverses, widespread phrases akin to “the” would have the next worth and we’d by no means actually discover which phrases within the corpus maintain significance.
2. Why can we use logarithmic scale?
It is very important word that we’re not specializing in the prevalence of a time period in a corpus, it’s the relevance and/or significance of that time period within the corpus. Including to the time period frequency is actually a sub-linear perform, subsequently utilizing the logarithmic scale permits us to place these phrases in the identical scale or sub-linear perform because the time period frequency.
Strategies within the Pure Language Processing world have been creating, and though TF IDF was first acknowledged within the 1970’s – it nonetheless holds relevance in 2022.
TF-IDF sounds easy compared to NLP methods and instruments which are getting used at present. However simply because it’s easy doesn’t imply that it doesn’t maintain worth and does what it must do. TD-IDF can be utilized to higher perceive and interpret the outputs of algorithms which were used on high of TF-IDF. There’s no hurt in utilizing a couple of measure.
TF-IDF has additionally been recognized to unravel main drawbacks from standard language processing methods akin to of Bag of phrases
Oh, and another excuse: it’s fast, simple, and accessible.
TF-IDF is a superb place to begin relating to language processing duties, from constructing search engines like google to info retrieval. Though it’s a easy measure, it nonetheless holds its intuitive method to measuring the burden and relevance of phrases in a corpus.
Nisha Arya is a Information Scientist and Freelance Technical Author. She is especially inquisitive about offering Information Science profession recommendation or tutorials and principle based mostly data round Information Science. She additionally needs to discover the alternative ways Synthetic Intelligence is/can profit the longevity of human life. A eager learner, in search of to broaden her tech data and writing abilities, while serving to information others.
[ad_2]
Source link
