

[ad_1]
Massive Language Fashions (LLMs) have exhibited exceptional prowess throughout numerous pure language processing duties. Nonetheless, making use of them to Info Retrieval (IR) duties stays a problem as a result of shortage of IR-specific ideas in pure language. Addressing this, the thought of instruction tuning has emerged as a pivotal methodology to raise LLMs’ capabilities and management. Whereas instruction fine-tuned LLMs have excelled in generalizing to new duties, a spot exists of their software to IR duties.

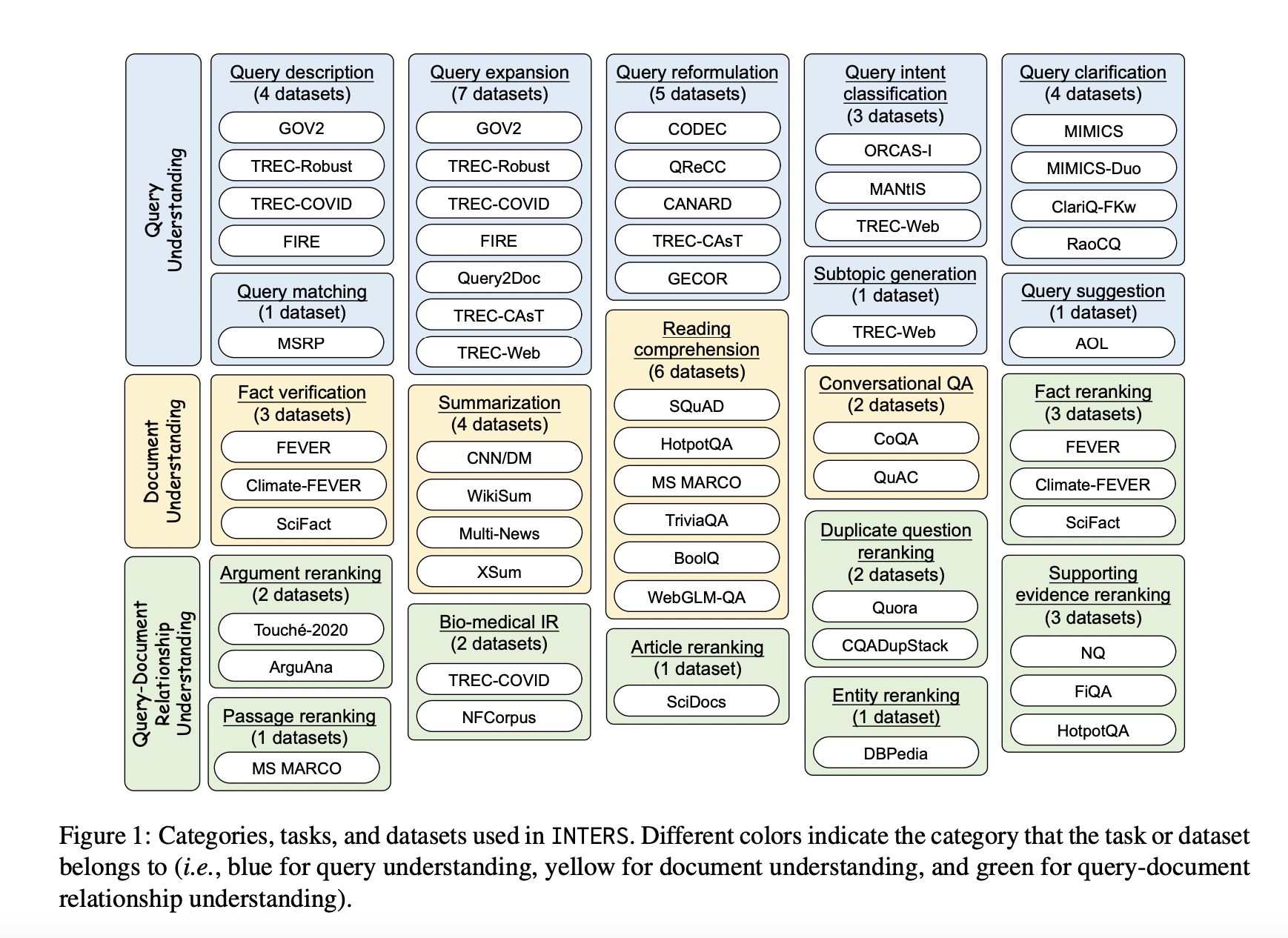
In response, this work introduces a novel dataset, INTERS (INstruction Tuning datasEt foR Search), meticulously designed to reinforce the search capabilities of LLMs. This dataset focuses on three pivotal facets prevalent in search-related duties: question understanding, doc understanding, and the intricate relationship between queries and paperwork. INTERS is a complete useful resource encompassing 43 datasets protecting 20 distinct search-related duties.
The idea of Instruction Tuning includes fine-tuning pre-trained LLMs on formatted situations represented in pure language. It stands out by not solely enhancing efficiency on instantly educated duties but additionally enabling LLMs to generalize to new, unseen duties. Within the context of search duties, distinct from typical NLP duties, the main target revolves round queries and paperwork. This distinction prompts the categorization of duties into question understanding, doc understanding, and query-document relationship understanding.
Duties & Datasets:
Growing a complete instruction-tuning dataset for a variety of duties is resource-intensive. To bypass this, present datasets from the IR analysis neighborhood are transformed into an educational format. Classes embrace (proven in Determine 1):
– Question Understanding: Addresses facets akin to question description, enlargement, reformulation, intent classification, clarification, matching, subtopic technology, and suggestion.
– Doc Understanding: Encompasses truth verification, summarization, studying comprehension, and conversational question-answering.
– Question-Doc Relationship Understanding: Primarily focuses on the doc reranking activity.
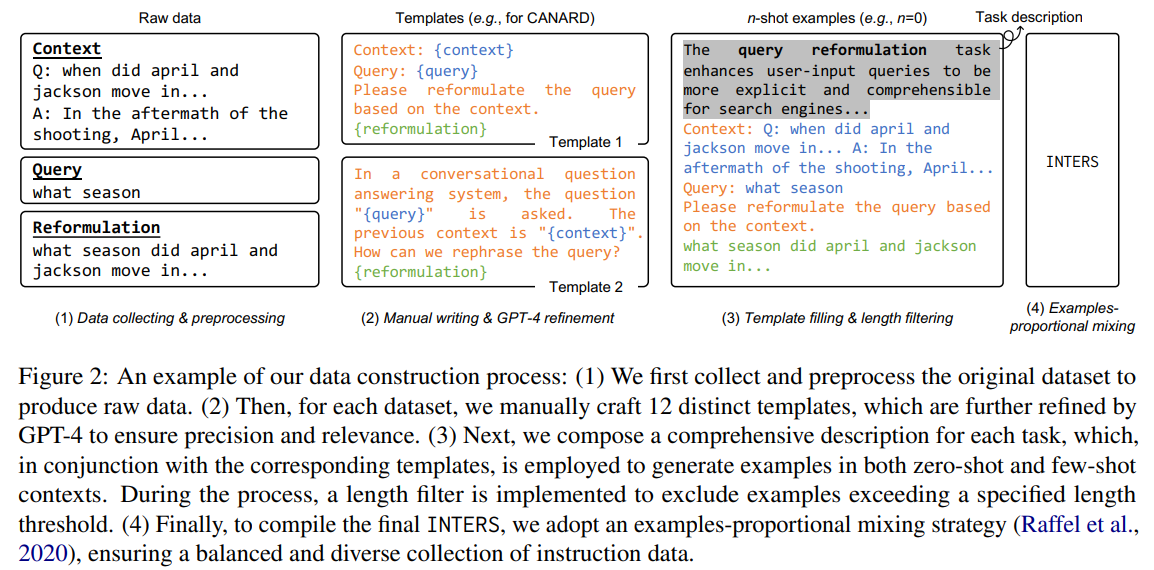
The development of INTERS (proven in Determine 2) is a meticulous course of involving the handbook crafting of activity descriptions and templates and becoming information samples into these templates. It displays the dedication to making a complete and instructive dataset.
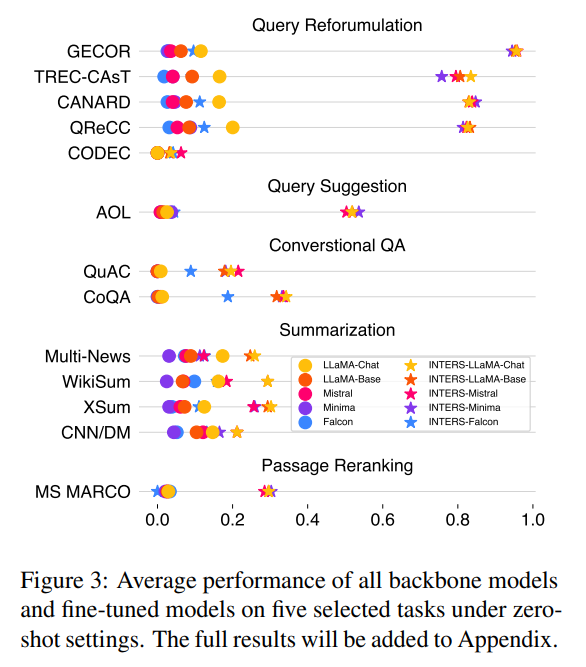
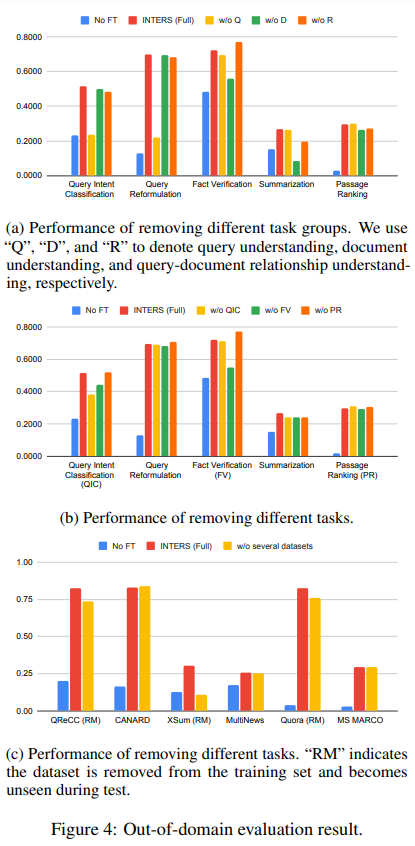
For analysis, 4 LLMs of various sizes are employed: Falcon-RW-1B, Minima-2-3B, Mistral-7B, and LLaMA-2-7B. In an in-domain analysis (outcomes proven in Determine 3), the place all duties and datasets are uncovered throughout coaching, the effectiveness of instruction tuning on search duties is validated. Past in-domain analysis (outcomes are proven in Determine 4), the authors examine the generalizability of fine-tuned fashions to new, unseen duties. Group-level, Activity-level, and Dataset-level generalizability are explored, offering insights into the adaptability of instruction-tuned LLMs.
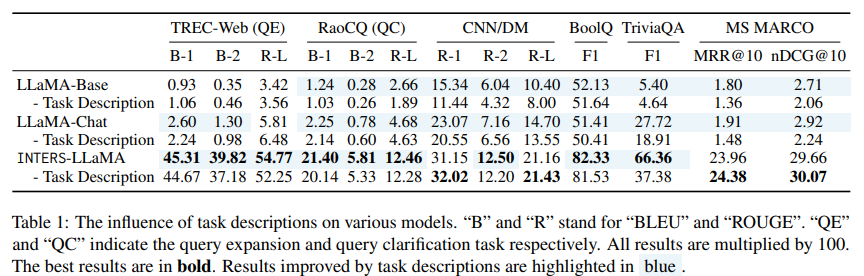
A number of experiments goal to grasp the affect of various settings inside INTERS. Notably, the removing of activity descriptions (outcomes current in Desk 1) from the dataset considerably impacts mannequin efficiency, highlighting the significance of clear activity comprehension.
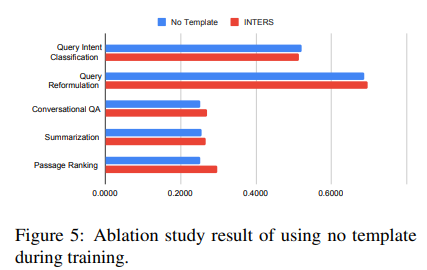
Templates and guiding fashions in activity comprehension are important parts of INTERS. Ablation experiments (as in Determine 5) showcase that using educational templates considerably improves mannequin efficiency.
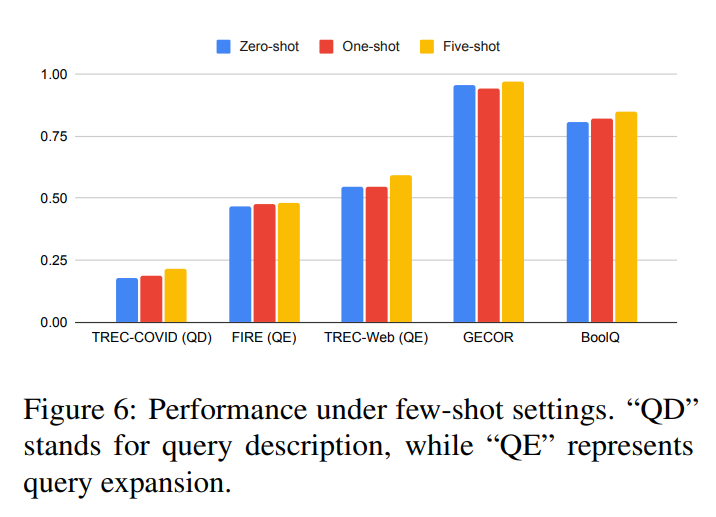
Given INTERS’s mixture of zero-shot and few-shot examples, analyzing few-shot efficiency is essential. Testing datasets inside fashions’ enter size limits demonstrates (proven in Determine 6) the dataset’s effectiveness in facilitating few-shot studying.
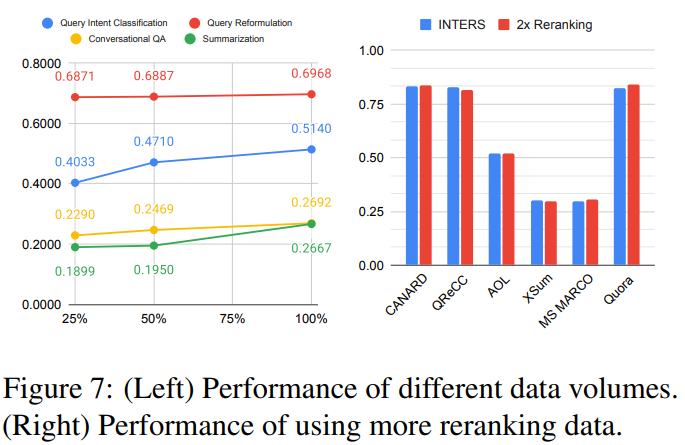
The amount of coaching information is explored, with experiments (outcomes proven in Determine 7) indicating that rising the quantity of educational information typically enhances mannequin efficiency, albeit with various sensitivity throughout duties.
In abstract, this paper presents an exploration of instruction tuning for LLMs utilized to look duties, culminating within the creation of the INTERS dataset. The dataset proves efficient in constantly enhancing LLMs’ efficiency throughout numerous settings. The analysis delves into important facets, shedding gentle on the construction of directions, the affect of few-shot studying, and the importance of information volumes in instruction tuning. The hope is that this work catalyzes additional analysis within the area of LLMs, notably of their software to IR duties, encouraging ongoing optimization of instruction-based strategies to reinforce mannequin efficiency.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to affix our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the most recent developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.
[ad_2]
Source link
