


[ad_1]
Within the swiftly evolving area of pc imaginative and prescient, the breakthrough in reworking a single picture right into a 3D object construction is a beacon of innovation. This expertise, pivotal in purposes like novel view synthesis and robotic imaginative and prescient, grapples with a big problem: reconstructing 3D objects from restricted views, significantly from a single viewpoint. The duty is inherently complicated because of the want for extra details about unseen features of the thing.
Traditionally, neural 3D reconstruction strategies relied on a number of pictures, requiring constant views, appearances, and correct digicam parameters. Regardless of their efficacy, these strategies are constrained by their want for in depth knowledge and particular digicam positioning, making them much less adaptable to various real-world situations the place such detailed enter is probably not accessible.
Developments in generative fashions, particularly diffusion fashions, have proven promise in mitigating these challenges by performing as a powerful base for unseen views, aiding the 3D reconstruction course of. Nonetheless, these strategies nonetheless necessitate per-scene optimization, which is time-intensive and limits sensible utility.
To handle these limitations, a way referred to as Hyper-VolTran has been launched by researchers from Meta AI. This method integrates the strengths of HyperNetworks with a Quantity Transformer (VolTran) module, considerably diminishing the necessity for per-scene optimization and enabling extra fast and environment friendly 3D reconstruction. The method begins by producing multi-view pictures from a single enter, that are then used to assemble neural encoding volumes. These volumes help in precisely modeling the 3D geometry of the thing.
HyperNetworks dynamically assigns weights to the Signed Distance Perform (SDF) community, enhancing adaptability to new scenes. The SDF community is essential for precisely representing 3D surfaces. The Quantity Transformer module aggregates picture options from a number of viewpoints, bettering consistency and high quality within the 3D reconstruction.
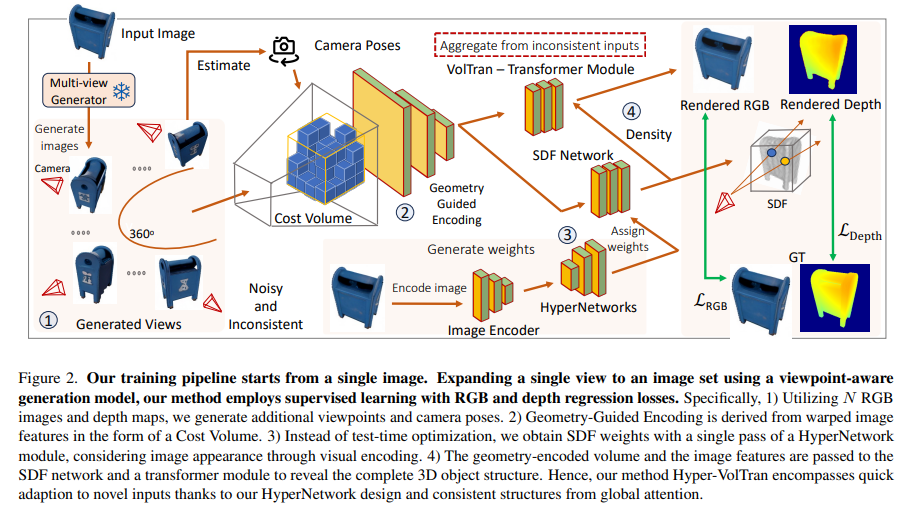
Hyper-VolTran excels in generalizing to unseen objects, delivering constant and fast outcomes. This technique marks a big advance in neural 3D reconstruction, providing a sensible and environment friendly resolution for creating 3D fashions from single pictures. It opens new avenues in numerous purposes, making it a helpful software for future improvements in pc imaginative and prescient and associated fields.
In conclusion, the important thing takeaways of Hyper-VolTran embody:
- Revolutionary HyperNetworks and Quantity Transformer module mixture for environment friendly 3D reconstruction from single pictures.
- The necessity for per-scene optimization considerably reduces, resulting in quicker and extra sensible purposes.
- Profitable generalization to new objects, showcasing versatility and adaptableness.
- Enhanced high quality and consistency in 3D fashions facilitated by aggregating options from synthesized multi-view pictures.
- Potential for broad software in numerous fields, paving the way in which for additional developments in pc imaginative and prescient expertise.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to affix our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Hi there, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about expertise and wish to create new merchandise that make a distinction.
[ad_2]
Source link
