


[ad_1]
Language-guided video segmentation is a creating area that focuses on segmenting and monitoring particular objects in movies utilizing pure language descriptions. Present datasets for referring to video objects normally emphasise distinguished objects and depend on language expressions with many static attributes. These attributes permit for figuring out the goal object in only one body. Nevertheless, these datasets overlook the importance of movement in language-guided video object segmentation.

Researchers have launched MeVIS, a brand new large-scale dataset known as Movement Expression Video Segmentation (MeViS), to help our investigation. The MeViS dataset includes 2,006 movies with 8,171 objects, and 28,570 movement expressions are supplied to refer to those objects. The above photos show the expressions in MeViS that primarily concentrate on movement attributes, and the referred goal object can’t be recognized by analyzing a single body solely. As an example, the primary instance options three parrots with comparable appearances, and the goal object is recognized as “The chook flying away.” This object can solely be acknowledged by capturing its movement all through the video.
Just a few steps make sure that the MeVIS dataset emphasizes the temporal motions of the movies.
First, video content material is chosen rigorously that incorporates a number of objects that coexist with movement and excludes movies with remoted objects that static attributes can simply describe.
Second, language expressions are prioritized that don’t include static clues, akin to class names or object colours, in instances the place goal objects could be unambiguously described by movement phrases alone.
Along with proposing the MeViS dataset, researchers additionally current a baseline method, named Language-guided Movement Notion and Matching (LMPM), to handle the challenges posed by this dataset. Their method includes the era of language-conditioned queries to establish potential goal objects inside the video. These objects are then represented utilizing object embeddings, that are extra sturdy and computationally environment friendly in comparison with object function maps. The researchers apply Movement Notion to those object embeddings to seize the temporal context and set up a holistic understanding of the video’s movement dynamics. This permits their mannequin to know each momentary and extended motions current within the video.
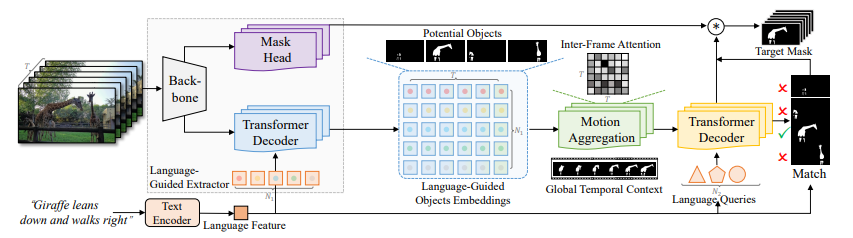
The above picture shows the structure of LMLP. They use a Transformer decoder to interpret language from mixed object embeddings affected by movement. This helps predict object actions. Then, they evaluate language options with projected object actions to search out the goal object(s) talked about within the expressions. This revolutionary methodology merges language understanding and movement evaluation to deal with the advanced dataset process successfully.
This analysis has supplied a basis for creating extra superior language-guided video segmentation algorithms. It has opened up avenues in more difficult instructions, akin to:
- Exploring new strategies for higher movement understanding and modeling in visible and linguistic modalities.
- Creating extra environment friendly fashions that scale back the variety of redundant detected objects.
- Designing efficient cross-modal fusion strategies to leverage the complementary data between language and visible indicators.
- Creating superior fashions that may deal with advanced scenes with varied objects and expressions.
Addressing these challenges requires analysis to propel the present state-of-the-art within the area of language-guided video segmentation ahead.
Take a look at the Paper, Github, and Project. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
In case you like our work, please observe us on Twitter
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
[ad_2]
Source link
