


[ad_1]
Lately, machine studying has considerably shifted away from the idea that coaching and testing knowledge come from the identical distribution. Researchers have recognized that fashions carry out higher when dealing with knowledge from a number of distributions. This adaptability is usually achieved by way of what’s generally known as “wealthy representations,” which exceed the capabilities of fashions skilled underneath conventional sparsity-inducing regularization or frequent stochastic gradient strategies.
The problem is optimizing machine studying fashions to carry out nicely throughout varied distributions, not simply the one they had been skilled on. Fashions have been fine-tuned on giant, pre-trained datasets particular to a job after which examined on a set of duties designed to benchmark totally different features of the system. Nevertheless, this technique has limitations, particularly when coping with knowledge distributions that diverge from the coaching set.
Researchers have explored varied strategies to acquire versatile representations, together with engineering numerous datasets, architectures, and hyperparameters. Fascinating outcomes have been achieved by adversarially reweighting the coaching dataset and concatenating representations from a number of networks. Positive-tuning deep residual networks is a near-linear course of, with the ultimate coaching part confined to a virtually convex attraction basin.
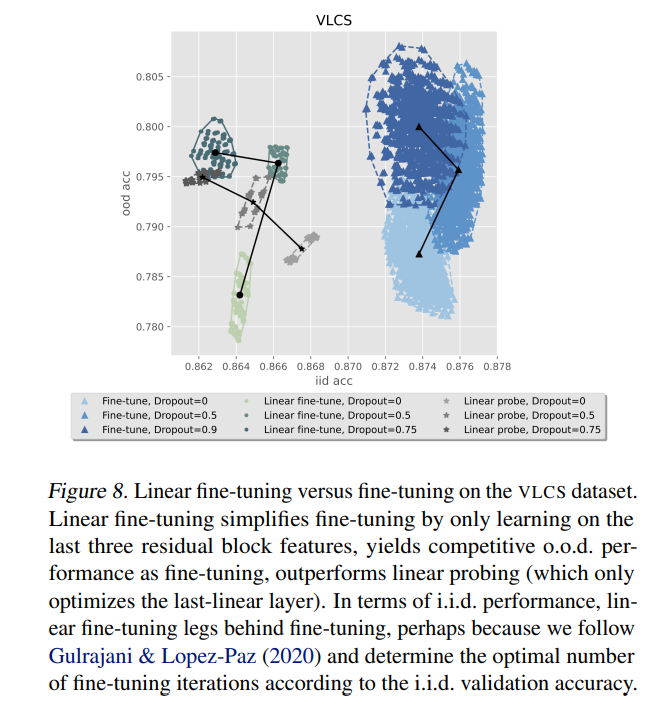
Researchers from New York College and Fb AI Analysis have launched a novel method to attaining out-of-distribution (OOD) efficiency. They examine the usage of very excessive dropout charges as an alternative choice to ensemble strategies for acquiring wealthy representations. Conventionally, coaching a deep community from scratch with excessive dropout charges is almost unattainable because of the complexity and depth of the community. Nevertheless, fine-tuning a pre-trained mannequin underneath such situations is possible and surpasses the efficiency achieved by ensembles and weight-averaging strategies like mannequin soups.
The tactic employs a complicated fine-tuning course of on a deep studying community with residual connections, primarily skilled on in depth datasets. This course of is characterised by making use of very excessive dropout charges to the penultimate layer throughout fine-tuning, successfully blocking contributions from all residual blocks with out creating new representations moderately than leveraging present ones. The method stands out by using a linear coaching approximation, the place making use of dropout acts as a type of milder regularization in comparison with its use in non-linear programs. Remarkably, this method achieves comparable or superior efficiency to conventional strategies like ensembles and weight averaging, showcasing its effectiveness throughout varied DOMAINBED duties.
Efficiency outcomes underscore the effectiveness of this technique. Positive-tuning with giant dropout charges improved OOD efficiency throughout a number of benchmarks. For example, on the VLCS dataset, a site adaptation benchmark that poses vital challenges for generalization, fashions fine-tuned with this technique confirmed substantial good points. The outcomes point out a substantial leap in OOD efficiency, affirming the tactic’s potential to boost mannequin robustness and reliability throughout numerous datasets.
In conclusion, the analysis offers a compelling case for reevaluating fine-tuning practices in machine studying. By introducing and validating very giant dropout charges, the analysis has opened up avenues for creating extra versatile and strong fashions able to navigating the complexities of numerous knowledge distributions. This technique advances our understanding of wealthy representations and units a brand new benchmark for OOD efficiency, marking a major step ahead in pursuing extra generalized machine-learning options.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and Google News. Be a part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Neglect to affix our Telegram Channel
You might also like our FREE AI Courses….
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link
