


[ad_1]
Present approaches to world modeling largely give attention to brief sequences of language, pictures, or video clips. This implies fashions miss out on info current in longer sequences. Movies encode sequential context that may’t be simply gleaned from textual content or static pictures. Lengthy-form textual content holds info unobtainable in brief items and is essential to purposes like doc retrieval or coding. Processing lengthy video and textual content sequences collectively might allow a mannequin to develop a broader multimodal understanding, making it a doubtlessly highly effective device for a lot of duties.
Instantly modeling tens of millions of tokens is extraordinarily tough as a result of excessive computational value, reminiscence constraints, and lack of appropriate datasets. Happily, RingAttention permits us to scale to longer context sizes with out overheads, enabling environment friendly coaching on lengthy sequences.
Researchers want a big dataset of lengthy movies and language sequences to harness this functionality. They’ve curated this dataset from publicly out there books and video sources containing movies of various actions and books on varied matters. To cut back coaching prices, they’ve step by step elevated context dimension from 4K to 1M tokens to scale back this value, and this method performs properly in extending context successfully.
Researchers face a number of challenges when coaching on video and language concurrently. They found that combining video, pictures, and textual content is essential to balancing visible high quality, sequential info, and linguistic understanding. They obtain this by implementing an environment friendly type of masked sequence packing for coaching with totally different sequence lengths. Moreover, figuring out the best steadiness between picture, video, and textual content coaching is essential for cross-modal understanding, and the researchers recommend an efficient ratio. Moreover, to take care of the dearth of long-form chat datasets, they developed a way the place a short-context mannequin is used to generate a question-answering (QA) dataset from books, which proves essential for long-sequence chat capability.
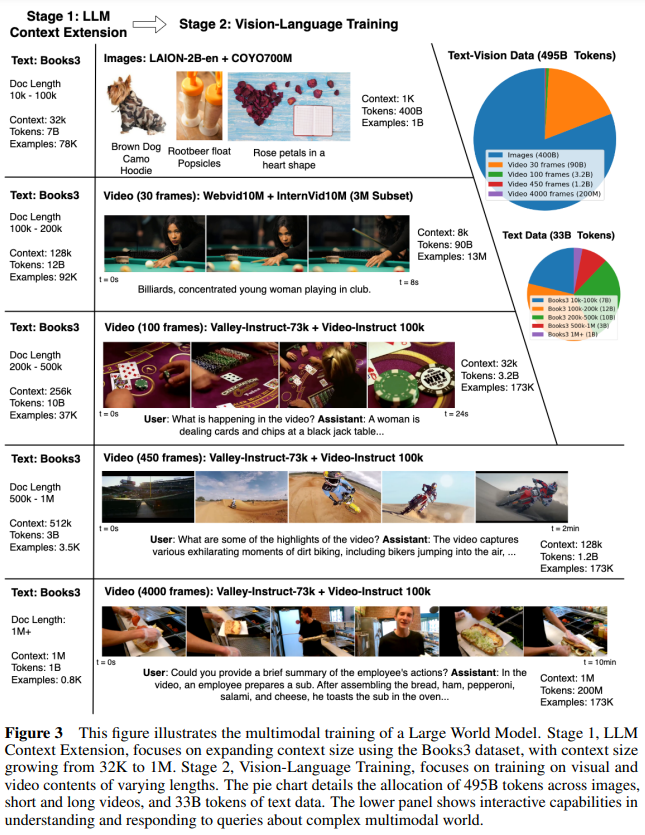
Let’s talk about the general methodology intimately; the researchers prepare a big autoregressive transformer mannequin on a large dataset, incrementally growing its context window to one million tokens. They construct on Llama2 7B and mix lengthy multimodal sequences with text-image, text-video information, and books. The coaching phases and datasets are proven in Determine 3, and the mannequin structure is proven in Determine 4.
Coaching Phases and Datasets
- Stage I: Lengthy-Context Language Mannequin
- Extending Context: The researchers use RingAttention for scalable long-document coaching and modify positional encoding parameters.
- Progressive Coaching: They save compute by coaching on more and more longer sequences (32K to 1M tokens).
- Chat Nice-tuning: They generate a QA dataset for long-context chat skills from books.
- Stage II: Lengthy-Context Imaginative and prescient-Language Fashions
- Architectural Adjustments: The researchers use VQGAN tokens for pictures and movies and add markers to change between imaginative and prescient and textual content technology.
- Progressive Coaching: The mannequin undergoes a number of phases of coaching, every growing in sequence size. This step-by-step method helps be taught extra successfully by beginning with less complicated duties earlier than transferring on to extra complicated sequences.
- Chat Datasets: They embrace varied types of chat information for his or her goal downstream duties. By producing a question-answering dataset from lengthy texts, the mannequin improves its capability to have interaction in significant conversations over prolonged sequences.

On analysis, the mannequin achieves near-perfect retrieval accuracy over its complete 1M context window and scales higher than present LLMs. It additionally performs competitively in multi-needle retrieval and reveals robust short-context language efficiency (proven in Determine 2), indicating profitable context growth. Whereas it has some limitations, resembling issue with complicated long-range duties, it gives a basis for future work, together with creating tougher benchmarks.
In conclusion, this pioneering work has set a brand new benchmark in AI’s functionality to grasp the world by integrating language and video. Leveraging the modern RingAttention mechanism, the examine demonstrates scalable coaching on an intensive dataset of lengthy movies and books, progressively increasing the context dimension from 32K to an unprecedented 1M tokens. This method, mixed with the event of masked sequence packing and loss weighting methods, allows the environment friendly dealing with of a various array of content material. The result’s a mannequin with a 1M token context dimension, the most important to this point, adept at navigating the complexities of prolonged video and language sequences. With the open sourcing of this optimized implementation and a 7B parameter mannequin, the analysis invitations additional innovation within the area, aiming to boost AI’s reasoning skills and understanding of the world.
Nevertheless, the journey doesn’t finish right here. Regardless of its vital achievements, the work acknowledges limitations and areas ripe for future exploration. Enhancing video tokenization for extra compact processing, incorporating extra modalities like audio, and bettering video information high quality and amount are crucial subsequent steps. These developments promise to additional refine AI’s multimodal understanding, opening new pathways for analysis and utility within the quest to develop extra subtle and succesful AI methods.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Courses….
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the newest developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.
[ad_2]
Source link
