


[ad_1]
The storage and potential disclosure of delicate info have change into urgent considerations within the growth of Massive Language Fashions (LLMs). As LLMs like GPT purchase a rising repository of information, together with private particulars and dangerous content material, making certain their security and reliability is paramount. Up to date analysis has shifted in the direction of devising methods for successfully erasing delicate information from these fashions, which poses distinctive challenges and necessitates modern options.
The prevailing strategies for mitigating the danger of delicate info publicity in LMs contain direct modifications to the fashions’ weights. Nevertheless, latest findings point out that these methods are solely partially foolproof. Even subtle mannequin enhancing strategies resembling ROME, designed to delete factual information from fashions like GPT-J, have proven limitations. Attackers can exploit these weaknesses by recovering deleted info, utilizing information remnants in intermediate mannequin states, or manipulating the enhancing strategies’ inefficiencies with rephrased queries.
Researchers from UNC-Chapel Hill have proposed new protection strategies. These approaches give attention to modifying the ultimate mannequin outputs and the intermediate representations inside the mannequin. The objective is to cut back the success fee of extraction assaults, which leverage the mannequin’s inner state to entry supposedly deleted info. Regardless of these developments, the protection mechanisms are solely typically efficient, highlighting the intricate nature of absolutely eradicating delicate information from LMs.
Whereas a promising strategy, the direct enhancing of mannequin weights has proven different efficacy. Experimental outcomes display that superior enhancing methods like ROME wrestle to erase factual info. Attackers using subtle whitebox and blackbox strategies can nonetheless entry the ‘deleted’ info in as much as 38% of instances. These assaults capitalize on two main observations: first, traces of deleted info might be discovered within the mannequin’s intermediate hidden states; second, enhancing strategies concentrating on one question might not successfully delete info throughout rephrased variations of the identical query.
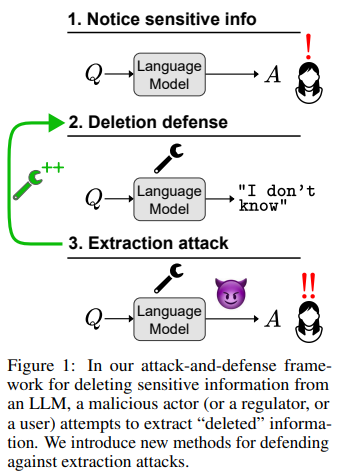
Researchers have additionally developed protection strategies that shield towards extraction assaults. These embody extending the mannequin enhancing goal to delete info from each the ultimate output and the intermediate mannequin representations. As an illustration, a protection that lowers the assault success fee from 38% to 2.4% has been recognized. Nevertheless, the protection strategies nonetheless face challenges when confronted with assault strategies they weren’t designed to defend towards, together with black field assaults. This means a wrestle to discover a dependable methodology for eradicating delicate info from language fashions.
New goals for defending towards whitebox and blackbox extraction assaults have been launched. Whereas some approaches considerably cut back whitebox assault success charges, just some strategies show efficient towards all assaults. This means that the issue of deleting delicate info from language fashions is a posh and ongoing problem, with important implications for deploying these fashions in numerous eventualities, particularly in gentle of accelerating privateness and security considerations.
In conclusion, whereas the pursuit of growing secure and dependable language fashions is ongoing, the present state of analysis highlights the issue in making certain the whole deletion of delicate info. The duty stays possible and difficult, underlining the necessity for continued innovation and vigilance. As language fashions change into more and more built-in into numerous features of life, addressing these challenges turns into a technical necessity and an moral crucial to make sure the privateness and security of people interacting with these superior applied sciences.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Neglect to affix our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link
