

[ad_1]
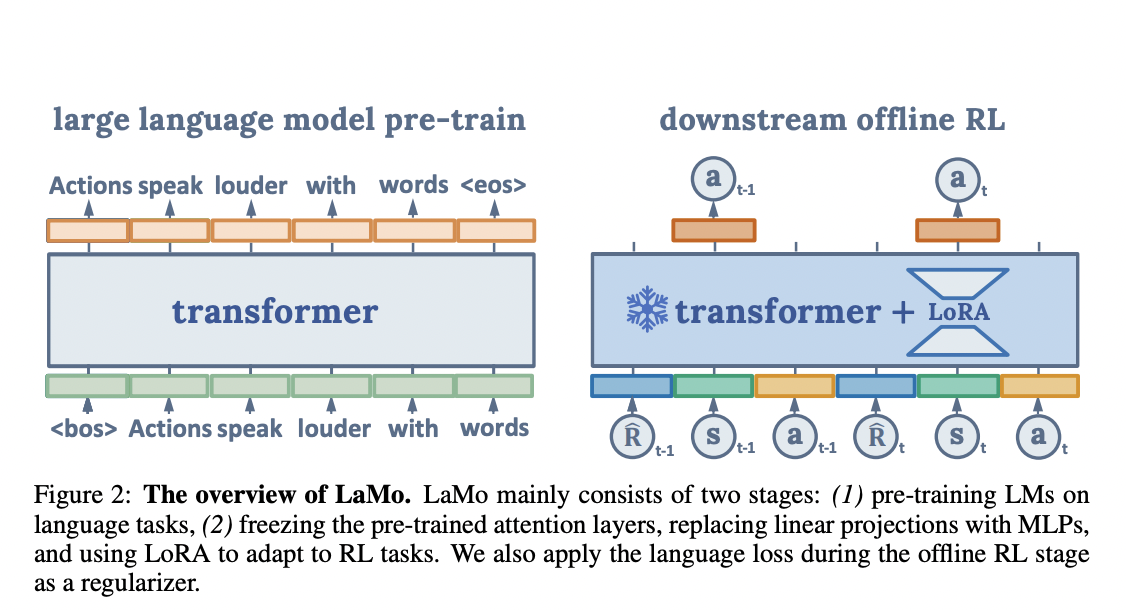
Researchers introduce Language Fashions for Movement Management (LaMo), a framework utilizing Massive Language Fashions (LLMs) for offline reinforcement studying. It leverages pre-trained LLMs to reinforce RL coverage studying, using Resolution Transformers (DT) initialized with LLMs and LoRA fine-tuning. LaMo outperforms current strategies in sparse-reward duties and narrows the hole between value-based offline RL and choice transformers in dense-reward duties, notably excelling in situations with restricted knowledge samples.
Present analysis explores the synergy between transformers, notably DT, and LLMs for decision-making in RL duties. LLMs have beforehand proven promise in high-level process decomposition and coverage era. LaMo is a novel framework leveraging pre-trained LLMs for movement management duties, surpassing current strategies in sparse-reward situations and narrowing the hole between value-based offline RL and choice transformers in dense-reward duties. It builds upon prior work like Wiki-RL, aiming to higher harness pre-trained LMs for offline RL.
The method reframes RL as a conditional sequence modelling downside. LaMo outperforms current strategies by combining LLMs with DT and introduces improvements like LoRA fine-tuning, non-linear MLP projections, and auxiliary language loss. It excels in sparse-reward duties and narrows the efficiency hole between value-based and DT-based strategies in dense-reward situations.
The LaMo framework for offline Reinforcement Studying incorporates pre-trained LMs and DTs. It enhances illustration studying with Multi-Layer Perceptrons and employs LoRA fine-tuning with an auxiliary language prediction loss to mix LMs’ data successfully. Intensive experiments throughout numerous duties and environments assess efficiency underneath various knowledge ratios, evaluating it with sturdy RL baselines like CQL, IQL, TD3BC, BC, DT, and Wiki-RL.
The LaMo framework excels in sparse and dense-reward duties, surpassing Resolution Transformer and Wiki-RL. It outperforms a number of sturdy RL baselines, together with CQL, IQL, TD3BC, BC, and DT, whereas avoiding overfitting—LaMo’s strong studying potential, particularly with restricted knowledge, advantages from pre-trained LMs’ inductive bias. Analysis of the D4RL benchmark and thorough ablation research affirm the effectiveness of every part inside the framework.
The examine wants an in-depth exploration of higher-level illustration studying strategies to reinforce full fine-tuning’s generalizability. Computational constraints restrict the examination of other approaches like joint coaching. The influence of various pre-training qualities of LMs past evaluating GPT-2, early-stopped pre-trained, and randomly shuffled pre-trained fashions nonetheless must be addressed. Particular numerical outcomes and efficiency metrics are required to substantiate claims of state-of-the-art efficiency and baseline superiority.
In conclusion, the LaMo framework makes use of pre-trained LMs for movement management in offline RL, attaining superior efficiency in sparse-reward duties in comparison with CQL, IQL, TD3BC, and DT. It narrows the efficiency hole between value-based and DT-based strategies in dense-reward research. LaMo excels in few-shot studying, because of the inductive bias from pre-trained LMs. Whereas it acknowledges some limitations, together with CQL’s competitiveness and the auxiliary language prediction loss, the examine goals to encourage additional exploration of bigger LMs in offline RL.
Try the Paper and Project. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]
Source link
