

[ad_1]
Diffusion fashions have superior considerably and attracted a lot examine consideration regardless of being just lately offered. Such fashions reverse the diffusion course of to supply clear, high-quality outputs from random noise inputs. Throughout numerous datasets, diffusion fashions can outperform cutting-edge generative adversarial networks (GANs) relating to technology high quality. Most significantly, diffusion fashions supply a flexible approach to deal with many conditional enter varieties, together with semantic maps, textual content, representations, and photos, in addition to improved mode protection. Though these strategies are utilized in many different information domains and purposes, image-generation jobs exhibit essentially the most spectacular outcomes.
New diffusion-based text-to-image generative fashions open a brand new period of AI-based digital artwork and supply intriguing purposes to a number of different fields by enabling customers to create extremely lifelike photos solely by phrase inputs. Due to this talent, they’ll do numerous duties, together with text-to-image manufacturing, image-to-image translation, picture inpainting, image restoration, and extra. Diffusion fashions have immense promise however run very slowlya severe flaw stopping them from turning into as in style as GANs. It takes minutes to generate a single picture utilizing the foundational work Denoising Diffusion Probabilistic Fashions (DDPMs), which requires a thousand sampling steps to acquire the suitable output high quality.
A number of strategies have been advised to shorten the inference time, largely by reducing the variety of pattern steps. By fusing Diffusion and GANs right into a single system, DiffusionGAN achieved a breakthrough in accelerating inference velocity. Consequently, the variety of sampling steps is decreased to 4, and it takes only a fraction of a second to deduce a 32 x 32 image. Nonetheless, the earlier quickest approach, round 100 occasions slower than GAN, nonetheless wants seconds to create a 32 x 32 image.
DiffusionGAN is now the quickest diffusion mannequin available on the market. Even so, it’s a minimum of 4 occasions slower than the StyleGAN equal, and the velocity distinction retains widening when the output decision is raised. Diffusion fashions nonetheless must be ready for large-scale or real-time purposes, as evidenced by the truth that DiffusionGAN nonetheless has a sluggish convergence and requires a prolonged coaching interval.
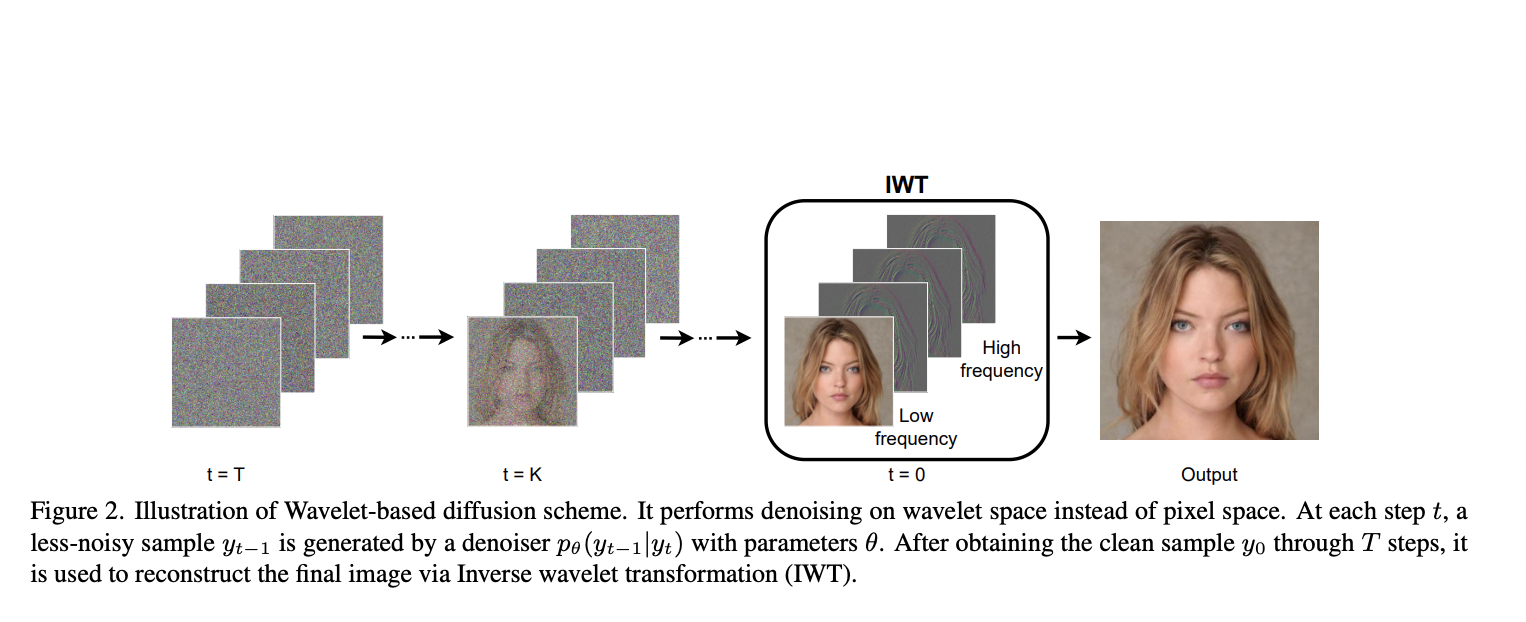
Researchers from VinAI suggest a singular wavelet-based diffusion technique to shut the velocity hole. The discrete wavelet remodel, which divides every enter into 4 sub-bands for low- (LL) and high-frequency (LH, HL, HH) parts, is the premise of their resolution. They use that remodel on the function degree and the picture degree. They get a big speedup on the image degree by reducing the spatial decision by 4 occasions. On the function degree, they emphasize the worth of wavelet information on numerous generator blocks. With such a design, they’ll obtain a big efficiency enhance whereas introducing solely a minor processing burden. This permits us to dramatically minimize coaching and inference durations whereas sustaining a continuing degree of output high quality.
Their contributions are as follows:
• They supply a singular Wavelet Diffusion framework that makes use of high-frequency parts to retain the visible high quality of generated outcomes whereas using the dimensional discount of Wavelet subbands to hurry up Diffusion Fashions.
• To extend the generative fashions’ robustness and execution velocity, they use picture and have house wavelet decomposition.
• The state-of-the-art coaching and inference velocity supplied by their advised Wavelet Diffusion is a primary step in the direction of enabling real-time and high-fidelity diffusion fashions.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t neglect to hitch our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing tasks.
[ad_2]
Source link
