

[ad_1]
Iterative refinement is a key facet of human problem-solving. Iterative refinement is a course of that includes making an preliminary draught after which bettering it via self-feedback. For example, whereas writing an e mail to a coworker to request a doc, an individual would first use a simple request like “give me the information Instantly.” However, after some thought, the creator might understand that the phrase could possibly be thought of unfriendly and altered it to “May you kindly present me the information?” Utilizing iterative suggestions and modification, they present on this research that enormous language fashions (LLMs) can efficiently mimic this cognitive course of in people.
Though LLMs are able to producing coherent outputs within the preliminary stage, they regularly fall brief when addressing extra complicated necessities, notably for duties with a number of goals (akin to dialogue response era with standards like making the response related, partaking, and secure) or these with much less clear targets (e.g., enhancing program readability). Trendy LLMs could create comprehensible output in such circumstances. Nonetheless, iterative enchancment is required to ensure that each one task necessities are addressed and that the suitable stage of high quality is attained.
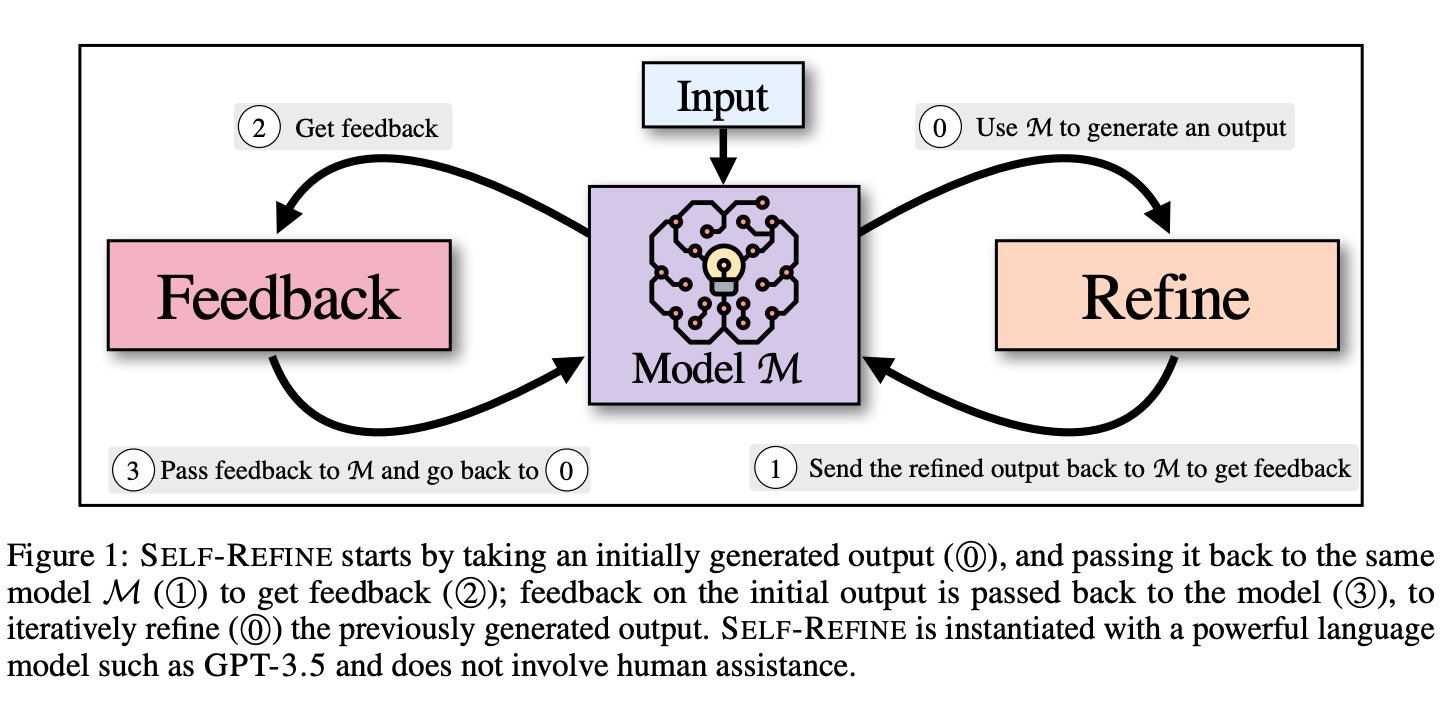
Superior strategies that depend on third-party reward and supervision fashions name both monumental quantities of coaching information or costly human annotations, which are sometimes sensible to get. These drawbacks spotlight the necessity for a extra adaptable and environment friendly technique of textual content era that could be used for a lot of jobs with little monitoring. On this research, researchers from CMU, Allen Institute, College of Washington, NVIDIA, UCSD, and Google Analysis, suggest SELF-REFINE overcome these constraints and higher replicate the human artistic manufacturing course of and not using a pricey human suggestions loop. (Determine 1).
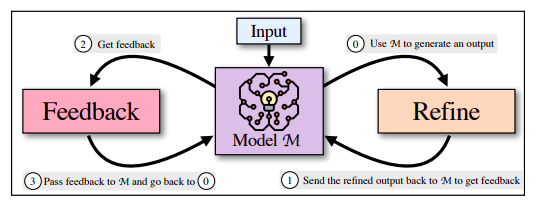
The 2 halves of SELF-REFINE—FEEDBACK and REFINE—work collectively in an iterative cycle to supply high-quality outcomes. They transmit the identical mannequin M (1), an preliminary draught output produced by mannequin M (0), to obtain suggestions (1). The identical mannequin (3) is given suggestions on the unique manufacturing, which iteratively improves (0) the output that was initially produced. Iteratively repeating this process continues till the mannequin deems no extra enchancment is required, at which level the method ends. The central thesis of this research is that in a few-shot scenario, the identical underlying language mannequin handles suggestions and refining.
SELF-REFINE supplies the primary iterative technique to boost era using NL suggestions successfully.
Determine 1 depicts the process in an instance. They use SELF-REFINE to finish numerous duties that span many domains and name for suggestions and revision strategies, akin to assessment rewriting, acronym creation, restricted era, narrative era, code rewriting, response era, and toxicity elimination. Their core elements are instantiated utilizing a few-shot prompting technique, which permits us to make use of just a few cases to jumpstart the mannequin’s studying. Their iterative method, which incorporates experiments, element evaluation, quite a lot of duties, the era of helpful suggestions, and stopping standards, is meant to information future analysis on this area.
Their contributions, in short, are:
- To assist LLMs do higher on quite a lot of duties, they counsel SELF-REFINE, a novel approach that allows them to boost their outcomes utilizing their suggestions repeatedly. Not like earlier efforts, their technique requires a single LLM, which makes use of reinforcement studying or supervised coaching information.
- They conduct intensive experiments on seven completely different duties—assessment rewriting, acronym era, story era, code rewriting, response era, constrained era, and toxicity elimination—and present that SELF-REFINE performs not less than 5% higher—and generally as much as greater than 40% higher—than a direct era from highly effective turbines like GPT-3.5 and even GPT-4.
Take a look at the Paper, Code and Project. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.
[ad_2]
Source link
