

[ad_1]
Reinforcement studying (RL) includes a variety of algorithms, usually divided into two important teams: model-based (MB) and model-free (MF) strategies. MB algorithms depend on predictive fashions of setting suggestions, termed world fashions, which simulate real-world dynamics. These fashions facilitate coverage derivation by way of motion exploration or coverage optimization. Regardless of their potential, MB strategies usually need assistance with modeling inaccuracies, doubtlessly resulting in suboptimal efficiency in comparison with MF methods.
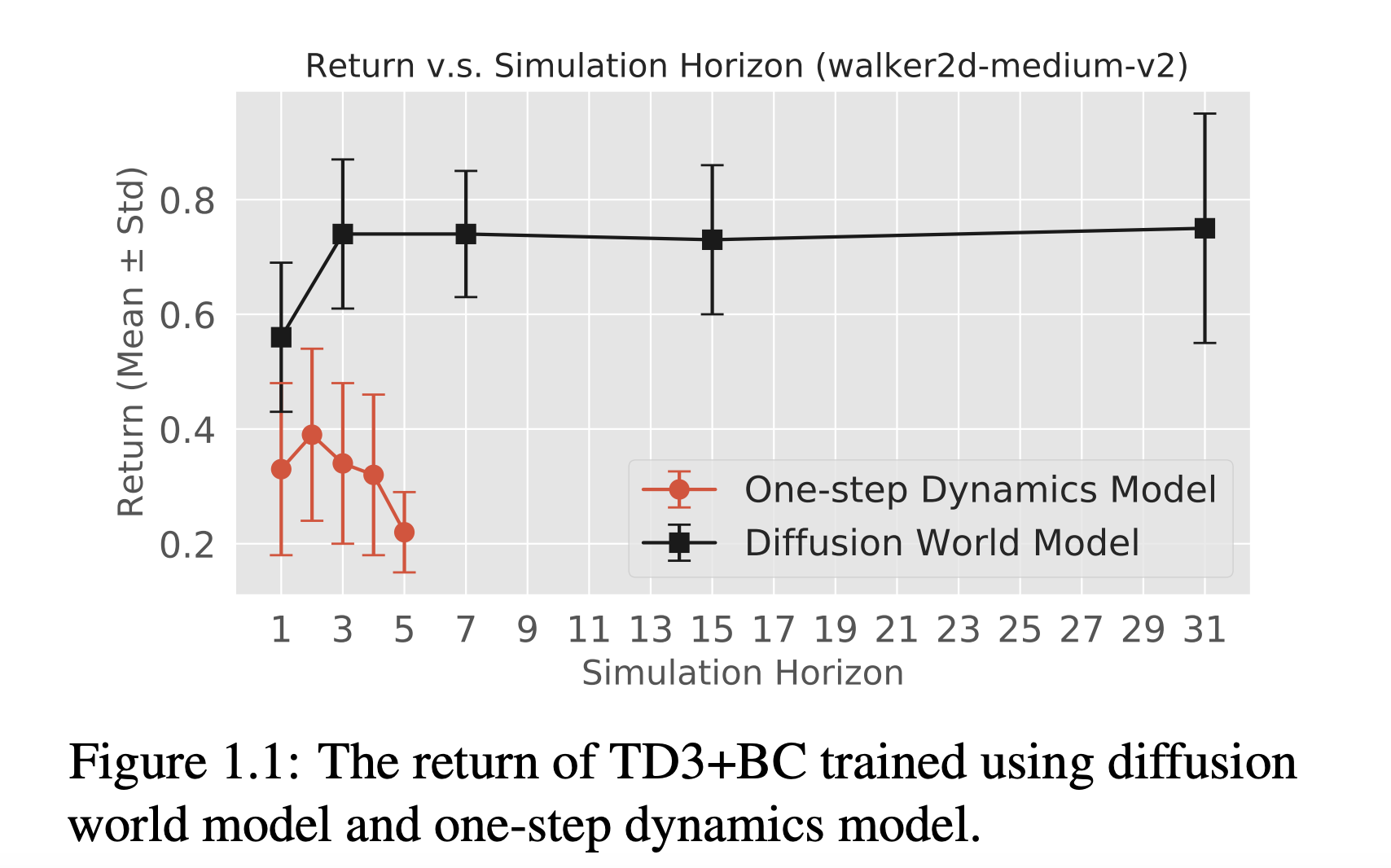
A big problem in MB RL lies in minimizing world modeling inaccuracies. Conventional world fashions usually endure from limitations of their one-step dynamics, predicting the following state and reward solely primarily based on the present state and motion. Researchers suggest a novel method referred to as the Diffusion World Mannequin (DWM) to handle this limitation.
Not like typical fashions, DWM is a diffusion probabilistic mannequin particularly tailor-made for predicting long-horizon outcomes. By concurrently indicating multi-step future states and rewards with out recursive querying, DWM eliminates the supply of error accumulation.
DWM is educated utilizing the accessible dataset, and insurance policies are subsequently educated utilizing synthesized knowledge generated by DWM by way of an actor-critic method. To boost efficiency additional, researchers launched diffusion mannequin worth growth (Diffusion-MVE) to simulate returns primarily based on future trajectories generated by DWM. This methodology successfully makes use of generative modeling to facilitate offline Q-learning with artificial knowledge.
The effectiveness of their proposed framework is demonstrated by way of empirical analysis, particularly in locomotion duties from the D4RL benchmark. Evaluating diffusion-based world fashions with conventional one-step fashions reveals notable efficiency enhancements.
The diffusion world mannequin achieves a outstanding 44% enhancement over one-step fashions throughout duties in steady motion and statement areas. Furthermore, the framework’s capacity to bridge the hole between MB and MF algorithms is underscored, with the strategy attaining state-of-the-art efficiency in offline RL, highlighting its potential to advance the sector of reinforcement studying.
Moreover, current developments in offline RL methodologies have primarily focused on MF algorithms, with restricted consideration paid to reconciling the disparities between MB and MF approaches. Nonetheless, their framework tackles this hole by harnessing the strengths of each MB and MF paradigms.
By integrating the Diffusion World Mannequin into the offline RL framework, one can obtain state-of-the-art efficiency, surmounting the constraints of conventional one-step world fashions. This underscores the importance of sequence modeling methods in decision-making issues and the potential for hybrid approaches amalgamating the benefits of each MB and MF strategies.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and Google News. Be a part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
Arshad is an intern at MarktechPost. He’s at the moment pursuing his Int. MSc Physics from the Indian Institute of Know-how Kharagpur. Understanding issues to the elemental degree results in new discoveries which result in development in know-how. He’s captivated with understanding the character basically with the assistance of instruments like mathematical fashions, ML fashions and AI.
[ad_2]
Source link
