

[ad_1]
Motion recognition, the duty of figuring out and classifying human actions from video sequences, is an important subject inside pc imaginative and prescient. Nonetheless, its reliance on large-scale datasets containing photos of individuals brings forth vital challenges associated to privateness, ethics, and knowledge safety. These points come up as a result of potential identification of people primarily based on private attributes and knowledge assortment with out express consent. Furthermore, biases associated to gender, race, or particular actions carried out by sure teams can have an effect on the accuracy and equity of fashions skilled on such datasets.
In motion recognition, developments in pre-training methodologies on huge video datasets have been pivotal. Nonetheless, these developments include challenges, equivalent to moral issues, privateness points, and biases inherent in datasets with human imagery. Current approaches to sort out these points embrace blurring faces, downsampling movies, or using artificial knowledge for coaching. Regardless of these efforts, there must be extra evaluation of how properly privacy-preserving pre-trained fashions switch their realized representations to downstream duties. The state-of-the-art fashions generally fail to foretell actions precisely attributable to biases or a scarcity of various representations within the coaching knowledge. These challenges demand novel approaches that deal with privateness issues and improve the transferability of realized representations to numerous motion recognition duties.
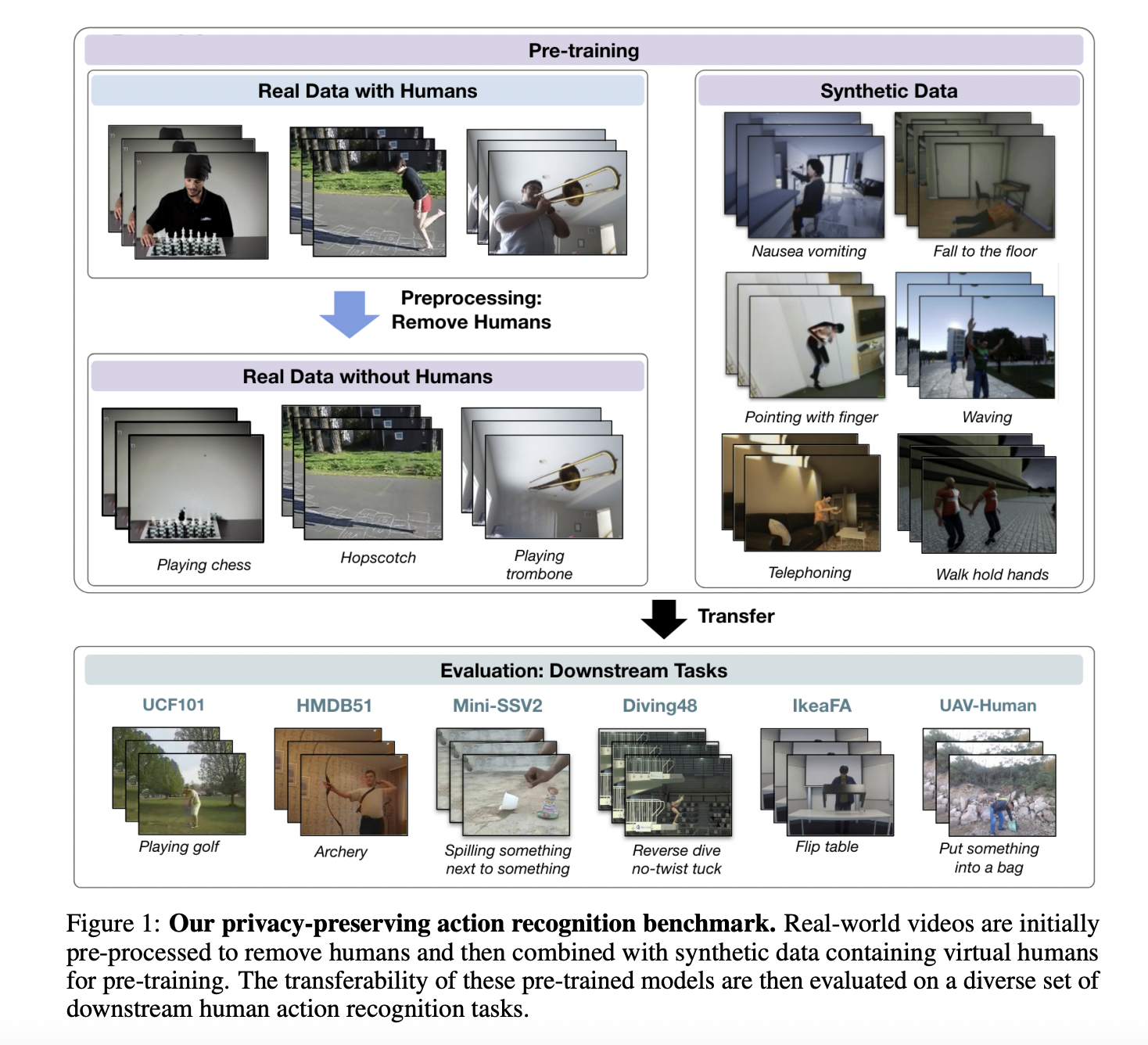
To beat the challenges posed by privateness issues and biases in human-centric datasets used for motion recognition, a brand new technique was lately introduced at NeurIPS 2023, the well-known convention, that introduces a groundbreaking strategy. This newly printed work devises a technique to pre-train motion recognition fashions utilizing a mix of artificial movies containing digital people and real-world movies with people eliminated. By leveraging this novel pre-training technique termed Privateness-Preserving MAE-Align (PPMA), the mannequin learns temporal dynamics from artificial knowledge and contextual options from actual movies with out people. This modern technique helps deal with privateness and moral issues associated to human knowledge. It considerably improves the transferability of realized representations to various downstream motion recognition duties, closing the efficiency hole between fashions skilled with and with out human-centric knowledge.
Concretely, the proposed PPMA technique follows these key steps:
- Privateness-Preserving Actual Information: The method begins with the Kinetics dataset, from which people are eliminated utilizing the HAT framework, ensuing within the No-Human Kinetics dataset.
- Artificial Information Addition: Artificial movies from SynAPT are included, providing digital human actions facilitating deal with temporal options.
- Downstream Analysis: Six various duties consider the mannequin’s transferability throughout numerous motion recognition challenges.
- MAE-Align Pre-training: This two-stage technique entails:
- Stage 1: MAE Coaching to foretell pixel values, studying real-world contextual options.
- Stage 2: Supervised Alignment utilizing each No-Human Kinetics and artificial knowledge for motion label-based coaching.
- Privateness-Preserving MAE-Align (PPMA): Combining Stage 1 (MAE skilled on No-Human Kinetics) with Stage 2 (alignment utilizing each No-Human Kinetics and artificial knowledge), PPMA ensures sturdy illustration studying whereas safeguarding privateness.
The analysis crew carried out experiments to guage the proposed strategy. Utilizing ViT-B fashions skilled from scratch with out ImageNet pre-training, they employed a two-stage course of: MAE coaching for 200 epochs adopted by supervised alignment for 50 epochs. Throughout six various duties, PPMA outperformed different privacy-preserving strategies by 2.5% in finetuning (FT) and 5% in linear probing (LP). Though barely much less efficient on excessive scene-object bias duties, PPMA considerably decreased the efficiency hole in comparison with fashions skilled on actual human-centric knowledge, showcasing promise in reaching sturdy representations whereas preserving privateness. Ablation experiments highlighted the effectiveness of MAE pre-training in studying transferable options, significantly evident when finetuned on downstream duties. Moreover, exploring the mixture of contextual and temporal options, strategies like averaging mannequin weights and dynamically studying mixing proportions confirmed potential for bettering representations, opening avenues for additional exploration.
This text introduces PPMA, a novel privacy-preserving strategy for motion recognition fashions, addressing privateness, ethics, and bias challenges in human-centric datasets. Leveraging artificial and human-free real-world knowledge, PPMA successfully transfers realized representations to various motion recognition duties, minimizing the efficiency hole between fashions skilled with and with out human-centric knowledge. The experiments underscore PPMA’s effectiveness in advancing motion recognition whereas making certain privateness and mitigating moral issues and biases linked to standard datasets.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to hitch our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Mahmoud is a PhD researcher in machine studying. He additionally holds a
bachelor’s diploma in bodily science and a grasp’s diploma in
telecommunications and networking methods. His present areas of
analysis concern pc imaginative and prescient, inventory market prediction and deep
studying. He produced a number of scientific articles about individual re-
identification and the research of the robustness and stability of deep
networks.
[ad_2]
Source link
