


[ad_1]
AI growth is shifting from static, task-centric fashions to dynamic, adaptable agent-based programs appropriate for varied purposes. AI programs intention to collect sensory information and successfully have interaction with environments, a longstanding analysis purpose. Creating generalist AI affords benefits, together with coaching a single neural mannequin throughout a number of duties and information varieties. This method is very scalable by way of information, computational sources, and mannequin parameters.
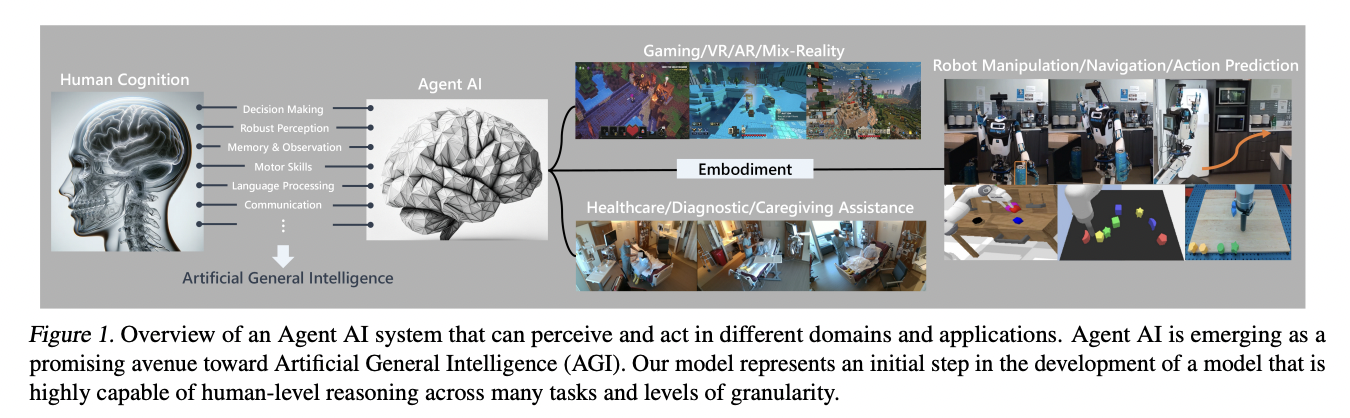
Current works spotlight some great benefits of growing generalist AI programs by coaching a single neural mannequin throughout varied duties and information varieties, providing scalability by way of information, compute, and mannequin parameters. Nevertheless, challenges persist, as massive basis fashions typically produce hallucinations and infer incorrect info as a consequence of inadequate grounding in coaching environments. Present multimodal system approaches, counting on frozen pre-trained fashions for every modality, could perpetuate errors with out cross-modal pre-training.
Researchers from Stanford College, Microsoft Analysis, Redmond, and the College of California, Los Angeles, have proposed the Interactive Agent Basis Mannequin, which introduces a unified pre-training framework for processing textual content, visible information, and actions, treating every as separate tokens. It makes use of pre-trained language and visual-language fashions to foretell masked tokens throughout all modalities. It permits interplay with people and environments, incorporating visual-language understanding. With 277M parameters collectively pre-trained throughout numerous domains, it engages successfully in multi-modal settings throughout varied digital environments.
The Interactive Agent Basis Mannequin initializes its structure with pre-trained CLIP ViT-B16 for visible encoding and OPT-125M for motion and language modeling. It incorporates cross-modal info sharing by way of a linear layer transformation. As a result of reminiscence constraints, earlier actions and visible frames are included as enter, with a sliding window method. Sinusoidal positional embeddings are utilized for predicting masked seen tokens. Not like prior fashions counting on frozen submodules, your complete mannequin is collectively skilled throughout pre-training.
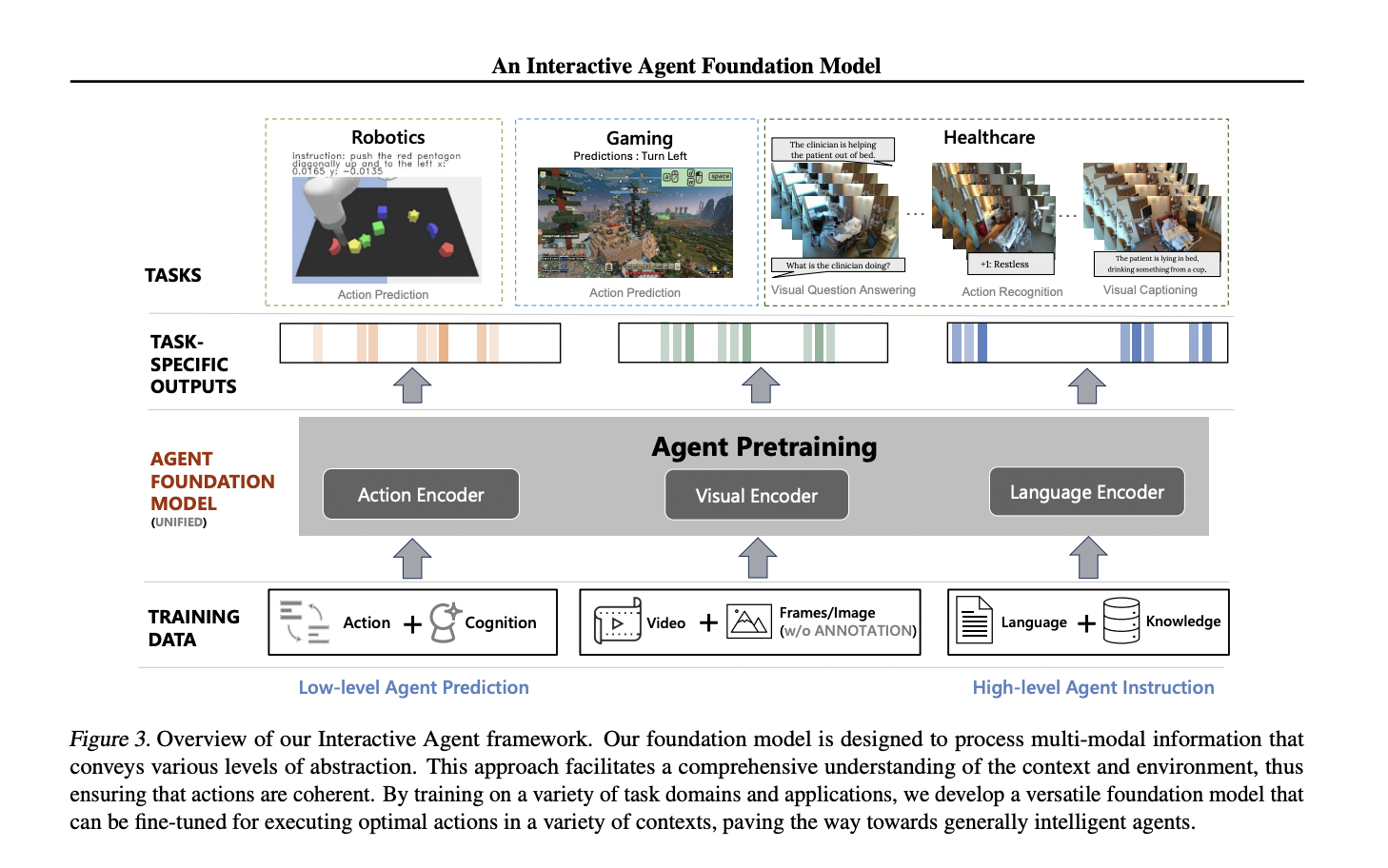
Analysis throughout robotics, gaming, and healthcare duties demonstrates promising outcomes. Regardless of being outperformed in sure duties by different fashions as a consequence of much less information for pre-training, the tactic showcases aggressive efficiency, particularly in robotics, the place it considerably surpasses a comparative mannequin. Fne-tuning the pre-trained mannequin proves notably efficient in gaming duties in comparison with coaching from scratch. In healthcare purposes, the tactic outperforms a number of baselines leveraging CLIP and OPT for initialization, demonstrating the efficacy of its numerous pre-training method.
In conclusion, Researchers proposed the Interactive Agent Basis Mannequin, which is adept at processing textual content, motion, and visible inputs and demonstrates effectiveness throughout numerous domains. Pre-training on a mix of robotics and gaming information permits the mannequin to proficiently mannequin actions, even exhibiting constructive switch to healthcare duties throughout fine-tuning. Its broad applicability throughout decision-making contexts suggests potential for generalist brokers in multimodal programs, unlocking new alternatives for AI development.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and Google News. Be part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]
Source link
