


[ad_1]
Many datasets, convolutional neural networks, and transformers have achieved exceptional success on numerous imaginative and prescient duties. As a substitute, few-shot studying, the place the networks are confined to study from constrained photos with annotations, additionally turns into a analysis hotspot for numerous data-deficient and resource-finite eventualities. Quite a few earlier publications have advised utilizing meta-learning, metric studying, and information augmentation to enhance a mannequin’s generalization capability. Latest outcomes exhibit good zero-shot switch skill for open-vocabulary visible identification utilizing CLIP pre-trained by large-scale language-image pairings.
It’s additional prolonged for few-shot classification by the follow-up CoOp, CLIP-Adapter, and Tip-Adapter, which additionally achieves improved efficiency on numerous downstream datasets. This reveals that the community has sturdy representational capabilities even whereas the few-shot coaching materials is insufficient, which enormously aids the few-shot studying on downstream domains. With the arrival of different self-supervision fashions than CLIP, might they collaborate and adaptively combine their prior information to grow to be higher few-shot learners? Chinese language researchers counsel CaFo, a Cascade of Basis mannequin, to handle this drawback by combining the data from a number of pre-training paradigms with a “Immediate, Produce, then Cache” pipeline.
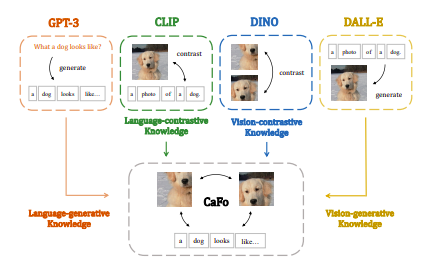
They mix CLIP, DINO, DALL-E, and GPT3 to present CaFo 4 types of earlier information, as seen in Determine 1. CLIP is pre-trained to supply paired options for every image and its corresponding description textual content within the embedding area. With language-contrastive information and texts with numerous class meanings, CLIP can categorize the pictures efficiently. DINO makes use of contrastive self-supervised studying to match the representations between two transformations of the identical image. DINO is an skilled at differentiating between numerous pictures utilizing vision-contrastive information. DALL-E is pre-trained utilizing picture-text pairings, very similar to CLIP, besides it learns to anticipate the encoded picture tokens based mostly on the supplied textual content tokens. Relying on the provided textual content, DALLE may use vision-generative information to generate high-quality artificial photos in a zero-shot approach.
When given a couple of handwritten templates as enter, the large-scale language corpus-trained GPT-3 mechanically creates sentences that appear like human speech and are wealthy in generative language information. The 4 fashions, due to this fact, have totally different pre-training aims and may provide to enhance info to help in few-shot visible identification. They cascade them in three phases, particularly:
1) Fast: Primarily based on a couple of handwritten templates, they use GPT-3 to generate textual prompts for CLIP. The textual encoder in CLIP receives these directions with a extra subtle language understanding.
2) Produce: They use DALL-E, which expands the few-shot coaching information whereas requiring no extra labor for assortment and annotation, to provide extra coaching photos for numerous classes based mostly on the domain-specific texts.
3) Cache: To adaptively incorporate the predictions from CLIP and DINO, they use a caching mannequin. They assemble the cache mannequin with two forms of keys by the 2 pre-trained fashions utilizing Tip-Adapter. They adaptively ensemble the predictions of two cached keys because the output, utilizing zero-shot CLIP because the distribution baseline. CaFo can enhance few-shot visible recognition by studying to mix earlier information and use their complementing properties by fine-tuning the light-weight cache mannequin by way of elevated coaching information.
The next summarizes their key contributions:
• For improved few-shot studying, they counsel utilizing CaFo to include previous info from numerous pre-training paradigms.
• They conduct thorough experiments on 11 datasets for few-shot classification, the place CaFo achieves state-of-the-art with out utilizing extra annotated information.
• They collaborate with CLIP, DINO, GPT-3, and DALL-E to make use of extra semantic prompts, enrich the restricted few-shot coaching information, and adaptively ensemble numerous predictions by way of the cache mannequin.
Take a look at the Paper and Code. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to affix our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on fascinating initiatives.
[ad_2]
Source link
