

[ad_1]
Massive language fashions like GPT-3, OPT, and BLOOM have demonstrated spectacular capabilities in numerous purposes. In keeping with a latest research, there are two key methods to spice up their efficiency: enhancing LLMs’ capability to comply with prompts and creating procedures for immediate engineering. Wonderful-tuning LLMs alters their weights to satisfy particular directions and enhance job efficiency. This could possibly be constrained, although, by processing sources and the unavailability of mannequin weights. A special methodology for enhancing zero-shot job generalization is offered by multi-task tuning, which partially justifies the expense of tuning.
But, as a result of LLMs are at all times evolving, it turns into essential to fine-tune new fashions, which raises severe questions concerning the complete price of fine-tuning. Engineering cues are used to direct frozen LLMs. The immediate design incorporates an engineering pure language immediate into the duty enter to coach the LLM to study in context or to encourage the LLM to motive. Fast tuning provides a delicate immediate represented by steady parameters to enhance it. Though these strategies can present excellent outcomes for explicit jobs, it’s unclear if prompts created for one job can be utilized for different job varieties that haven’t but been found since tight zero-shot settings make immediate designers blind.
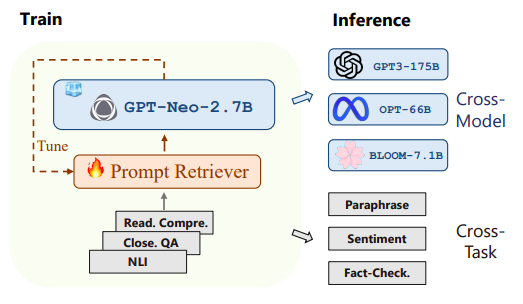
UPRISE proposed by Microsoft researchers is a viable and helpful resolution for real-world purposes due to its cross-model and cross-task generalization. On this research, they provide UPRISE, a light-weight and adaptable retriever that, given a zero-shot job enter, adjusts prompts from a pre-constructed pool of knowledge routinely. The retriever is taught to get better cues for numerous duties, as seen in Determine 1, permitting it to generalize to different job varieties throughout inference. Furthermore, they present how successfully the cross-task abilities translate from a tiny LLM to a number of LLMs of significantly bigger scales by tweaking the retriever utilizing GPT-Neo-2.7B and assessing its efficiency on BLOOM-7.1B, OPT-66B, and GPT3-175B.
ChatGPT has been found to battle with main hallucination points, leading to factually incorrect replies regardless of its nice abilities. UPRISE can clear up this drawback for fact-checking duties by instructing the mannequin to infer the fitting conclusions from its pre-existing data. Moreover, as demonstrated by their trials with ChatGPT, their approach can enhance even essentially the most potent LLMs.
In conclusion, their contributions embrace the next:
• They develop UPRISE, a easy and adaptable methodology to boost LLMs’ zero-shot efficiency in cross-task and cross-model contexts.
• Their investigation on ChatGPT reveals the potential of UPRISE in boosting the efficiency of even the strongest LLMs. UPRISE is adjusted with GPT-Neo-2.7B however may profit numerous LLMs of significantly greater sizes, akin to BLOOM-7.1B, OPT-66B, and GPT3-175B.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to hitch our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on tasks geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with individuals and collaborate on fascinating tasks.
[ad_2]
Source link
