

[ad_1]
Diffusion fashions are highly effective fashions which are distinguished in a various vary of technology duties – photographs, speech, video, and music. They’re able to obtain state-of-the-art efficiency in picture technology, with superior visible high quality and density estimation. Diffusion fashions outline a Markov Chain of diffusion steps to progressively add random noise to the pictures after which study to reverse the method to generate desired high-quality photographs.
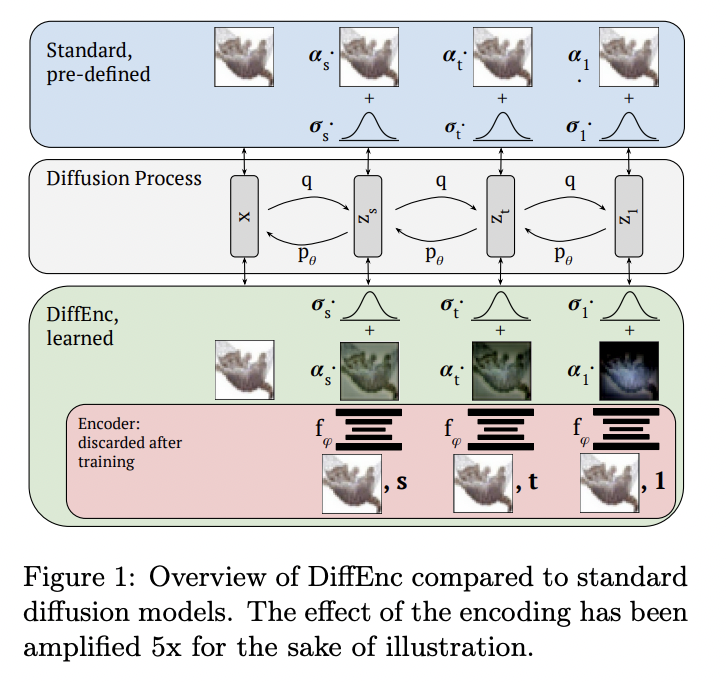
Diffusion fashions function as a hierarchical framework, with a collection of latent variables generated sequentially, the place every variable will depend on the one generated within the earlier step. The structure of diffusion fashions has the next constraints:
- The method of introducing noise into the information is simple and stuck.
- Every layer of hidden variables depends solely on the earlier step.
- All of the steps within the mannequin share the identical parameters.
Regardless of the restrictions talked about above, diffusion fashions are extremely scalable and versatile. On this paper, a bunch of researchers have launched a brand new framework, DiffEnf, to additional improve the pliability with out affecting their scalability.
Differing from the standard technique of including noise, the researchers have launched a time-dependent encoder that parameterizes the imply of the diffusion course of. The encoder basically predicts the encoded picture at a given time. Furthermore, this encoder is used solely on the coaching section and never in the course of the sampling course of. These two properties make DiffEnc extra versatile than conventional diffusion fashions with out affecting the sampling time.
For analysis, the researchers in contrast totally different variations of DiffEnc with an ordinary VDM baseline on two fashionable datasets: CIFAR-10 and MNIST. The DiffEnc-32-4 mannequin outperforms the earlier works and the VDMv-32 mannequin when it comes to decrease Bits Per Dimension (BPD). This implies that the encoder, though not used throughout sampling, contributes to a greater generative mannequin with out affecting the sampling time. The outcomes additionally present that the distinction within the whole loss is primarily because of the enchancment within the diffusion loss for DiffEnc-32-4, emphasizing the useful position of the encoder within the diffusion course of.
The researchers additionally noticed that growing the dimensions of the encoder doesn’t lead to a big enchancment within the common diffusion loss as in comparison with VDM. They hypothesize that with a view to obtain important variations, longer coaching could also be required, or a bigger diffusion mannequin may be needed to totally make the most of the encoder’s capabilities.
The outcomes present that including a time-dependent encoder may enhance the diffusion course of. Regardless that the encoder doesn’t improve the sampling time, the sampling course of continues to be slower in comparison with Generative Adversarial Networks (GANs). Nonetheless, regardless of this limitation, DiffEnc nonetheless improves the pliability of diffusion fashions and is ready to obtain state-of-the-art probability on the CIFAR-10 dataset. Furthermore, the researchers suggest that the framework could possibly be mixed with different current strategies, resembling latent diffusion, discriminator steering, and consistency regularization, to enhance the discovered representations, probably opening up new avenues for a variety of picture technology duties.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Knowledge Science, particularly Neural Networks and their utility in varied areas.
[ad_2]
Source link
