


[ad_1]
Giant Language Fashions (LLMs) are essential to maximizing effectivity in pure language processing. These fashions, central to numerous purposes starting from language translation to conversational AI, face a important problem within the type of inference latency. This latency, primarily ensuing from conventional autoregressive decoding the place every token is generated sequentially, will increase with the complexity and measurement of the mannequin, posing a big hurdle to real-time responsiveness.
Researchers have developed an revolutionary strategy, which is the middle of this survey, generally known as Speculative Decoding, to deal with this. This technique diverges from the traditional sequential token technology by permitting a number of tokens to be processed concurrently, considerably accelerating the inference course of. At its core, Speculative Decoding consists of two elementary steps: drafting and verification. Within the drafting section, a specialised mannequin, generally known as the drafter, shortly predicts a number of future tokens. These tokens should not last outputs however hypotheses of the following tokens. The drafter mannequin operates effectively, producing these predictions quickly, which is essential for the general pace of the method.
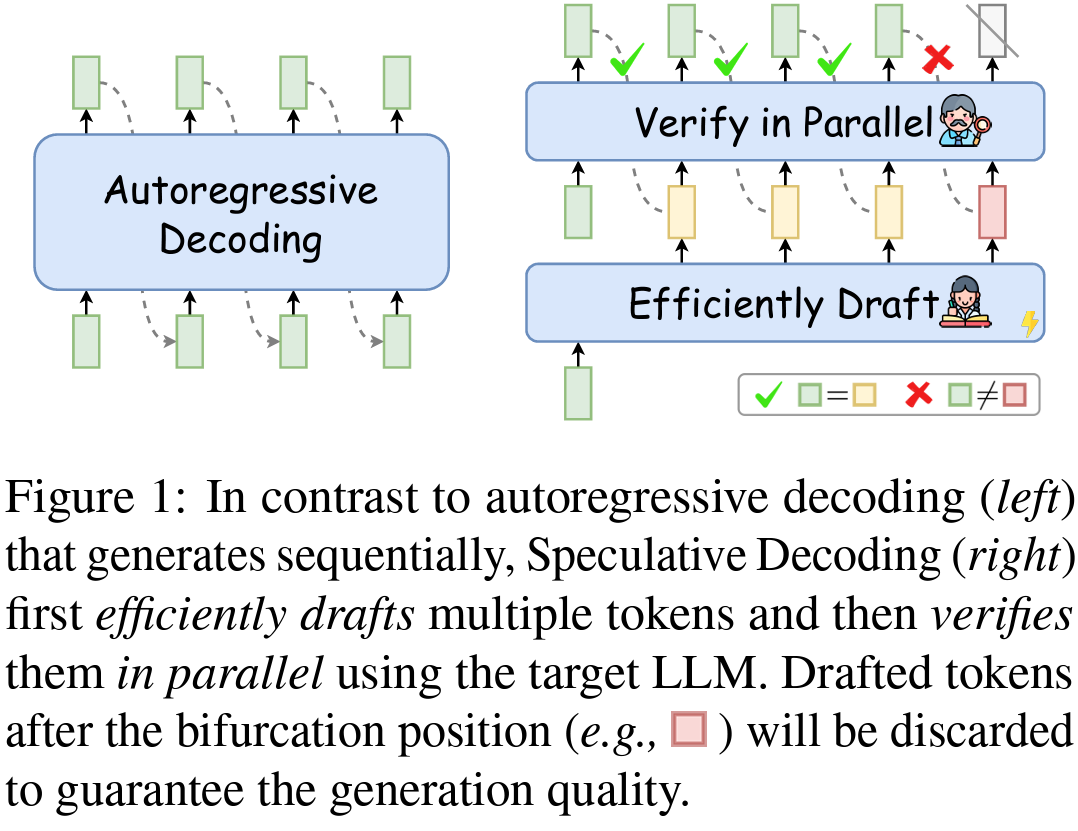
Following the drafting section, the verification step comes into play. Right here, the goal LLM evaluates the drafted tokens in parallel, guaranteeing that the output maintains the standard and coherence anticipated from the mannequin. This parallel processing strategy considerably differs from the normal technique, the place every token’s technology will depend on the earlier ones. By decreasing the dependency on sequential processing, Speculative Decoding minimizes the time-consuming reminiscence learn/write operations typical in LLMs.
The efficiency and outcomes of Speculative Decoding have been noteworthy. Researchers have demonstrated that this technique can obtain substantial speedups in producing textual content outputs with out compromising the standard. This effectivity acquire is especially vital given the rising demand for real-time, interactive AI purposes, the place response time is essential. For example, in eventualities like conversational AI, the place immediacy is essential to person expertise, the lowered latency provided by Speculative Decoding is usually a game-changer.
Furthermore, Speculative Decoding has broader implications for AI and machine studying. Providing a extra environment friendly approach to course of giant language fashions opens up new prospects for his or her software, making them extra accessible and sensible for a wider vary of makes use of. This contains real-time interplay and sophisticated duties like large-scale knowledge evaluation and language understanding, the place processing pace is a limiting issue.
Speculative Decoding is a significant development in LLMs. Addressing the important problem of inference latency enhances the practicality of those fashions and broadens their potential purposes. This breakthrough stands as a testomony to the continuous innovation in AI, paving the best way for extra responsive and complex AI-driven options.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

[ad_2]
Source link
