

[ad_1]
Many researchers have envisioned a world the place any 2D picture will be instantaneously transformed right into a 3D mannequin. Analysis on this space has been principally motivated by the need to discover a generic and environment friendly technique of reaching this long-standing goal, with potential purposes spanning industrial design, animation, gaming, and augmented actuality/digital actuality.
Early learning-based approaches usually carry out effectively on sure classes, utilizing the class information earlier than inferring the general form due to the inherent ambiguity of 3D geometry in a single look. Current research have been motivated by latest developments in picture technology, resembling DALL-E and Secure Diffusion, to make the most of the superb generalization potential of 2D diffusion fashions to allow multi-view supervision. Nevertheless, Many of those approaches necessitate cautious parameter adjustment and regularization, and their output is constrained by the pre-trained 2D generative fashions used within the first place.
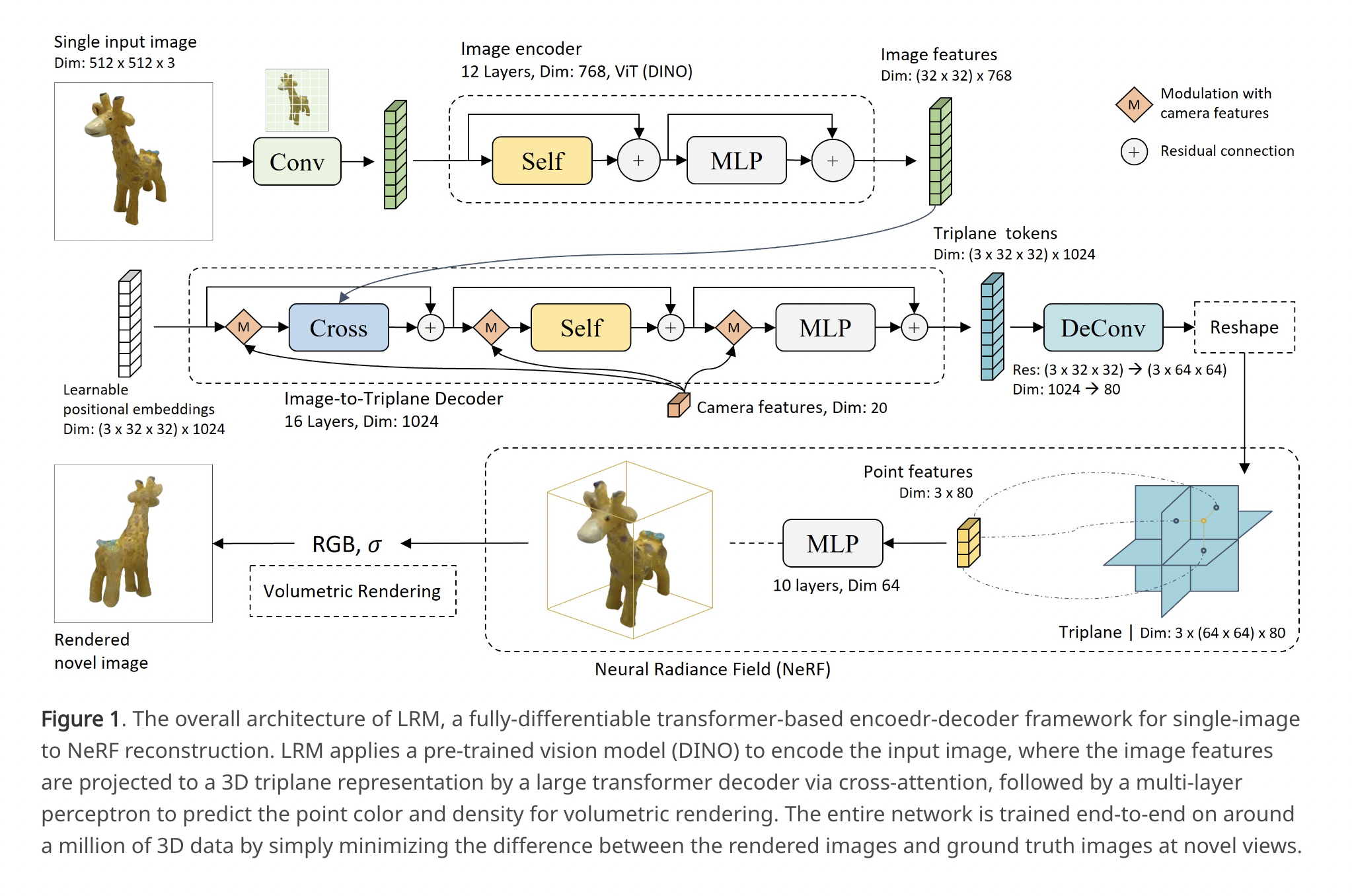
Utilizing a Giant Reconstruction Mannequin (LRM), researchers from Adobe Analysis and the Australian Nationwide College may convert a single picture into 3D. The proposed mannequin makes use of an enormous transformer-based encoder-decoder structure for data-driven 3D object illustration studying from a single picture. When a picture is fed into their system, it outputs a triplane illustration of a NeRF. Particularly, LRM generates picture options utilizing the pre-trained visible transformer DINO because the picture encoder, after which learns an image-to-triplane transformer decoder to undertaking the 2D picture cross-attentionally options onto the 3D triplane, after which self-attentively fashions the relations among the many spatially-structured triplane tokens. The output tokens from the decoder are reshaped and upsampled to the ultimate triplane characteristic maps. After that, they might decode the triplane attribute of every level with an extra shared multi-layer notion (MLP) to acquire its colour and density and perform quantity rendering, permitting us to generate the photographs from any arbitrary viewpoint.
LRM is very scalable and environment friendly on account of its well-designed structure. Triplane NeRFs are computationally pleasant in comparison with different representations like volumes and level clouds, making them a easy and scalable 3D illustration. As well as, its proximity to the image enter is superior to that of Shap-E’s tokenization of the NeRF’s mannequin weights. Moreover, the LRM is skilled by merely minimizing the distinction between the rendered photos and floor reality photos at novel views, with out extreme 3D-aware regularization or delicate hyper-parameter tuning, making the mannequin very environment friendly in coaching and adaptable to all kinds of multi-view picture datasets.
LRM is the primary large-scale 3D reconstruction mannequin, with over 500 million learnable parameters and coaching information consisting of roughly a million 3D shapes and movies from all kinds of classes; it is a vital improve in dimension over more moderen strategies, which make use of comparatively shallower networks and smaller datasets. The experimental outcomes exhibit that LRM can rebuild high-fidelity 3D shapes from real-world and generative mannequin pictures. Moreover, LRM is a really useful gizmo for downsizing.
The group plans to deal with the next areas for his or her future examine:
- Enhance the mannequin’s dimension and coaching information utilizing the only transformer-based design doable with little regularization.
- Prolong it to multi-modal generative fashions in 3D.
A few of the work executed by 3D designers is perhaps automated with the assistance of image-to-3D reconstruction fashions like LRM. It’s additionally essential to notice that these applied sciences can probably improve development and accessibility within the inventive sector.
Take a look at the Paper and Project Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Dhanshree Shenwai is a Pc Science Engineer and has a very good expertise in FinTech corporations protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is keen about exploring new applied sciences and developments in immediately’s evolving world making everybody’s life straightforward.
[ad_2]
Source link