


[ad_1]
Within the present technological panorama, 3D imaginative and prescient has emerged as a star on the rise, capturing the highlight attributable to its fast development and evolution. This surge in curiosity may be largely attributed to the hovering demand for autonomous driving, enhanced navigation methods, superior 3D scene comprehension, and the burgeoning subject of robotics. To increase its utility eventualities, quite a few efforts have been made to include 3D level clouds with information from different modalities, permitting for improved 3D understanding, text-to-3D era, and 3D query answering.

Researchers have launched Level-Bind, a revolutionary 3D multi-modality mannequin designed to seamlessly combine level clouds with numerous information sources reminiscent of 2D pictures, language, audio, and video. Guided by the rules of ImageBind, this mannequin constructs a unified embedding house that bridges the hole between 3D information and multi-modalities. This breakthrough allows a mess of thrilling functions, together with however not restricted to any-to-3D era, 3D embedding arithmetic, and complete 3D open-world understanding.
Within the above picture we will see the general pipeline of Level-Bind. Researchers first acquire 3D-image-audio-text information pairs for contrastive studying, which aligns 3D modality with others guided ImageBind. With a joint embedding house, Level-Bind may be utilized for 3D cross-modal retrieval, any-to-3D era, 3D zero-shot understanding, and creating a 3D massive language mannequin, Level-LLM.
The principle contributions of Level Blind on this research embody:
- Aligning 3D with ImageBind: Inside a joint embedding house, Level-Bind firstly aligns 3D level clouds with multi-modalities guided by ImageBind, together with 2D pictures, video, language, audio, and many others.
- Any-to-3D Era: Based mostly on present textto-3D generative fashions, Level-Bind allows 3D form synthesis conditioned on any modalities, i.e textual content/picture/audio/point-to-mesh era.
- 3D Embedding-space Arithmetic: We observe that 3D options from Level-Bind may be added with different modalities to include their semantics, attaining composed cross-modal retrieval.
- 3D Zero-shot Understanding: Level-Bind attains state-of-the-art efficiency for 3D zero-shot classification. Additionally, our strategy helps audio-referred 3D open-world understanding, moreover textual content reference.
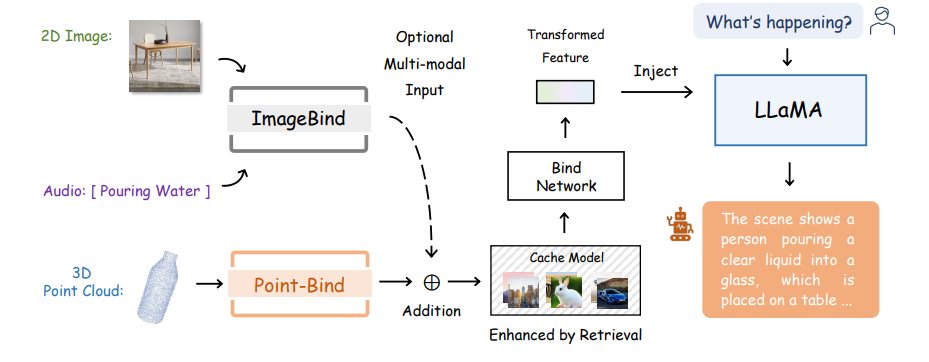
Researchers leverage Level-Bind to develop 3D massive language fashions (LLMs), termed as Level-LLM, which fine-tunes LLaMA to realize 3D query answering and multi-modal reasoning. The general pipeline of Level-LLM may be seen within the above picture.
The principle contributions of Level LLM embody:
- Level-LLM for 3D Query Answering: Utilizing PointBind, we introduce Level-LLM, the primary 3D LLM that responds to directions with 3D level cloud circumstances, supporting each English and Chinese language.
- Information- and Parameter-efficiency: We solely make the most of public vision-language information for tuning with none 3D instruction information, and undertake parameter-efficient finetuning methods, saving in depth sources.
- 3D and Multi-modal Reasoning: By way of the joint embedding house, Level-LLM can generate descriptive responses by reasoning a mix of 3D and multimodal enter, e.g., a degree cloud with a picture/audio.
The longer term work will give attention to aligning multi-modality with extra various 3D information, reminiscent of indoor and outside scenes, which permits for wider utility eventualities.
Try the Paper and Github link. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to hitch our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on this planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
[ad_2]
Source link
