


[ad_1]
These days, there have been important strides in making use of deep neural networks to the search area in machine studying, with a particular emphasis on illustration studying throughout the bi-encoder structure. On this framework, varied kinds of content material, together with queries, passages, and even multimedia, resembling photos, are reworked into compact and significant “embeddings” represented as dense vectors. These dense retrieval fashions, constructed on this structure, function the cornerstone for enhancing retrieval processes inside giant language fashions (LLMs). This strategy has gained recognition and confirmed to be extremely efficient in enhancing the general capabilities of LLMs throughout the broader realm of generative AI in the present day.
The narrative means that because of the have to deal with quite a few dense vectors, enterprises ought to incorporate a devoted “vector retailer” or “vector database” into their “AI stack.” A distinct segment market of startups is actively selling these vector shops as revolutionary and important elements of up to date enterprise structure. Notable examples embody Pinecone, Weaviate, Chroma, Milvus, and Qdrant, amongst others. Some proponents have even gone as far as to suggest that these vector databases may ultimately supplant the longstanding relational databases.
This paper presents a counterpoint to this narrative. The arguments revolve round an easy cost-benefit evaluation, contemplating that search represents an present and established utility in lots of organizations, resulting in important prior investments in these capabilities. The manufacturing infrastructure is dominated by the broad ecosystem centered across the open-source Lucene search library, most notably pushed by platforms resembling Elasticsearch, OpenSearch, and Solr.
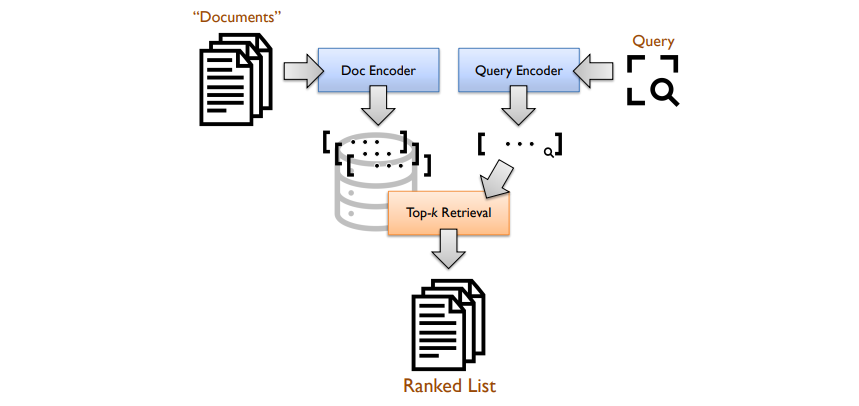
The above picture exhibits a normal bi-encoder structure, the place encoders generate dense vector representations (embeddings) from queries and paperwork (passages). Retrieval is framed as a k-nearest neighbor search in vector area. The experiments centered on the MS MARCO passage rating take a look at assortment, constructed on a corpus comprising roughly 8.8 million passages extracted from the net. The usual improvement queries and queries from the TREC 2019 and TREC 2020 Deep Studying Tracks had been used for analysis.
The findings recommend that it’s potential in the present day to construct a vector search prototype utilizing OpenAI embeddings immediately with Lucene. The rising recognition of embedding APIs helps our arguments. These APIs simplify the complicated technique of producing dense vectors from content material, making it extra accessible to practitioners. Certainly, Lucene is all you want if you find yourself constructing search ecosystems in the present day. However because it occurs, solely time will inform in case you are proper. Lastly, this reminds us that weighing prices vs. advantages will stay a major mindset, even within the quickly evolving AI world.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to hitch our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
[ad_2]
Source link
