


[ad_1]
Constructing synthetic programs that see and acknowledge the world equally to human visible programs is a key purpose of laptop imaginative and prescient. Latest developments in inhabitants mind exercise measurement, together with enhancements within the implementation and design of deep neural community fashions, have made it attainable to immediately examine the architectural options of synthetic networks to these of organic brains’ latent representations, revealing essential particulars about how these programs work. Reconstructing visible pictures from mind exercise, equivalent to that detected by purposeful magnetic resonance imaging (fMRI), is one among these functions. This can be a fascinating however tough downside as a result of the underlying mind representations are largely unknown, and the pattern measurement sometimes used for mind knowledge is small.
Deep-learning fashions and strategies, equivalent to generative adversarial networks (GANs) and self-supervised studying, have just lately been utilized by lecturers to sort out this problem. These investigations, nonetheless, name for both fine-tuning towards the actual stimuli utilized within the fMRI experiment or coaching new generative fashions with fMRI knowledge from scratch. These makes an attempt have demonstrated nice however constrained efficiency when it comes to pixel-wise and semantic constancy, partly as a result of small quantity of neuroscience knowledge and partly as a result of a number of difficulties related to constructing difficult generative fashions.
Diffusion Fashions, significantly the much less computationally resource-intensive Latent Diffusion Fashions, are a latest GAN substitute. But, as LDMs are nonetheless comparatively new, it’s tough to have a whole understanding of how they work internally.
By utilizing an LDM known as Steady Diffusion to reconstruct visible pictures from fMRI indicators, a analysis crew from Osaka College and CiNet tried to handle the problems talked about above. They proposed an easy framework that may reconstruct high-resolution pictures with excessive semantic constancy with out the necessity for complicated deep-learning fashions to be educated or tuned.
The dataset employed by the authors for this investigation is the Pure Scenes Dataset (NSD), which gives knowledge collected from an fMRI scanner throughout 30–40 classes throughout which every topic seen three repeats of 10,000 pictures.
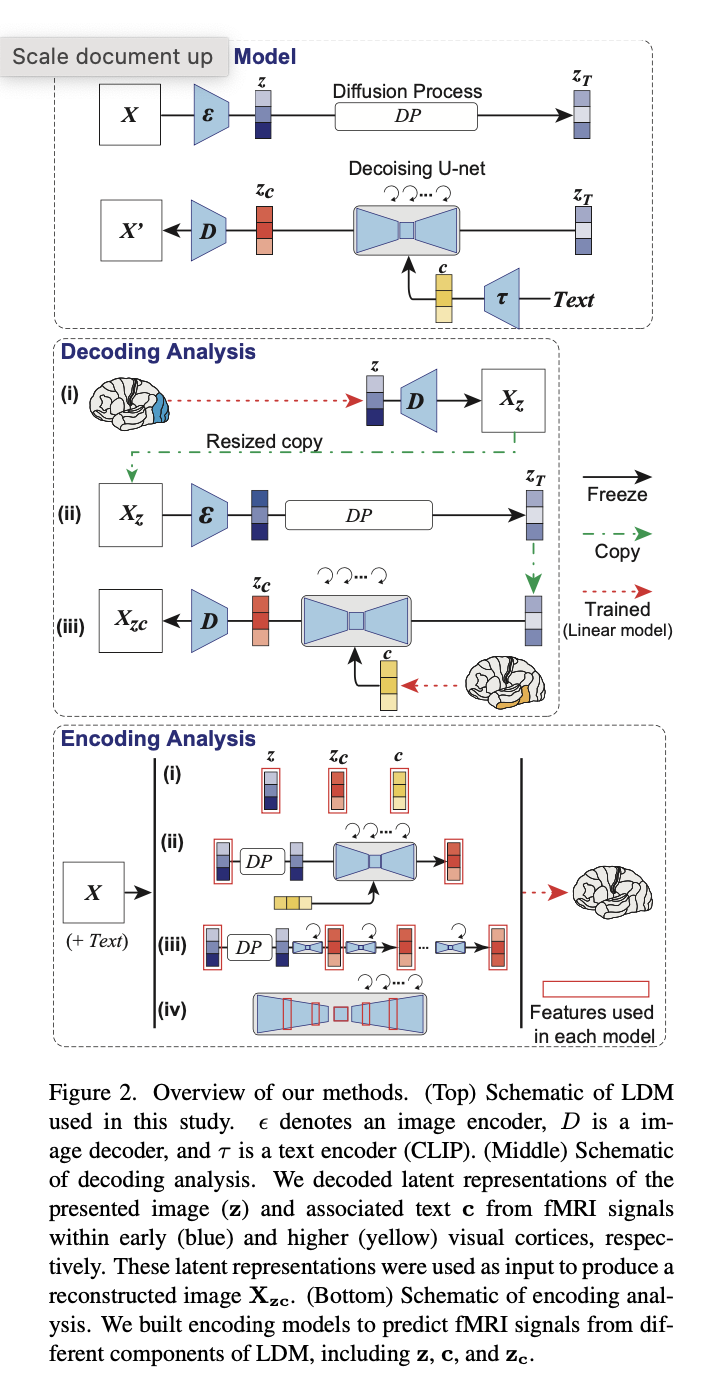
To start, they used a Latent Diffusion Mannequin to create pictures from textual content. Within the determine above (prime), z is outlined because the generated latent illustration of z that has been modified by the mannequin with c, c is outlined because the latent illustration of texts (that describe the photographs), and zc is outlined because the latent illustration of the unique picture that has been compressed by the autoencoder.
To investigate the decoding mannequin, the authors adopted three steps (determine above, center). Firstly, they predicted a latent illustration z of the introduced picture X from fMRI indicators inside the early visible cortex (blue). z was then processed by a decoder to supply a rough decoded picture Xz, which was then encoded and handed by way of the diffusion course of. Lastly, the noisy picture was added to a decoded latent textual content illustration c from fMRI indicators inside the increased visible cortex (yellow) and denoised to supply zc. From, zc a decoding module produced a ultimate reconstructed picture Xzc. It’s essential to underline that the one coaching required for this course of is to linearly map fMRI indicators to LDM elements, zc, z and c.
Ranging from zc, z and c the authors carried out an encoding evaluation to interpret the inner operations of LDMs by mapping them to mind exercise (determine above, backside). The outcomes of reconstructing pictures from representations are proven beneath.

Photos that had been recreated utilizing merely z had a visible consistency with the unique pictures, however their semantic worth was misplaced. Then again, pictures that had been solely partially reconstructed utilizing c yielded pictures that had nice semantic constancy however inconsistent visuals. The validity of this methodology was demonstrated by the flexibility of pictures recovered utilizing zc to supply high-resolution pictures with nice semantic constancy.
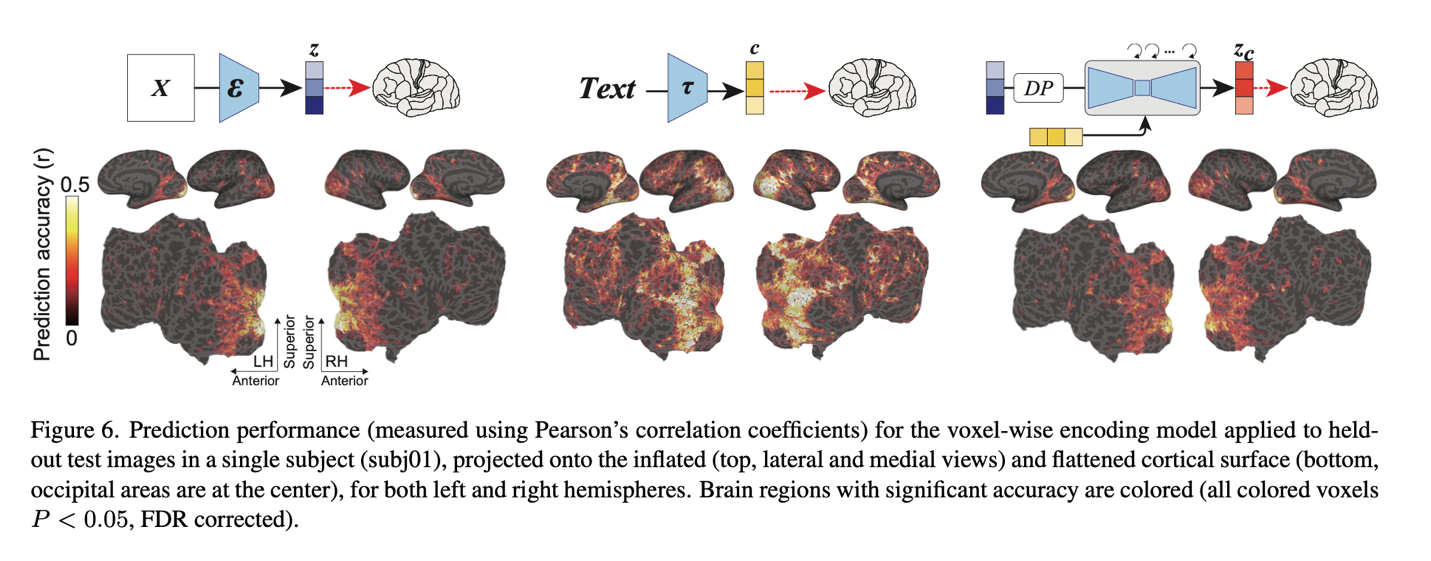
The ultimate evaluation of the mind reveals new details about DM fashions. In the back of the mind, the visible cortex, all three elements achieved nice prediction efficiency. Significantly, z supplied sturdy prediction efficiency within the early visible cortex, which lies behind the visible cortex. Additionally, it demonstrated sturdy prediction values within the higher visible cortex, which is the anterior a part of the visible cortex, however smaller values in different areas. Then again, within the higher visible cortex, c led to the most effective prediction efficiency.
Try the Paper and Project Page. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Leonardo Tanzi is presently a Ph.D. Pupil on the Polytechnic College of Turin, Italy. His present analysis focuses on human-machine methodologies for sensible help throughout complicated interventions within the medical area, utilizing Deep Studying and Augmented Actuality for 3D help.
[ad_2]
Source link
