

[ad_1]
Language modeling, a essential part of pure language processing, includes the event of fashions to course of and generate human language. This area has seen transformative developments with the arrival of enormous language fashions (LLMs). The first problem lies in effectively optimizing these fashions. Distributed coaching with a number of gadgets faces communication latency hurdles, particularly when various in computational capabilities or geographically dispersed.
Historically, Native Stochastic Gradient Descent (Native-SGD), generally known as federated averaging, is utilized in distributed optimization for language modeling. This technique includes every gadget performing a number of native gradient steps earlier than synchronizing their parameter updates to scale back communication frequency. Nevertheless, this strategy may be inefficient because of the straggler impact, the place sooner gadgets stay idle, ready for slower ones to catch up, thus undermining the system’s total effectivity.
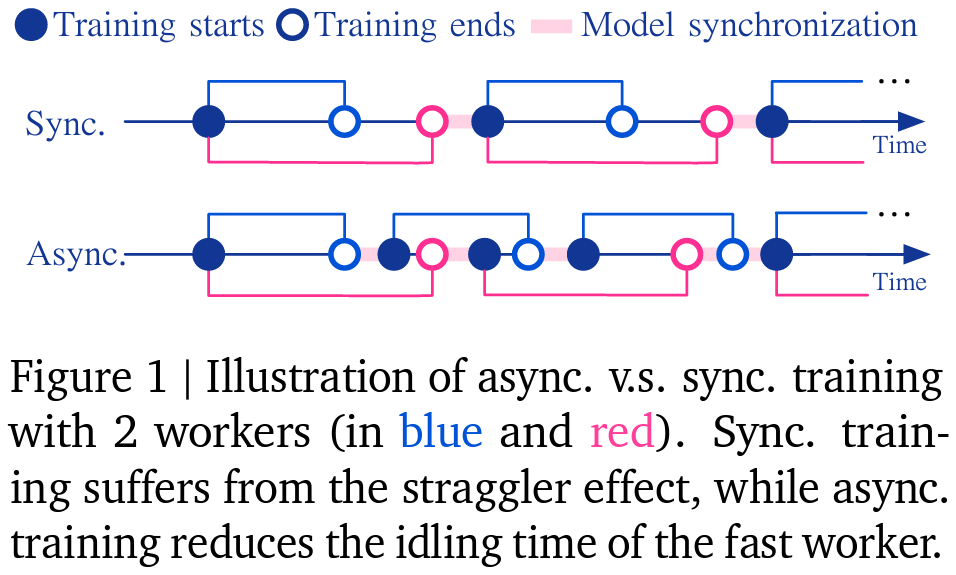
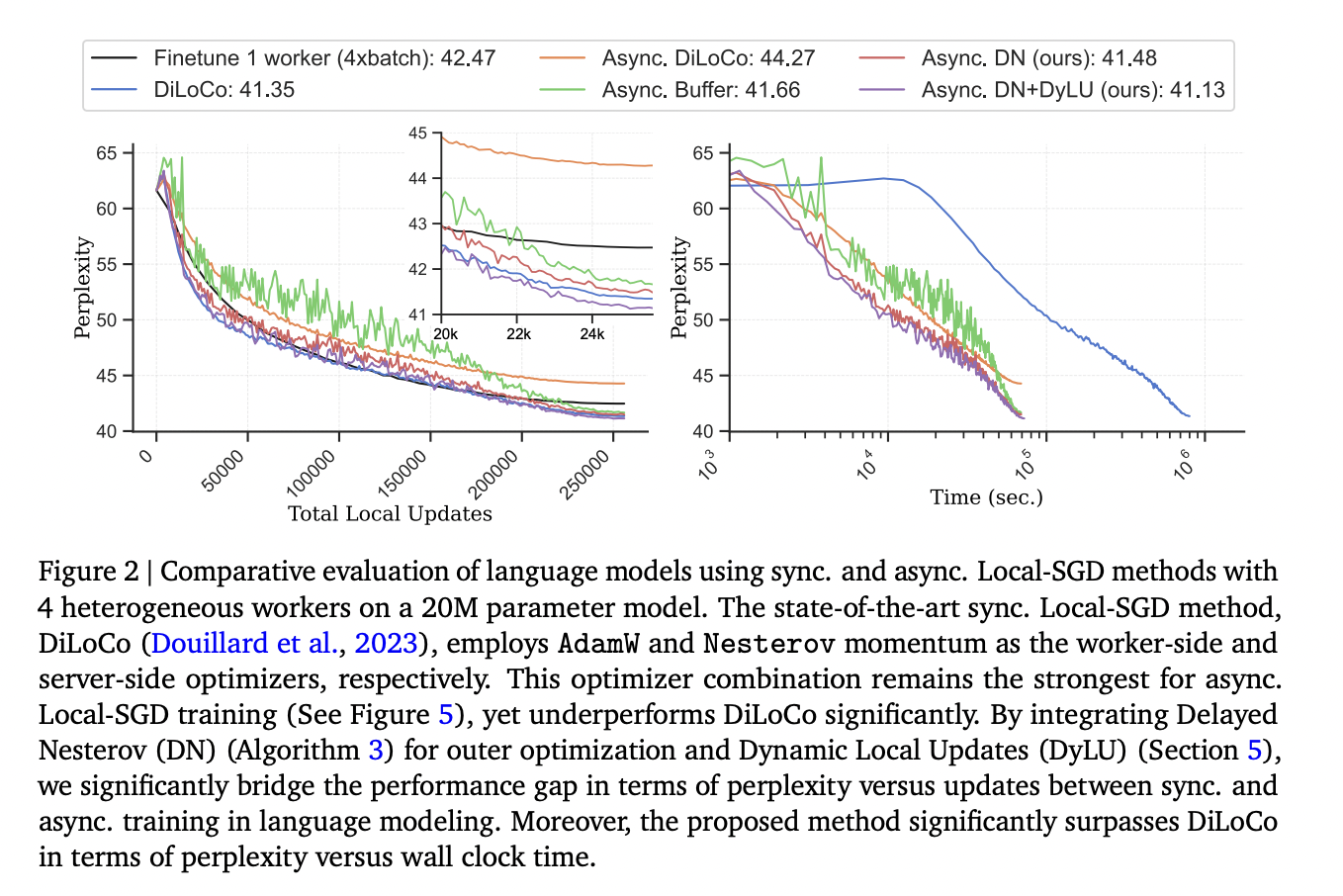
Analysis by DeepMind introduces an revolutionary technique to boost asynchronous Native-SGD for language modeling. This technique updates international parameters asynchronously as employees full their Stochastic Gradient Descent (SGD) steps. By doing so, it seeks to beat the constraints inherent in synchronous Native-SGD, significantly regarding the various computational capabilities of employee {hardware} and completely different mannequin sizes.
The methodology of the proposed strategy is intricate but efficient. It incorporates a delayed Nesterov momentum replace to deal with momentum acceleration, a problem when employee gradients are stale. This system includes adjusting the native coaching steps of employees primarily based on their computation pace, which aligns with the dynamic native updates (DyLU) technique. This adjustment ensures that the educational progress throughout varied information shards is balanced, every with its personal optimized studying price schedule. Such a nuanced strategy to dealing with asynchronous updates is pivotal in managing the complexities of distributed coaching.
The efficiency and outcomes of this technique are notable. Evaluated utilizing fashions with as much as 150M parameters on the C4 dataset, this strategy matched the efficiency of its synchronous counterpart by way of perplexity per replace step. It considerably outperformed it by way of wall clock time. This breakthrough guarantees sooner convergence and larger effectivity, which is essential for large-scale distributed studying. The analysis highlights that with this strategy, the problems of communication latency and inefficiency in synchronization may be successfully mitigated, paving the way in which for extra environment friendly and scalable coaching of language fashions.
This research introduces a novel strategy to asynchronous Native-SGD, which mixes delayed Nesterov momentum updates with dynamic native updates, showcasing vital development in language modeling and addressing key challenges in distributed studying. This technique demonstrates an enchancment in coaching effectivity and holds promise for extra scalable and efficient language mannequin coaching, which is pivotal within the evolution of pure language processing applied sciences.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Overlook to affix our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.

[ad_2]
Source link
