


[ad_1]

Picture from Unsplash by Clément Hélardot
2022 is a superb 12 months for any information individual, particularly those that use Python, as there are lots of thrilling packages to enhance our information capabilities. Numerous must-learn Data Python packages in 2022 have been outlined, and we’d need one thing new to enhance our stack within the new 12 months.
Going through the 12 months 2023, varied Python packages will enhance our information workflow within the new 12 months. What are these packages? Let’s check out my suggestion.
From the information cleansing packages to machine studying implementation, these are the highest information Python packages you wish to know in 2023.
Pyjanitor is an open-source Python package deal developed particularly for information cleansing routines through methodology chaining and was designed to enhance Pandas API for information cleansing.
We all know many Pandas strategies for information cleansing, reminiscent of dropna to take away all of the lacking values. With Pyjanitor, the information cleansing course of with Pandas API can be heightened by introducing extra strategies inside the APIs. How is it work? Let’s check out the package deal with pattern information.
We might use the Titanic training data from the Kaggle licenses below CC0: Public Area for the pattern. Let’s begin by putting in the Pyjanitor package deal.
Set up
Let’s take a look at our present dataset earlier than we do any information cleansing with Pyjanitor.
import pandas as pd
df = pd.read_csv('prepare.csv')
df.head()
Output

Picture by Creator
With the Pyjanitor package deal, we are able to do varied extension information cleansing and implement methodology chains in how Pandas API works. Let’s see how the package deal works with the code beneath.
Code Instance
import janitor
df.remove_columns(["Cabin"]).expand_column(column_name="Embarked").clean_names()
Output

Picture by Creator
By importing the Pyjanitor package deal, it might robotically be applied inside the Pandas DataFrame. In our code above, we have now performed the next issues utilizing Pyjanitor:
- Take away the ‘Cabin’ columns utilizing the remove_columns methodology,
- Categorical Encoding (One-Sizzling Encoding) processing to the ‘Embarked’ column utilizing expand_column methodology,
- Convert all of the variable header names to lowercase, and if there are areas will probably be changed with underscores utilizing the clean_names methodology.
There are nonetheless so many features in Pyjanitor we may use for information cleansing. Please consult with their documentation for an entire API checklist.
Pingouin is a statistical evaluation open-source Python package deal used for any frequent statistic exercise for any information scientist. The package deal was designed for simplicity by offering a one-liner code however nonetheless offering varied statistical exams for use.
Set up
Having put in the package deal, let’s attempt to carry out statistical evaluation with Pingouin. For instance, we might do a T-test and ANOVA take a look at utilizing the earlier Titanic dataset.
Code Instance
import pingouin as pg
#T-Check
print('T-Check instance')
pg.ttest( df['Age'], df['Fare'])
print('n')
# ANOVA take a look at
print('ANOVA take a look at instance')
pg.anova(information=df, dv='Age', between='SibSp', detailed=True)
Output
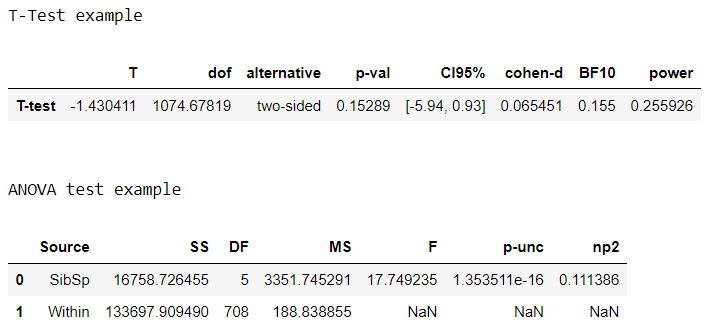
Picture by Creator
With a single line, Pingouin present the statistical take a look at consequence within the information body object. There are lots of extra features to assist our evaluation, which we are able to discover within the Pingouin APIs documentation.
PyCaret is an open-source Python package deal developed for automating the machine studying workflow. The package deal offers a low-code setting to hasten the mannequin experiment by delivering an end-to-end machine-learning mannequin software.
In typical information science work, many actions exist, reminiscent of cleansing our information, choosing a mannequin, doing hyperparameter tuning, and evaluating the mannequin. PyCaret intends to remove all the trouble by minimizing all of the required codes into as few strains as potential. The package deal is a group of a number of machine studying frameworks into one. Let’s check out PyCaret to know extra.
Set up
Utilizing the earlier Titanic dataset; we might develop a mannequin classifier to foretell the “Survive” variable.
Code Instance
from pycaret.classification import *
clf_exp = setup(information = df, goal="Survived")
Output
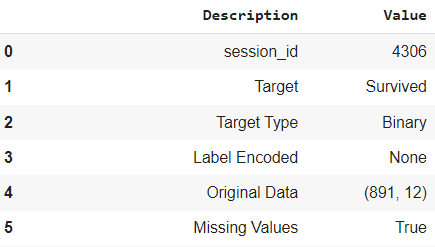
Picture by Creator
Within the above code, we provoke the experiment utilizing the setup perform. By passing the information and the goal, PyCaret would infer our information and develop a machine-learning mannequin based mostly on the given information. The precise output info is longer than the above picture and is insightful to what occurred in our modeling course of.
Let’s take a look at the mannequin consequence and infer the most effective mannequin from the coaching information.
best_model = compare_models(kind="precision")
Output
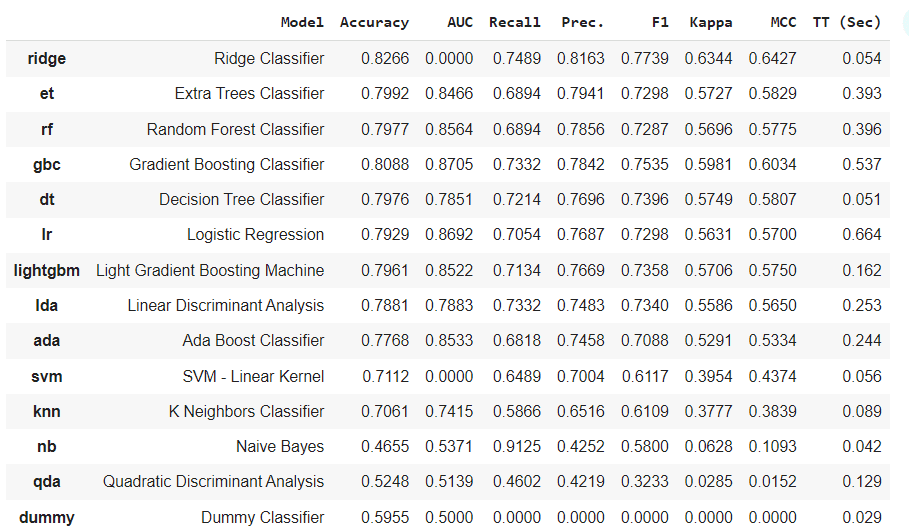
Picture by Creator
Output
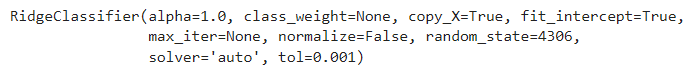
Picture by Creator
The PyCaret classifier experiment would take a look at the coaching information into 14 totally different classifiers and provides the most effective mannequin. In our case, it’s the RidgeClassifier.
There are nonetheless many experiments you could possibly do with PyCaret. To discover extra, please consult with their documentation.
BentoML is an open-source Python package deal for shortly serving the mannequin into manufacturing and with as few strains as potential. The package deal supposed to deal with the productional machine studying mannequin to be simply utilized by the person.
Let’s check out the BentoML package deal and study the way it works.
Set up
For the BentoML instance, we might use the code from the package tutorial with a bit of modification.
Code Instance
We might prepare the mannequin classifier utilizing the iris dataset.
from sklearn import svm, datasets
iris = datasets.load_iris()
X, y = iris.information, iris.goal
iris_clf = svm.SVC()
iris_clf.match(X, y)
With BentoML, we may retailer our machine studying mannequin within the native or cloud mannequin retailer and retrieve it for manufacturing.
import bentoml
bentoml.sklearn.save_model("iris_clf", iris_clf)
Then we may use the saved mannequin within the BentoML setting utilizing the runner occasion.
# Create a Runner occasion and implement a runner occasion in native
iris_clf_runner = bentoml.sklearn.get("iris_clf:newest").to_runner()
iris_clf_runner.init_local()
# Utilizing the predictor on unseen information
iris_clf_runner.predict.run([[4.1, 2.3, 5.5, 1.8]])
Output
Subsequent; we may provoke the mannequin service saved within the BentoML by operating the next code to create a Python file and begin the server.
%%writefile service.py
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:newest").to_runner()
svc = bentoml.Service("iris_clf_service", runners=[iris_clf_runner])
@svc.api(enter=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
return iris_clf_runner.predict.run(input_series)
We begin the server by operating the code beneath.
!bentoml serve service.py:svc --reload
Output

Picture by Creator
The output would present the present log of the event server and the place we may entry it. If we’re glad with the event consequence, we may transfer on to manufacturing. I like to recommend you consult with the documentation for the manufacturing course of.
Streamlit is an open-source Python package deal to create a customized internet app for information scientists. The package deal offers insightful code to construct and customise varied information apps. Let’s attempt the package deal to study the way it works.
Set up
Streamlit internet app is operating by executing the Python script utilizing the streamlit. That’s the reason we have to put together the script earlier than operating it utilizing the streamlit command earlier than operating it. We are able to run the subsequent pattern utilizing your favourite IDE or Jupyter Pocket book, however I might present how we create the net app with Streamlit in our Jupyter Pocket book.
Code Instance
%%writefile streamlit_example.py
import streamlit as st
import pandas as pd
import numpy as np
st.title('Titanic Knowledge')
information = pd.read_csv('prepare.csv')
st.write('Reveals high 5 of the information')
st.dataframe(information.head())
st.title('Bar Chart Visualization with Age')
col = st.selectbox('Choose the specific columns', information.select_dtypes('object').columns)
st.bar_chart(information, x = col, y='Age')
The above code would create a script referred to as streamlit_example.py and create an online app just like the output beneath if we run the Streamlit command.
!streamlit run streamlit_example.py
Picture by Creator
The code is straightforward to study and would take no time in any respect so that you can create your internet app with Streamlit. You possibly can consult with the documentation if you wish to know extra about what you could possibly create with the Streamlit package deal.
Going through the 12 months 2023, we must always enhance our information skillset higher than in 2022. What higher method so as to add our information arsenal than by studying from wonderful Python packages that may assist improve our information workflow. These high Python packages are
- Pyjanitor
- Pingouin
- PyCaret
- BentoML
- Streamlit
Cornellius Yudha Wijaya is a knowledge science assistant supervisor and information author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Knowledge suggestions through social media and writing media.
[ad_2]
Source link
