

[ad_1]
Programs like ChatGPT, Bard, Bing Chat, and Claude can reply numerous consumer queries, present pattern code, and even produce poetry because of massive language fashions (LLMs).
Essentially the most highly effective LLMs sometimes demand intensive computing sources for coaching and thus necessitate the utilization of massive, non-public datasets. The open-source fashions in all probability gained’t be as highly effective because the closed-source ones, however with the best coaching information, they may be capable to come shut. Smaller open-source fashions will be vastly improved with the right information, as evidenced by initiatives like Stanford’s Alpaca, which fine-tunes LLaMA utilizing OpenAI’s GPT mannequin information.
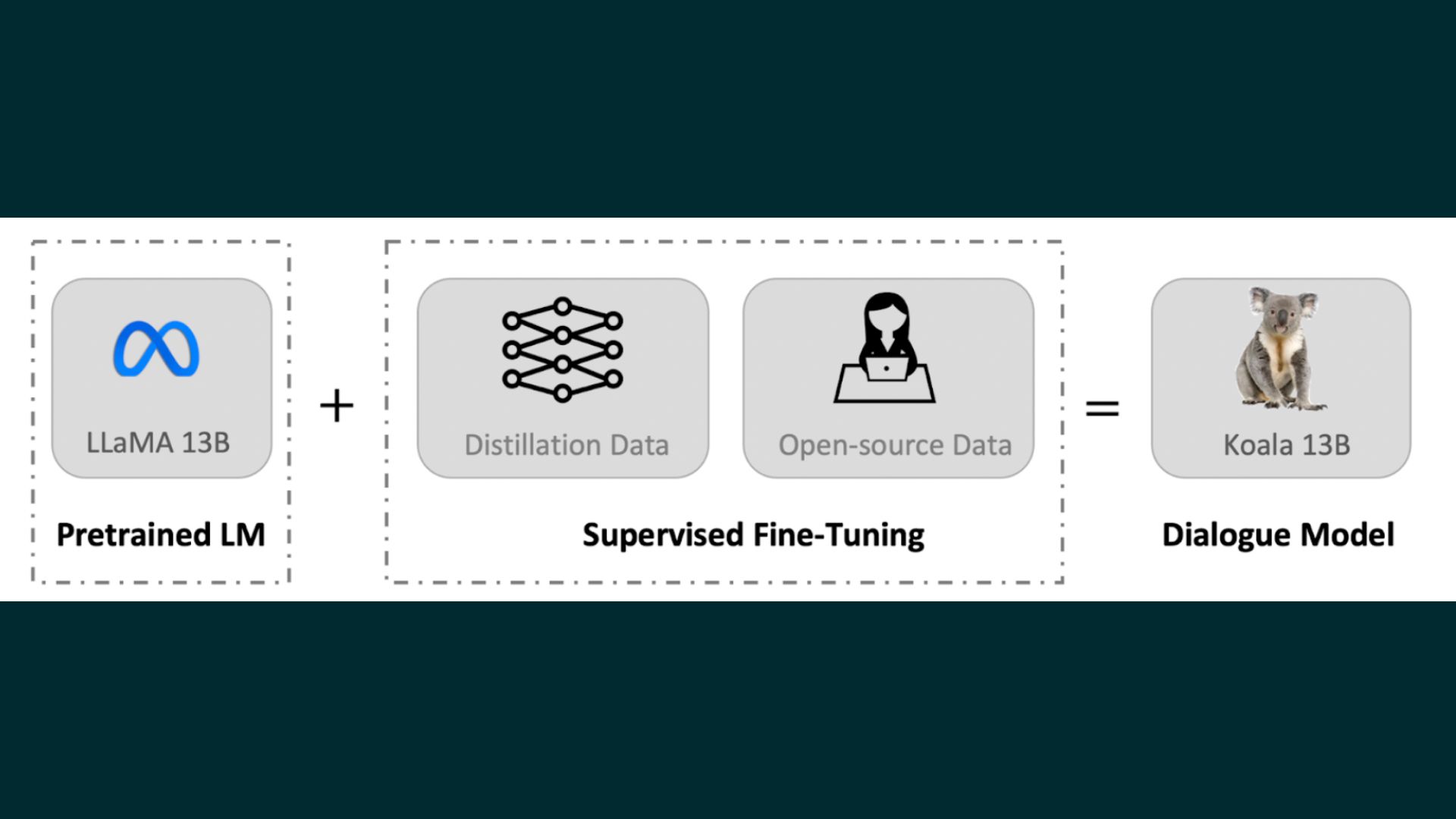
A current UC Berkely AI analysis presents a novel mannequin known as Koala. Koala is skilled utilizing information that features interplay with succesful closed-source fashions like ChatGPT. This information is on the market on the net and utilized in coaching. Utilizing on-line scraped dialogue information, question-answering datasets, and human suggestions datasets. The researchers fine-tune a LLaMA base mannequin. The datasets embody high-quality responses to consumer inquiries from current huge language fashions.
Coaching information curation is a serious roadblock in growing conversational AI. Many current chat fashions use customized datasets that require intensive human annotation. Koala’s coaching set was hand-picked by scouring the web and public sources for conversational information. Conversations between customers and huge language fashions (like ChatGPT) are included on this information set.
As a substitute of attempting to get as a lot information as potential from the net, the workforce selected high quality over amount. Query-answering, human suggestions (evaluated each favorably and negatively), and conversations with preexisting language fashions have been all carried out utilizing publicly obtainable datasets.
The workforce ran trials to match two fashions, one which depends solely on distillation information (Koala-Distill) and one other that makes use of all obtainable information (Koala-All), together with distillation information and open-source information. They study how nicely these fashions perform and assess how a lot of an affect distillation and public datasets have on last outcomes. They put Koala-All via its paces towards Koala-Distill, Alpaca, and ChatGPT in a human analysis.
The Alpaca mannequin’s coaching information is discovered within the Alpaca take a look at set, which includes consultant consumer prompts taken from the self-instruct dataset. Additionally they present their (Koala) take a look at set, comprised of 180 precise consumer queries submitted on-line, to provide a second, extra reasonable analysis course of. These questions come from a variety of customers and are written in a pure, conversational tone; they’re extra indicative of how individuals use chat-based companies. Utilizing these two units of analysis information, the researchers requested roughly 100 evaluators to match the standard of mannequin outputs on these hidden units of duties utilizing the Amazon Mechanical Turk platform.
Koala-All carried out simply in addition to Alpaca did on the Alpaca take a look at set. Alternatively, Koala-All was scored as higher than Alpaca in practically half of the instances and both exceeded or tied to Alpaca in 70% of the instances, based mostly on the proposed take a look at set, which includes real buyer questions.
The workforce talked about that as a result of fine-tuning dialogue, Koala might hallucinate and make non-factual feedback with a extremely assured tone. If so, then future analysis wants to research the potential disadvantage of smaller fashions inheriting the assured type of larger language fashions earlier than inheriting the identical stage of factuality.
This text relies on the BAIR Blog on Koala and its Demo. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Know-how(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in numerous fields. She is enthusiastic about exploring the brand new developments in applied sciences and their real-life utility.
[ad_2]
Source link
