


[ad_1]

Picture by Editor
As you’re scanning via your timeline on Twitter, LinkedIn or information feeds – you’re most likely seeing one thing about chatbots, LLMs, and GPT. Lots of people are talking about LLMs, as new ones are getting launched each week.
As we at present dwell amid the AI revolution, you will need to perceive that plenty of these new functions depend on vector embedding. So let’s be taught extra about vector databases and why they’re vital to LLMs.
Let’s first outline vector embedding. Vector embedding is a sort of knowledge illustration that carries semantic info that helps AI programs get a greater understanding of the info in addition to with the ability to keep long-term reminiscence. With something new you’re making an attempt to be taught, the vital parts are understanding the subject and remembering it.
Embeddings are generated by AI fashions, akin to LLMs which include a lot of options that makes their illustration tough to handle. Embedding represents the totally different dimensions of the info, to assist AI fashions perceive totally different relationships, patterns, and hidden constructions.
Vector embedding utilizing conventional scalar-based databases is a problem, because it can’t deal with or sustain with the dimensions and complexity of the info. With all of the complexity that comes with vector embedding, you possibly can think about the specialised database it requires. That is the place vector databases come into play.
Vector databases provide optimized storage and question capabilities for the distinctive construction of vector embeddings. They supply straightforward search, excessive efficiency, scalability, and information retrieval all by evaluating values and discovering similarities between each other.
That sounds nice, proper? There’s an answer to coping with the advanced construction of vector embeddings. Sure, however no. Vector databases are very tough to implement.
Till now, vector databases had been solely utilized by tech giants that had the capabilities to not solely develop them but additionally have the ability to handle them. Vector databases are costly, due to this fact guaranteeing that they’re correctly calibrated is vital to offer excessive efficiency.
How do Vector Databases work?
So now we all know a bit bit about vector embeddings and databases, let’s go into the way it works.
Picture by Writer
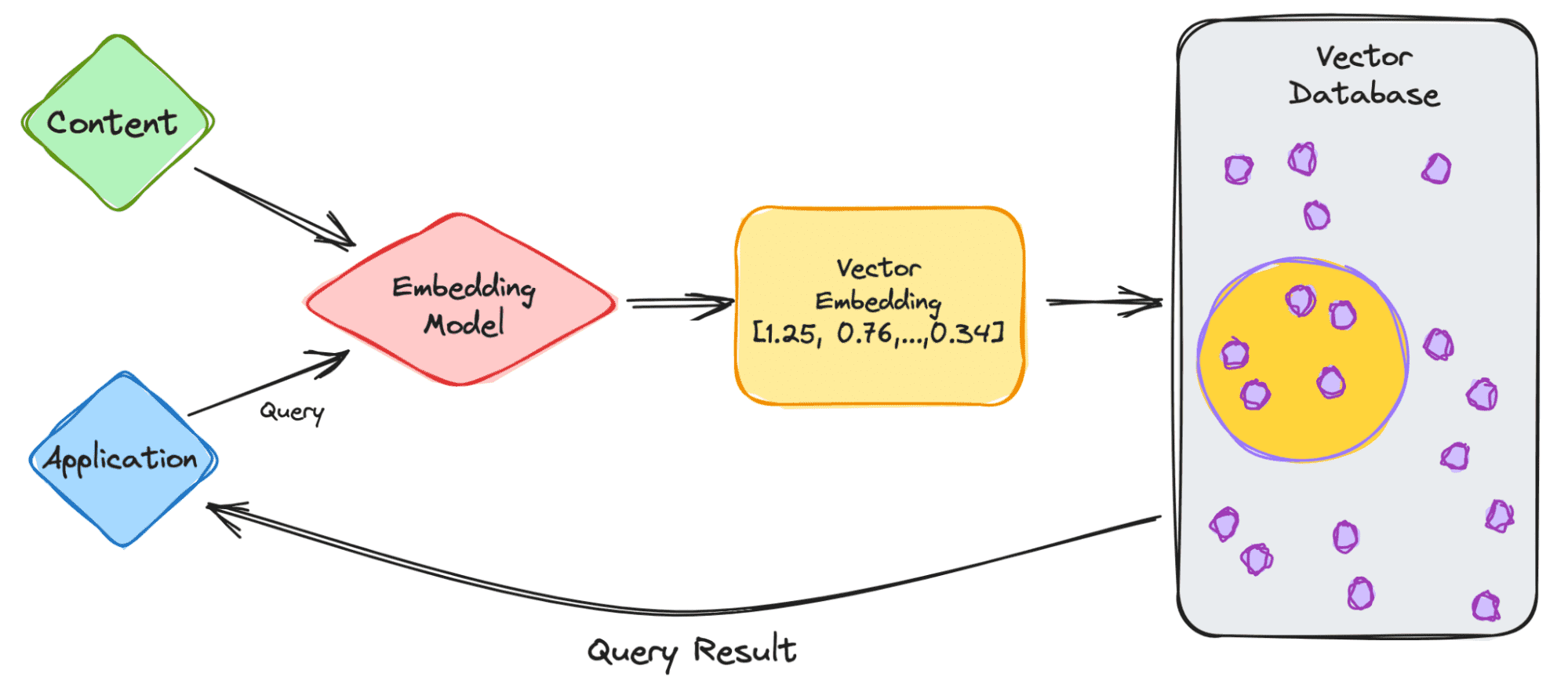
Let’s begin with a easy instance of coping with an LLM akin to ChatGPT. The mannequin has massive volumes of knowledge with plenty of content material, they usually present us with the ChatGPT utility.
So let’s undergo the steps.
- Because the person, you’ll enter your question into the appliance.
- Your question is then inserted into the embedding mannequin which creates vector embeddings primarily based on the content material we need to index.
- The vector embedding then strikes into the vector database, concerning the content material that the embedding was created from.
- The vector database produces an output and sends it again to the person as a question outcome.
When the person continues to make queries, it should undergo the identical embedding mannequin to create embeddings to question that database for comparable vector embeddings. The similarities between the vector embeddings are primarily based on the unique content material, by which the embedding was created.
Need to know extra about the way it works within the vector database? Let’s be taught extra.
Picture by Writer
Conventional databases work with storing strings, numbers, and so on in rows and columns. When querying from conventional databases, we’re querying for rows that match our question. Nevertheless, vector databases work with vectors slightly than strings, and so on. Vector databases additionally apply a similarity metric which is used to assist discover a vector most just like the question.
A vector database is made up of various algorithms which all support within the Approximate Nearest Neighbor (ANN) search. That is performed through hashing, graph-based search, or quantization that are assembled right into a pipeline to retrieve neighbors of a queried vector.
The outcomes are primarily based on how shut or approximate it’s to the question, due to this fact the principle parts which might be thought-about are accuracy and pace. If the question output is sluggish, the extra correct the outcome.
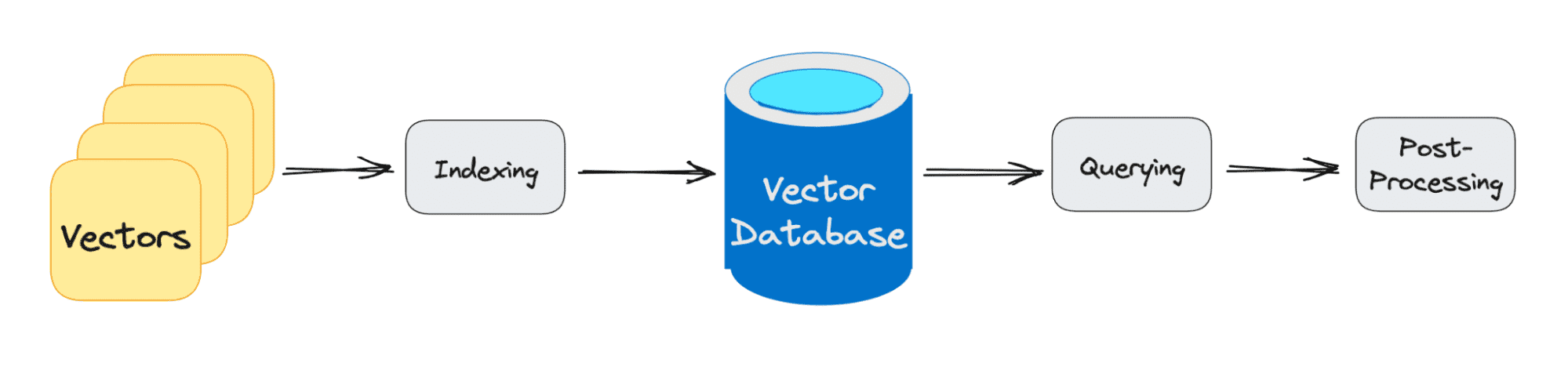
The three principal levels {that a} vector database question goes via are:
1. Indexing
As defined within the instance above, as soon as the vector embedding strikes into the vector database, it then makes use of quite a lot of algorithms to map the vector embedding to information constructions for sooner looking.
2. Querying
As soon as it has gone via its search, the vector database compares the queried vector to listed vectors, making use of the similarity metric to seek out the closest neighbor.
3. Submit Processing
Relying on the vector database you utilize, the vector database will post-process the ultimate nearest neighbor to supply a last output to the question. In addition to presumably re-ranking the closest neighbors for future reference.
As we proceed to see AI develop and new programs getting launched each week, the expansion in vector databases is taking part in a giant function. Vector databases have allowed firms to work together extra successfully with correct similarity searches, offering higher and sooner outputs for customers.
So subsequent time you’re placing in a question in ChatGPT or Google Bard, take into consideration the method it goes via to output a outcome to your question.
Nisha Arya is a Information Scientist, Freelance Technical Author and Neighborhood Supervisor at KDnuggets. She is especially all in favour of offering Information Science profession recommendation or tutorials and idea primarily based data round Information Science. She additionally needs to discover the alternative ways Synthetic Intelligence is/can profit the longevity of human life. A eager learner, in search of to broaden her tech data and writing abilities, while serving to information others.
[ad_2]
Source link
