

[ad_1]
Right here’s a preferred story about momentum
This commonplace story isn’t fallacious, however it fails to clarify many essential behaviors of momentum. Actually, momentum could be understood way more exactly if we research it on the correct mannequin.
One good mannequin is the convex quadratic. This mannequin is wealthy sufficient to breed momentum’s native dynamics in actual issues, and but easy sufficient to be understood in closed kind. This stability offers us highly effective traction for understanding this algorithm.
We start with gradient descent. The algorithm has many virtues, however pace will not be considered one of them. It’s easy — when optimizing a easy perform
For a step-size sufficiently small, gradient descent makes a monotonic enchancment at each iteration. It at all times converges, albeit to a neighborhood minimal. And beneath a number of weak curvature situations it could even get there at an exponential charge.
However the exponential lower, although interesting in principle, can usually be infuriatingly small. Issues usually start fairly nicely — with a powerful, nearly rapid lower within the loss. However because the iterations progress, issues begin to decelerate. You begin to get a nagging feeling you’re not making as a lot progress as you ought to be. What has gone fallacious?
The issue could possibly be the optimizer’s outdated nemesis, pathological curvature. Pathological curvature is, merely put, areas of
Momentum proposes the next tweak to gradient descent. We give gradient descent a short-term reminiscence:
The change is harmless, and prices nearly nothing. When
Optimizers name this minor miracle “acceleration”.
The brand new algorithm could appear at first look like an affordable hack. A easy trick to get round gradient descent’s extra aberrant habits — a smoother for oscillations between steep canyons. However the fact, if something, is the opposite manner spherical. It’s gradient descent which is the hack. First, momentum offers as much as a quadratic speedup on many features.
However there’s extra. A decrease certain, courtesy of Nesterov
First Steps: Gradient Descent
We start by finding out gradient descent on the only mannequin attainable which isn’t trivial — the convex quadratic,
Assume
Easy as this mannequin could also be, it’s wealthy sufficient to approximate many features (consider
That is the way it goes. Since
Right here’s the trick. There’s a very pure area to view gradient descent the place all the size act independently — the eigenvectors of
Each symmetric matrix
and, as per conference, we’ll assume that the
Transferring again to our unique area
and there we have now it — gradient descent in closed kind.
Decomposing the Error
The above equation admits a easy interpretation. Every ingredient of
For many step-sizes, the eigenvectors with largest eigenvalues converge the quickest. This triggers an explosion of progress within the first few iterations, earlier than issues decelerate because the smaller eigenvectors’ struggles are revealed. By writing the contributions of every eigenspace’s error to the loss
Step-size
Optimum Step-size
Selecting A Step-size
The above evaluation offers us rapid steering as to learn how to set a step-size
The general convergence charge is set by the slowest error element, which should be both
This total charge is minimized when the charges for
Discover the ratio
Instance: Polynomial Regression
The above evaluation reveals an perception: all errors usually are not made equal. Certainly, there are completely different sorts of errors,
Lets see how this performs out in polynomial regression. Given 1D information,
to our observations,
Due to the linearity, we are able to match this mannequin to our information
The trail of convergence, as we all know, is elucidated after we view the iterates within the area of
This mannequin is similar to the outdated one. However these new options
The observations within the above diagram could be justified mathematically. From a statistical perspective, we want a mannequin which is, in some sense, sturdy to noise. Our mannequin can’t presumably be significant if the slightest perturbation to the observations modifications your complete mannequin dramatically. And the eigenfeatures, the principal parts of the info, give us precisely the decomposition we have to type the options by its sensitivity to perturbations in
This measure of robustness, by a fairly handy coincidence, can also be a measure of how simply an eigenspace converges. And thus, the “pathological instructions” — the eigenspaces which converge the slowest — are additionally these that are most delicate to noise! So beginning at a easy preliminary level like
This impact is harnessed with the heuristic of early stopping : by stopping the optimization early, you possibly can usually get higher generalizing outcomes. Certainly, the impact of early stopping is similar to that of extra standard strategies of regularization, resembling Tikhonov Regression. Each strategies attempt to suppress the parts of the smallest eigenvalues straight, although they make use of completely different strategies of spectral decay.
The Dynamics of Momentum
Let’s flip our consideration again to momentum. Recall that the momentum replace is
Since
Following
through which every element acts independently of the opposite parts (although
This method is fairly sophisticated, however the takeaway right here is that it performs the very same position the person convergence charges,
Convergence Fee
For what values of
We recuperate the earlier end result for gradient descent when
The Crucial Damping Coefficient
The true magic occurs, nevertheless, after we discover the candy spot of
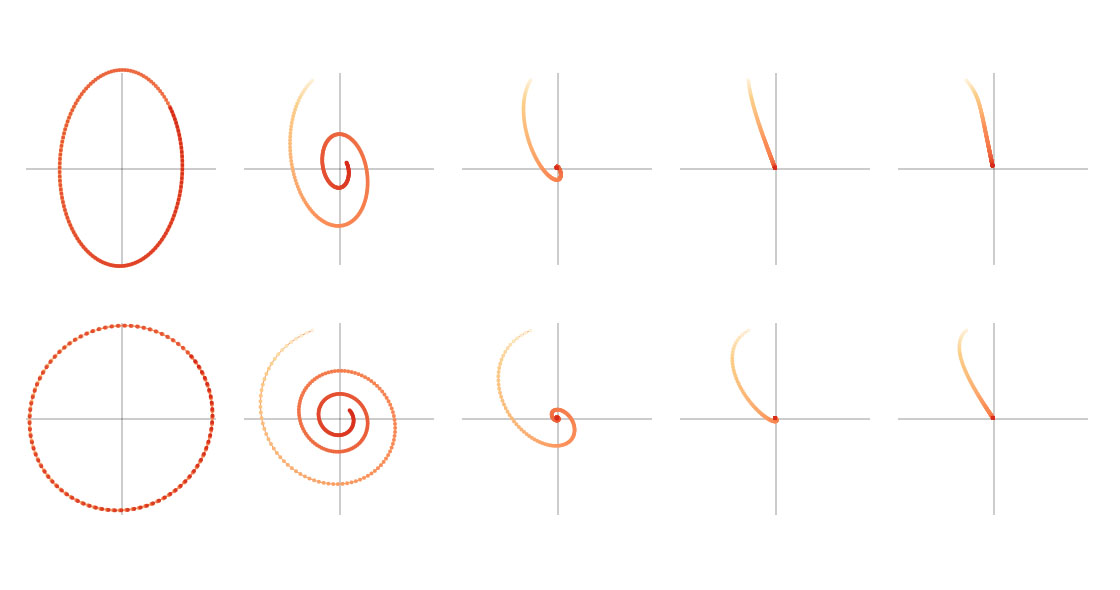
Momentum admits an fascinating bodily interpretation when
We are able to break this equation aside to see how every element impacts the dynamics of the system. Right here we plot, for
This method is greatest imagined as a weight suspended on a spring. We pull the load down by one unit, and we research the trail it follows because it returns to equilibrium. Within the analogy, the spring is the supply of our exterior pressure
The crucial worth of
Optimum parameters
To get a world convergence charge, we should optimize over each
With barely a modicum of additional effort, we have now basically sq. rooted the situation quantity! These positive aspects, in precept, require express information of
Step-size α =
Momentum β =
Whereas the loss perform of gradient descent had a swish, monotonic curve, optimization with momentum shows clear oscillations. These ripples usually are not restricted to quadratics, and happen in all types of features in observe. They don’t seem to be trigger for alarm, however are a sign that further tuning of the hyperparameters is required.
Instance: The Colorization Drawback
Let’s take a look at how momentum accelerates convergence with a concrete instance. On a grid of pixels let
The optimum resolution to this drawback is a vector of all
This type of native averaging is efficient at smoothing out native variations within the pixels, however poor at making the most of world construction. The updates are akin to a drop of ink, diffusing via water. Motion in direction of equilibrium is made solely via native corrections and so, left undisturbed, its march in direction of the answer is sluggish and laborious. Happily, momentum speeds issues up considerably.
In vectorized kind, the colorization drawback is
The Laplacian matrix,
These observations carry via to the colorization drawback, and the instinct behind it must be clear. Properly linked graphs enable speedy diffusion of knowledge via the perimeters, whereas graphs with poor connectivity don’t. And this precept, taken to the intense, furnishes a category of features so exhausting to optimize they reveal the boundaries of first order optimization.
The Limits of Descent
Let’s take a step again. We now have, with a intelligent trick, improved the convergence of gradient descent by a quadratic issue with the introduction of a single auxiliary sequence. However is that this the very best we are able to do? May we enhance convergence much more with two sequences? May one maybe select the
Sadly, whereas enhancements to the momentum algorithm do exist, all of them run right into a sure, crucial, nearly inescapable decrease certain.
Adventures in Algorithmic Area
To know the boundaries of what we are able to do, we should first formally outline the algorithmic area through which we’re looking. Right here’s one attainable definition. The commentary we’ll make is that each gradient descent and momentum could be “unrolled”. Certainly, since
w^{okay+1} & != & !w^{0} ~-~ alphanabla f(w^{0}) ~-~~~~ cdotscdots ~~~~-~ alphanabla f(w^{okay})
finish{array}
The same trick could be finished with momentum:
Actually, all method of first order algorithms, together with the Conjugate Gradient algorithm, AdaMax, Averaged Gradient and extra, could be written (although not fairly so neatly) on this unrolled kind. Due to this fact the category of algorithms for which
accommodates momentum, gradient descent and an entire bunch of different algorithms you may dream up. That is what’s assumed in Assumption 2.1.4
This class of strategies covers many of the common algorithms for coaching neural networks, together with ADAM and AdaGrad. We will discuss with this class of strategies as “Linear First Order Strategies”, and we’ll present a single perform all these strategies in the end fail on.
The Resisting Oracle
Earlier, after we talked concerning the colorizer drawback, we noticed that wiry graphs trigger unhealthy conditioning in our optimization drawback. Taking this to its excessive, we are able to take a look at a graph consisting of a single path — a perform so badly conditioned that Nesterov referred to as a variant of it “the worst perform on this planet”. The perform follows the identical construction because the colorizer drawback, and we will name this the Convex Rosenbrock,
The optimum resolution of this drawback is
and the situation variety of the issue
Step-size α =
Momentum β =
Error
Weights
The observations made within the above diagram are true for any Linear First Order algorithm. Allow us to show this. First observe that every element of the gradient relies upon solely on the values straight earlier than and after it:
Due to this fact the actual fact we begin at 0 ensures that that element should stay stoically there until a component both earlier than or after it turns nonzero. And subsequently, by induction, for any linear first order algorithm,
Consider this restriction as a “pace of sunshine” of knowledge switch. Error indicators will take at the least
As
Like many such decrease bounds, this end result should not be taken actually, however spiritually. It, maybe, offers a way of closure and finality to our investigation. However this isn’t the ultimate phrase on first order optimization. This decrease certain doesn’t preclude the chance, for instance, of reformulating the issue to vary the situation quantity itself! There may be nonetheless a lot room for speedups, when you perceive the correct locations to look.
Momentum with Stochastic Gradients
There’s a last level price addressing. All of the dialogue above assumes entry to the true gradient — a luxurious seldom afforded in trendy machine studying. Computing the precise gradient requires a full move over all the info, the price of which could be prohibitively costly. As an alternative, randomized approximations of the gradient, like minibatch sampling, are sometimes used as a plug-in alternative of
If the estimator is unbiased e.g.
It’s useful to think about our approximate gradient because the injection of a particular sort of noise into our iteration. And utilizing the equipment developed within the earlier sections, we are able to take care of this further time period straight. On a quadratic, the error time period cleaves cleanly right into a separate time period, the place
The error time period,
Step-size α =
Momentum β =
Notice that there are a set of unlucky tradeoffs which appear to pit the 2 parts of error towards one another. Reducing the step-size, for instance, decreases the stochastic error, but in addition slows down the speed of convergence. And rising momentum, opposite to common perception, causes the errors to compound. Regardless of these undesirable properties, stochastic gradient descent with momentum has nonetheless been proven to have aggressive efficiency on neural networks. As
Onwards and Downwards
The research of acceleration is seeing a small revival throughout the optimization neighborhood. If the concepts on this article excite you, it’s possible you’ll want to learn
Acknowledgments
I’m deeply indebted to the editorial contributions of Shan Carter and Chris Olah, with out which this text could be significantly impoverished. Shan Carter offered full redesigns of a lot of my unique interactive widgets, a visible coherence for all of the figures, and invaluable optimizations to the web page’s efficiency. Chris Olah offered impeccable editorial suggestions in any respect ranges of element and abstraction – from the construction of the content material, to the alignment of equations.
I’m additionally grateful to Michael Nielsen for offering the title of this text, which actually tied the article collectively. Marcos Ginestra offered editorial enter for the earliest drafts of this text, and religious encouragement after I wanted it essentially the most. And my gratitude extends to my reviewers, Matt Hoffman and Nameless Reviewer B for his or her astute observations and criticism. I want to thank Reviewer B, specifically, for stating two non-trivial errors within the unique manuscript (dialogue here). The contour plotting library for the hero visualization is the joint work of Ben Frederickson, Jeff Heer and Mike Bostock.
Many due to the quite a few pull requests and points filed on github. Thanks specifically, to Osemwaro Pedro for recognizing an off by one error in one of many equations. And likewise to Dan Schmidt who did an enhancing move over the entire undertaking, correcting quite a few typographical and grammatical errors.
Dialogue and Evaluation
Reviewer A – Matt Hoffman
Reviewer B – Anonymous
Discussion with User derifatives
Footnotes
- It’s attainable, nevertheless, to assemble very particular counterexamples the place momentum doesn’t converge, even on convex features. See
[4] for a counterexample. - In Tikhonov Regression we add a quadratic penalty to the regression, minimizing
-
That is true as we are able to write updates in matrix kind as
which means, by inverting the matrix on the left,
-
We are able to write out the convergence charges explicitly. The eigenvalues are
then the roots are complicated and the convergence charge is - This may be derived by decreasing the inequalities for all 4 + 1 circumstances within the express type of the convergence charge above.
- We should optimize over
- The above optimization drawback is bounded from beneath by
- This may be written explicitly as
- We use the infinity norm to measure our error, comparable outcomes could be derived for the 1 and a couple of norms.
-
The momentum iterations are
- On the 1D perform
References
- On the importance of initialization and momentum in deep learning. [PDF]
Sutskever, I., Martens, J., Dahl, G.E. and Hinton, G.E., 2013. ICML (3), Vol 28, pp. 1139—1147. - Some strategies of dashing up the convergence of iteration strategies [PDF]
Polyak, B.T., 1964. USSR Computational Arithmetic and Mathematical Physics, Vol 4(5), pp. 1—17. Elsevier. DOI: 10.1016/0041-5553(64)90137-5 - Principle of gradient strategies
Rutishauser, H., 1959. Refined iterative strategies for computation of the answer and the eigenvalues of self-adjoint boundary worth issues, pp. 24—49. Springer. DOI: 10.1007/978-3-0348-7224-9_2 - Evaluation and design of optimization algorithms through integral quadratic constraints [PDF]
Lessard, L., Recht, B. and Packard, A., 2016. SIAM Journal on Optimization, Vol 26(1), pp. 57—95. SIAM. - Introductory lectures on convex optimization: A primary course
Nesterov, Y., 2013. , Vol 87. Springer Science & Enterprise Media. DOI: 10.1007/978-1-4419-8853-9 - Pure gradient works effectively in studying http://distill.pub/2017/momentum
Amari, S., 1998. Neural computation, Vol 10(2), pp. 251—276. MIT Press. DOI: 10.1162/089976698300017746 - Deep Studying, NIPS′2015 Tutorial [PDF]
Hinton, G., Bengio, Y. and LeCun, Y., 2015. - Adaptive restart for accelerated gradient schemes [PDF]
O’Donoghue, B. and Candes, E., 2015. Foundations of computational arithmetic, Vol 15(3), pp. 715—732. Springer. DOI: 10.1007/s10208-013-9150-3 - The Nth Energy of a 2×2 Matrix. [PDF]
Williams, Ok., 1992. Arithmetic Journal, Vol 65(5), pp. 336. MAA. DOI: 10.2307/2691246 - From Averaging to Acceleration, There may be Solely a Step-size. [PDF]
Flammarion, N. and Bach, F.R., 2015. COLT, pp. 658—695. - On the momentum time period in gradient descent studying algorithms [PDF]
Qian, N., 1999. Neural networks, Vol 12(1), pp. 145—151. Elsevier. DOI: 10.1016/s0893-6080(98)00116-6 - Understanding deep studying requires rethinking generalization [PDF]
Zhang, C., Bengio, S., Hardt, M., Recht, B. and Vinyals, O., 2016. arXiv preprint arXiv:1611.03530. - A differential equation for modeling Nesterov’s accelerated gradient methodology: Principle and insights [PDF]
Su, W., Boyd, S. and Candes, E., 2014. Advances in Neural Data Processing Methods, pp. 2510—2518. - The Zen of Gradient Descent [HTML]
Hardt, M., 2013. - A geometrical various to Nesterov’s accelerated gradient descent [PDF]
Bubeck, S., Lee, Y.T. and Singh, M., 2015. arXiv preprint arXiv:1506.08187. - An optimum first order methodology based mostly on optimum quadratic averaging [PDF]
Drusvyatskiy, D., Fazel, M. and Roy, S., 2016. arXiv preprint arXiv:1604.06543. - Linear coupling: An final unification of gradient and mirror descent [PDF]
Allen-Zhu, Z. and Orecchia, L., 2014. arXiv preprint arXiv:1407.1537. - Accelerating the cubic regularization of Newton’s methodology on convex issues [PDF]
Nesterov, Y., 2008. Mathematical Programming, Vol 112(1), pp. 159—181. Springer. DOI: 10.1007/s10107-006-0089-x
Updates and Corrections
View all changes to this text because it was first revealed. In case you see a mistake or wish to recommend a change, please create an issue on GitHub.
Citations and Reuse
Diagrams and textual content are licensed beneath Artistic Commons Attribution CC-BY 2.0, except famous in any other case, with the source available on GitHub. The figures which were reused from different sources do not fall beneath this license and could be acknowledged by a observe of their caption: “Determine from …”.
For attribution in educational contexts, please cite this work as
Goh, "Why Momentum Actually Works", Distill, 2017. http://doi.org/10.23915/distill.00006
BibTeX quotation
@article{goh2017why,
creator = {Goh, Gabriel},
title = {Why Momentum Actually Works},
journal = {Distill},
12 months = {2017},
url = {http://distill.pub/2017/momentum},
doi = {10.23915/distill.00006}
}
[ad_2]
Source link
