

[ad_1]
Developments in synthetic intelligence, significantly giant language fashions, open up thrilling potentialities for historical research and education. Nevertheless, you will need to scrutinize the methods these fashions interpret and recall the previous. Do they replicate any inherent biases of their understanding of historical past?
I’m effectively conscious of the subjectivity of historical past (I majored in historical past in my undergrad!). The occasions we keep in mind and the narratives we kind in regards to the previous are closely influenced by the historians who penned them and the society we inhabit. Take, as an illustration, my highschool world historical past course, which devoted over 75% of the curriculum to European historical past, skewing my understanding of world occasions.
On this article, I discover how human historical past will get remembered and interpreted by way of the lens of AI. I look at the interpretations of key historic occasions by a number of giant language fashions to uncover:
- Do these fashions show a Western or American bias in direction of occasions?
- Do the fashions’ historic interpretations differ primarily based on the language used for prompts, reminiscent of Korean or French prompts emphasizing extra Korean or French occasions, respectively?
With these questions in thoughts, let’s dive in!
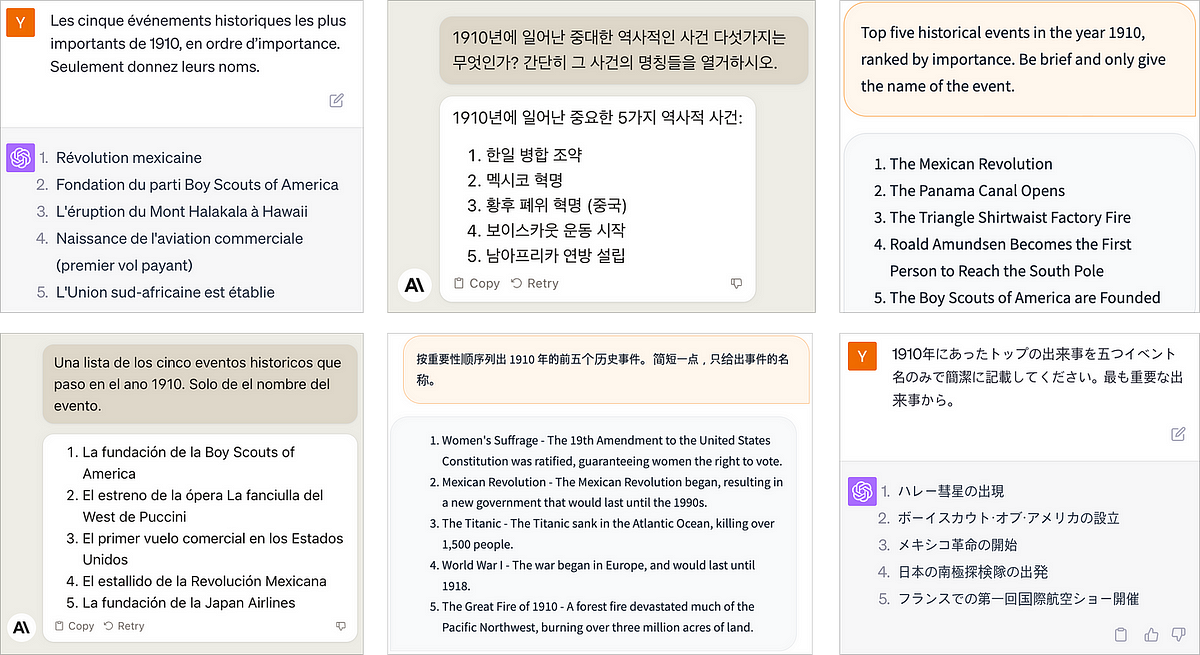
For example, I requested three completely different giant language fashions (LLMs) what the most important historic occasions within the 12 months 1910 have been. (Extra particulars on every LLM within the subsequent part.)

The query I posed was intentionally loaded with no goal reply. The importance of the 12 months 1910 varies tremendously relying on one’s cultural perspective. In Korean historical past, it marks the beginning of the Japanese occupation, a turning level that considerably influenced the nation’s trajectory (see Japan-Korea Treaty of 1910).
But, the Japanese annexation of Korea didn’t function in any of the responses. I puzzled if the identical fashions would interpret the query in a different way if prompted in a unique language — say, in Korean.

Prompted in Korean, one of many prime occasions famous by Claude is certainly the Japanese Annexation of Korea. Nevertheless, I discovered it fascinating that two out of 5 of GPT-4’s essential occasions have been US-centric (Boy Scouts and Mann-Elkins Act) whereas neglecting to say the Annexation of Korea. To not point out that Falcon, even when prompted in Korean, responded in English.
The experiment setup was as follows:
Languages and Prompts
The languages I selected have been principally arbitrary, primarily based on the languages that I used to be probably the most conversant in (English, Korean) and people who a number of of my closest pals spoke and will translate for me (Chinese language, Japanese, French, Spanish). Translations might be discovered on the finish of the article. I requested them to translate the English for me:
“Prime 5 historic occasions within the 12 months {}, ranked by significance. Be transient and solely give the title of the occasion.”
Fashions
Normalizing the occasions
Even when a mannequin generated the identical occasion with every run, there was a number of range in the way in which it described the identical occasion.
For instance, the next all consult with the identical occasion:
- “Japan annexation of Korea”
- “Japan’s Annexation of Korea”
- “Japan annexes Korea”
- “Japan-Korea Annexation Treaty”
I wanted a strategy to consult with a single occasion (the Japanese annexation of Korea) utilizing the identical vocabulary (a course of referred to as normalization). To not point out that the identical occasion may very well be described in six completely different languages!
I used a mix of guide guidelines, Google Translate, and GPT-4 to help with the normalization. Initially I had hoped to make use of one LLM to normalize the occasions of one other LLM (e.g. use GPT-4 to normalize Claude’s occasions; Claude to normalize Falcon’s occasions, and many others) to scale back bias. Nevertheless, Claude and Falcon weren’t superb at following instructions to normalize and GPT-4 emerged as the very best mannequin for the job.
I acknowledge the biases that include utilizing a mannequin to normalize its personal occasions. Nevertheless, as I used completely different periods of GPT-4 to generate historic occasions and to normalize the occasions, there was no overlap in context. Sooner or later, normalization might be achieved utilizing a extra goal technique.
Total, I used to be stunned by the completely different fashions’ understanding of historical past.
- GPT-4 was extra more likely to generate the identical occasions whatever the language it was prompted with
- Anthropic was extra more likely to generate historic occasions related to the language it was prompted with
- Falcon (sadly) was extra more likely to make up pretend occasions
- All three fashions displayed a bias for Western or American occasions, however not in the way in which I anticipated. When prompted in a non-English language, the mannequin would generate an American or British historic occasion (even when the mannequin wouldn’t generate that occasion when prompted in English). This occurred throughout all three fashions.
Every mannequin x language mixture generated “prime 5 historic occasions” 10 instances (= 50 occasions whole). I took the subset of occasions which at the least one language generated 5 instances or extra. This was as a result of fashions typically predicted a one-off occasion that it by no means predicted once more. The cells with values 10 imply that the mannequin predicted that occasion each single time I prompted it.
On this part, I present the highest occasions predicted by every of the three fashions, damaged down by languages, for the 12 months 1910. Related charts for the years 610 and 1848 might be discovered on the GitHub page, the place I shared the entire code and analyses.
GPT-4 (OpenAI)
- Mexican Revolution: throughout all languages, the Mexican Revolution was persistently an essential world occasion — even in languages I didn’t count on, reminiscent of Korean or Japanese
- Japanese Annexation of Korea: Not talked about when requested in Spanish or French. When prompted in Japanese, was extra more likely to point out this occasion (9 instances) than when prompted in Korean (6 instances), which I discovered unusual and fascinating
- Boy Scouts of America based: GPT-4 predicted this occasion when prompted in Japanese (7 instances) almost twice as usually as when prompted in English (4 instances). It looks as if a random tidbits of American data was encoded into the Japanese understanding of 1910
- Institution of Glacier Nationwide Park: Even stranger, GPT-4 predicted this occasion when prompted in Spanish and French, however not in English

Claude (Anthropic)
Total: Not like GPT-4, there was no single occasion that was deemed “essential historic occasion” by all languages.
- Mexican Revolution: Whereas generated usually when requested in French, Spanish, and (inexplicably) Korean, not as essential in English as was with GPT-4
- Japanese Annexation of Korea: Extra essential for Korean and Japanese than for different languages (the 2 international locations concerned within the occasion)
- Dying of Edward VII: Extra essential for English and French (and never for different languages). Edward VII was the King of the UK and apparently had good relations with France.
- Exploration of Antarctica: This occasion was really the British Antarctic expedition, wherein a British man reached Antarctica for the primary time. Nevertheless, for some unknown cause, Claude generates this occasion solely when prompted in Chinese language or Japanese (however not in English).

Falcon 40B Instruct (Open Supply; TII)
Total, Falcon was not as constant or correct as the opposite two fashions. The rationale fewer occasions are proven within the chart is as a result of there have been no different occasions that Falcon predicted 5 instances or extra! That means that Falcon was a bit inconsistent in its predictions.
- The Titanic sinks: This really occurred in 1912
- Outbreak of World Conflict I: This really occurred in 1914
- Falcon is traditionally inaccurate in its predictions. However at the least it bought the last decade proper?

Subsequent, I quantified how comparable the total predictions of 1 mannequin in comparison with the others. I used a mathematical technique (cosine similarity) to find out how comparable two prediction distributions have been. Values nearer to 1 signified that predictions have been equivalent; values nearer to 0 signified that two units of predictions shared nothing in frequent.
Once more, I present this instance for the 12 months 1910. The opposite years might be discovered on the GitHub page.
Throughout many of the languages, GPT-4 and Claude had a better correlation worth — that means that regardless of the entire languages, the 2 fashions predicted a excessive proportion of comparable occasions.
Falcon, alternatively, tended to be much less correlated, that means that its understanding of historical past veered away from that of GPT-4 and Claude.

Subsequent, I in contrast the completely different language fashions for annually. I mixed all occasions predicted for all languages and regarded the general occasions predicted by a mannequin, whatever the language. I took the subset of occasions for which at the least one mannequin generated 10 instances or extra.
Much like the developments discovered within the part above, GPT-4 and Claude tended to foretell comparable main historic occasions for annually — The First Revelations of Muhammad and the Ascension of Emperor Heraclius to the Byzantine Throne in 610; the European Revolutions of 1848; and the Mexican Revolution in 1910.
There have been sure occasions that one mannequin disproportionately predicted in comparison with the others. For instance, for the 12 months 1848, GPT-4 predicted “Publication of the Communist Manifesto” 42 instances, in comparison with Claude’s 15 instances. For the 12 months 1910, Claude predicted “Dying of Edward VII” 26 instances, in comparison with GPT-4’s 1 time.
Falcon tended to have the least understanding of historic occasions. Falcon missed main occasions for all three years. For the 12 months 610, Falcon didn’t predict the occasion of the Ascension of Emperor Heraclius. For the 12 months 1910, it didn’t predict occasions reminiscent of Japan’s Annexation of Korea, Formation of Union of South Africa, and Portuguese Revolution (all non-American international occasions), whereas as an alternative predicting America-centric occasions such because the Triangle Shirtwaist Factory Fire (which occurred in 1911, not 1910). Curiously, Falcon was in a position to predict many of the 1848 occasions just like the opposite two fashions — maybe as a result of the 1848 occasions have been extra Western-centric (e.g. European revolutions)?
Occasions from longer in the past (e.g. 12 months 610) meant that historical past is a little more fuzzy. The Tang Dynasty was established in 618, not 610 and the Construction of the Grand Canal under Emperor Yang of Sui was really accomplished underneath an extended time period (604 to 609).
610

1848

1910

So why does this all matter?
As academic corporations more and more incorporate Massive Language Fashions (LLMs) into their merchandise — Duolingo leveraging GPT-4 for language learning, Khan Academy introducing AI teaching assistant ‘Khanmigo’, and Harvard University planning to integrate AI into their computer science curriculum — understanding the underlying biases of those fashions turns into essential. If a scholar makes use of an LLM to study historical past, what biases may they inadvertently soak up?
On this article, I confirmed that some standard language fashions, reminiscent of GPT-4, persistently predict “essential occasions” whatever the immediate language. Different fashions, like Claude, confirmed extra language-specific predictions. Closed-source fashions usually exhibited higher consistency and accuracy than the main open-source various. Throughout the entire fashions examined on this article, there was an inclination to foretell Western or American occasions (even arcane occasions) on the expense of different international occasions.
Future work might embody:
- Increasing the evaluation to embody extra languages and years
- Doing a deeper evaluation into the historic accuracy of mannequin outputs
- Doing a deeper evaluation into the rating of prime historic occasions
- Growing a extra goal technique for occasion normalization
The goal of this text was to not discredit LLMs or recommend their removing from academic settings. Fairly, I want to urge a important and cautious method, one which acknowledges and mitigates their biases. LLMs, when used responsibly, might be beneficial assets for each college students and academics throughout disciplines. Nevertheless, we should additionally comprehend the biases they could carry, reminiscent of Western-centrism, and tailor their use accordingly.
Changing your historical past professor or textbooks with an LLM dangers yielding a distorted, one-sided interpretation of historical past. In the end, we should make the most of these instruments thoughtfully, cognizant of their inherent biases, making certain they increase moderately than dictate our understanding of the world.
[ad_2]
Source link
