

[ad_1]
UrbanGIRAFFE, an method proposed by researchers from Zhejiang College for photorealistic picture synthesis, is launched for controllable digicam pose and scene contents. Addressing challenges in producing city scenes without spending a dime digicam viewpoint management and scene modifying, the mannequin employs a compositional and controllable technique, using a rough 3D panoptic prior. It additionally consists of the format distribution of uncountable stuff and countable objects. The method breaks down the scene into issues, objects, and sky, facilitating numerous controllability, equivalent to giant digicam motion, stuff modifying, and object manipulation.
In conditional picture synthesis, prior strategies have excelled, notably these leveraging Generative Adversarial Networks (GANs) to generate photorealistic photos. Whereas current approaches situation picture synthesis on semantic segmentation maps or layouts, the main focus has predominantly been on object-centric scenes, neglecting complicated, unaligned city scenes. UrbanGIRAFFE, a devoted 3D-aware generative mannequin for city scenes, the proposal addresses these limitations, providing numerous controllability for giant digicam actions, stuff modifying, and object manipulation.
GANs have confirmed efficient in producing controllable and photorealistic photos in conditional picture synthesis. Nonetheless, current strategies are restricted to object-centric scenes and need assistance with city scenes, hindering free digicam viewpoint management and scene modifying. UrbanGIRAFFE breaks down scenes into stuff, objects, and sky, leveraging semantic voxel grids and object layouts earlier than numerous controllability, together with important digicam actions and scene manipulations.
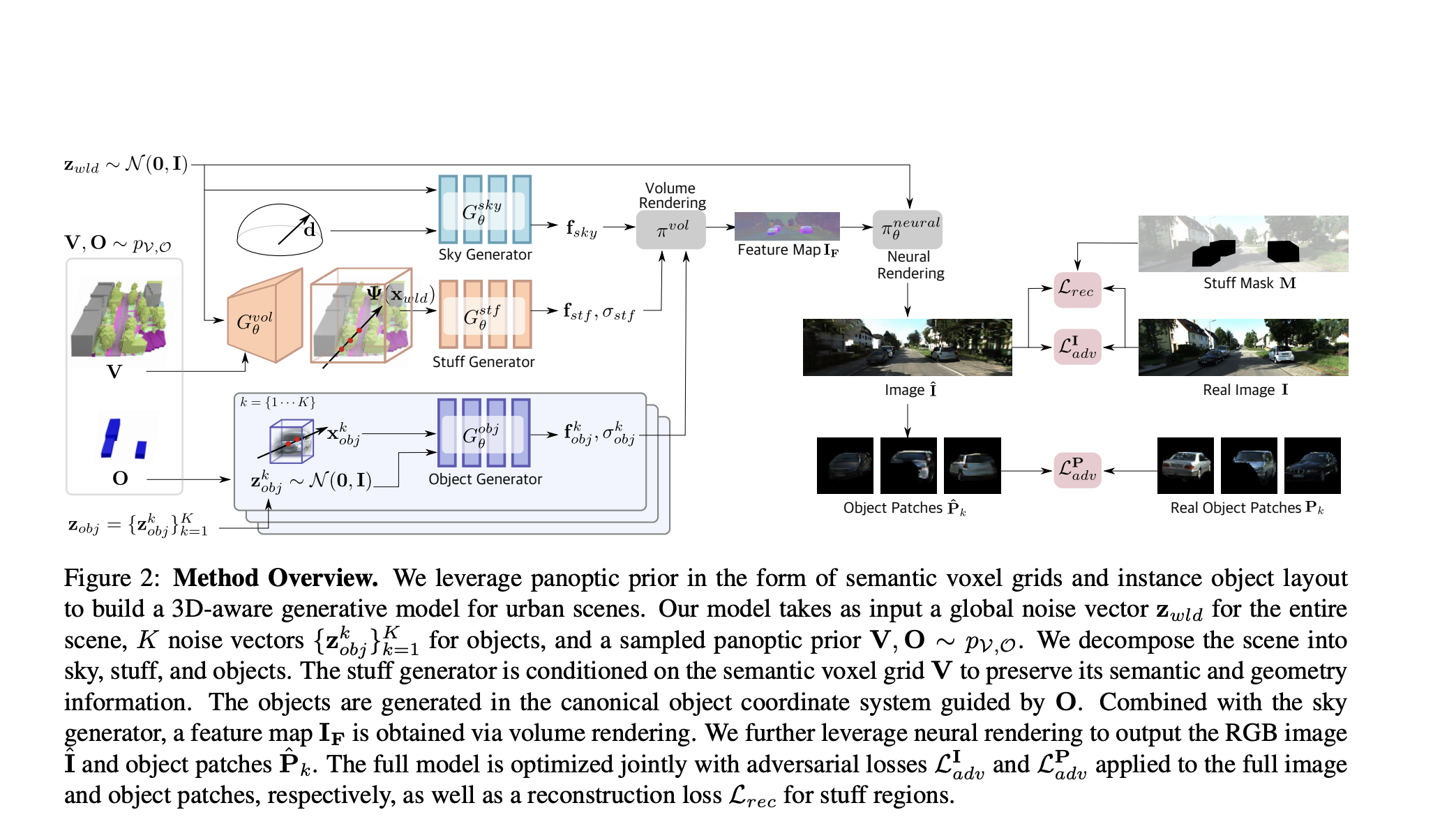
UrbanGIRAFFE innovatively dissects city scenes into uncountable stuff, countable objects, and the sky, using prior distributions for stuff and issues to untangle complicated city environments. The mannequin includes a conditioned stuff generator using semantic voxel grids as stuff prior for integrating coarse semantic and geometry data. An object format prior facilitates studying an object generator from cluttered scenes. Educated end-to-end with adversarial and reconstruction losses, the mannequin leverages ray-voxel and ray-box intersection methods to optimize sampling areas, lowering the variety of required sampling factors.
In a complete analysis, the proposed UrbanGIRAFFE methodology surpasses varied 2D and 3D baselines on artificial and real-world datasets, showcasing superior controllability and constancy. Qualitative assessments on the KITTI-360 dataset reveal UrbanGIRAFFE’s outperformance over GIRAFFE in background modeling, enabling enhanced stuff modifying and digicam viewpoint management. Ablation research on KITTI-360 affirm the efficacy of UrbanGIRAFFE’s architectural parts, together with reconstruction loss, object discriminator, and progressive object modeling. Adopting a shifting averaged mannequin throughout inference additional enhances the standard of generated photos.
UrbanGIRAFFE innovatively addresses the complicated activity of controllable 3D-aware picture synthesis for city scenes, attaining exceptional versatility in digicam viewpoint manipulation, semantic format, and object interactions. Leveraging a 3D panoptic prior, the mannequin successfully disentangles scenes into stuff, objects, and sky, facilitating compositional generative modeling. The method underscores UrbanGIRAFFE’s development in 3D-aware generative fashions for intricate, unbounded units. Future instructions embody integrating a semantic voxel generator for novel scene sampling and exploring lighting management via light-ambient colour disentanglement. The importance of the reconstruction loss is emphasised for sustaining constancy and producing numerous outcomes, particularly for occasionally encountered semantic courses.
Future work for UrbanGIRAFFE consists of incorporating a semantic voxel generator for novel scene sampling, enhancing the strategy’s potential to generate numerous and novel city scenes. There’s a plan to discover lighting management by disentangling gentle from ambient colour, aiming to offer extra fine-grained management over the visible features of the generated scenes. One potential approach to enhance the standard of generated photos is to make use of a shifting common mannequin throughout inference.
Try the Paper, Github, and Project. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to affix our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Good day, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m obsessed with know-how and wish to create new merchandise that make a distinction.
[ad_2]
Source link
