

[ad_1]
Picture by Writer
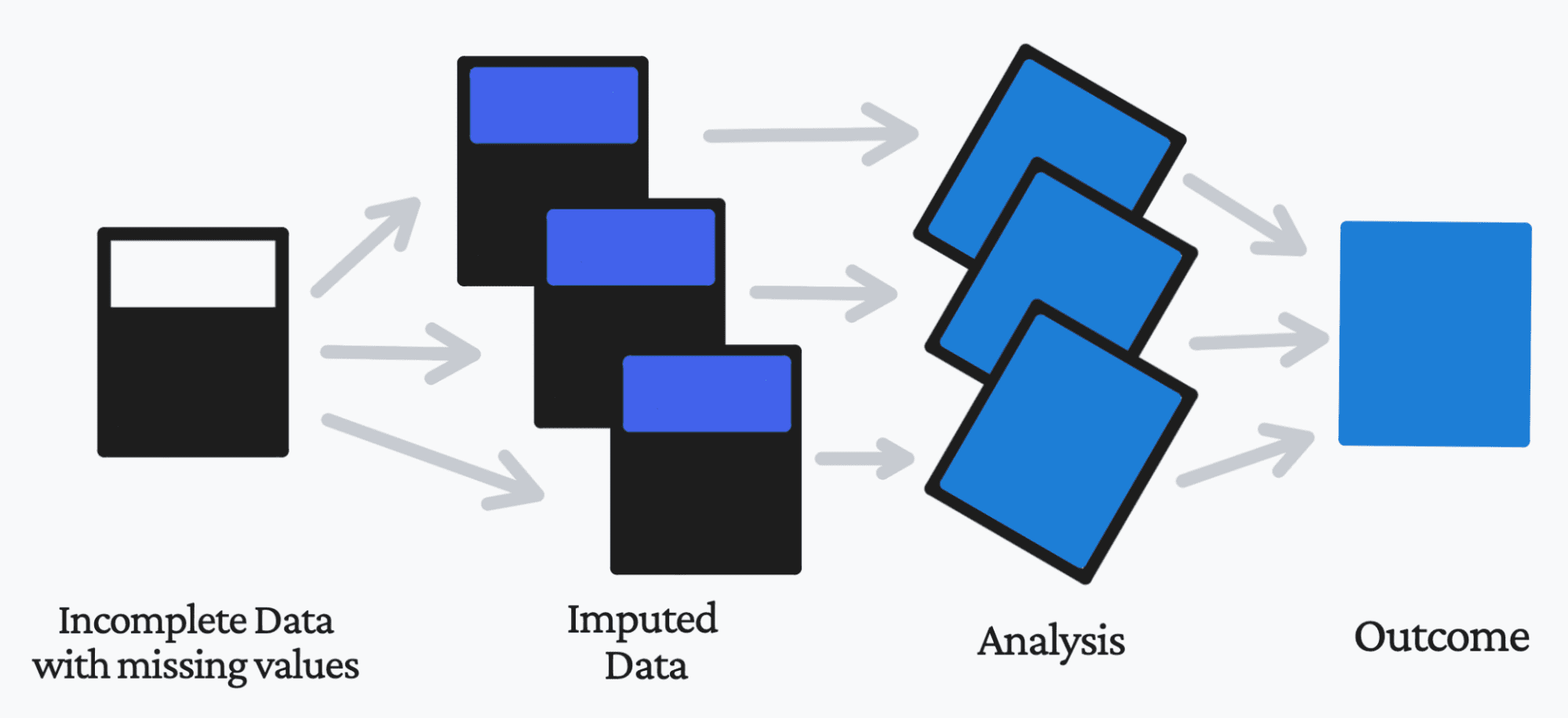
When working with information, it will be superb in case your information was with out lacking values.
Sadly, we don’t dwell in an ideal world, particularly with regards to information. Due to this fact, you have to to discover a answer for these lacking information factors.
That is the place information imputation comes into the image.
Information imputation makes use of varied statistical strategies within the strategy of changing your lacking information values with a substitute worth. This enables you, the enterprise, and the client to have the ability to retain essentially the most out of the info and supply insightful data.
If you happen to substitute an information level, it’s referred to as ‘unit imputation’. If you happen to substitute a part of an information level, it’s referred to as ‘merchandise imputation’.
So why can we impute the info, slightly than simply take away it?
Whereas it will be the better choice to take away the info factors which have lacking values, this isn’t all the time the best choice. Not solely will you cut back the dimensions of your dataset by eradicating the lacking values, however this will result in additional problems with incorrect and untrustworthy evaluation.
Lacking information doesn’t give us a terrific scope of the dataset and might cut back the reliability of the general consequence. Lacking information can:
1. Conflicting when utilizing Python Libraries.
There are particular libraries that battle and are naturally incompatible to deal with lacking information. This could trigger delays in your workflow/course of in addition to result in additional errors.
2. Points with the dataset
If you happen to take away lacking values, it should trigger a lower within the dimension of your dataset. Nonetheless, preserving lacking values in your dataset can have a significant impact on the variables, the correlation, the statistical evaluation, and the general consequence.
3. Remaining consequence
Your precedence when working with information and fashions is to make sure that the ultimate mannequin is free from errors, environment friendly, and reliable for use in real-world instances. Lacking information will naturally result in bias within the dataset, resulting in incorrect evaluation.
So how can we substitute these lacking values? Let’s discover out.
1. SimpleImputer utilizing imply
class sklearn.impute.SimpleImputer(*, missing_values=nan, technique='imply', fill_value=None, verbose="deprecated", copy=True, add_indicator=False)
Utilizing Scikit-learn’s SimpleImputer class, you possibly can impute lacking values utilizing a continuing worth, or utilizing the imply, median or most frequent of every column through which the lacking values are current.
For instance:
# Imports
import numpy as np
from sklearn.impute import SimpleImputer
# Utilizing the imply worth of the columns
imp = SimpleImputer(missing_values=np.nan, technique='imply')
imp.match([[1, 3], [5, 6], [8, 4], [11,2], [9, 3]])
# Change lacking values, encoded as np.nan
X = [[np.nan, 3], [5, np.nan], [8, 4], [11,2], [np.nan, 3]]
print(imp.rework(X))
Output:
[[ 6.8 3. ]
[ 5. 3.6]
[ 8. 4. ]
[11. 2. ]
[ 6.8 3. ]]
2. SimpleImputer utilizing essentially the most frequent
Utilizing the identical class as above, I discussed that you may use imply, median, or most frequent. Most frequent works with categorical options, which can be both string or numerical. It replaces the lacking worth with essentially the most frequent worth inside that column.
That is how you are able to do this utilizing the identical instance as above:
# Imports
import numpy as np
from sklearn.impute import SimpleImputer
# Utilizing essentially the most frequent worth of the columns
imp = SimpleImputer(missing_values=np.nan, technique='most_frequent')
imp.match([[1, 3], [5, 6], [8, 4], [11,2], [9, 3]])
# Change lacking values, encoded as np.nan
X = [[np.nan, 3], [5, np.nan], [8, 4], [11,2], [np.nan, 3]]
print(imp.rework(X))
Output:
[[ 1. 3.]
[ 5. 3.]
[ 8. 4.]
[11. 2.]
[ 1. 3.]]
3. Utilizing k-NN
If you happen to don’t know what k-NN is, it’s an algorithm that makes predictions on the take a look at information set by calculating the space between the present coaching information factors. It assumes that related issues exist inside shut proximity.
A easy and straightforward approach to make use of k-NN for imputation is through the use of the Impyute library. For instance:
Earlier than imputation:
n = 4
arr = np.random.uniform(excessive=5, dimension=(n, n))
for _ in vary(3):
arr[np.random.randint(n), np.random.randint(n)] = np.nan
print(arr)
Output:
[[ nan 3.14058295 2.2712381 0.92148091]
[ nan 3.24750479 1.35688761 2.54943751]
[4.47019496 0.79944618 3.61855558 3.12191146]
[3.09645292 nan 0.43638625 4.05435414]]
After imputation:
import impyute as impy
print(impy.imply(arr))
Output:
[[3.78332394 3.14058295 2.2712381 0.92148091]
[3.78332394 3.24750479 1.35688761 2.54943751]
[4.47019496 0.79944618 3.61855558 3.12191146]
[3.09645292 2.39584464 0.43638625 4.05435414]]
At this level you might have realized what Information Imputation is, its significance and three alternative ways to method it. In case you are nonetheless concerned with studying extra about lacking values and statistical evaluation, I extremely suggest studying Statistical Analysis with Missing Data by Roderick J.A. Little and Donald B. Rubin.
Nisha Arya is a Information Scientist and Freelance Technical Author. She is especially concerned with offering Information Science profession recommendation or tutorials and idea based mostly data round Information Science. She additionally needs to discover the alternative ways Synthetic Intelligence is/can profit the longevity of human life. A eager learner, looking for to broaden her tech data and writing abilities, while serving to information others.
[ad_2]
Source link
