

[ad_1]

Picture by rawpixel.com on Freepik
Pandas is a well-known knowledge manipulation bundle utilized by many. It’s well-known as a result of it’s intuitive and simple to make use of. Moreover, Pandas have a lot assist from the group to boost the packages.
Nonetheless, just a few know that Pandas even have a plotting operate. Some plotting features by Pandas had been particular and provided perception in your knowledge evaluation. What had been these features? Let’s discover it collectively.
For our instance, we’d use the Commercially Obtainable Titanic Data from Kaggle.
Boostrap plot is a plotting operate from Pandas to estimate the statistical uncertainty by utilizing the bootstrap operate (Information sampling with substitute). It’s a fast plot to make use of when measuring the info statistic (imply, median, midrange) with interval estimation.
Let’s strive utilizing the operate with the info pattern.
import pandas as pd
df = pd.read_csv('prepare.csv')
pd.plotting.bootstrap_plot(df['Fare'], dimension = 150, samples = 1000)
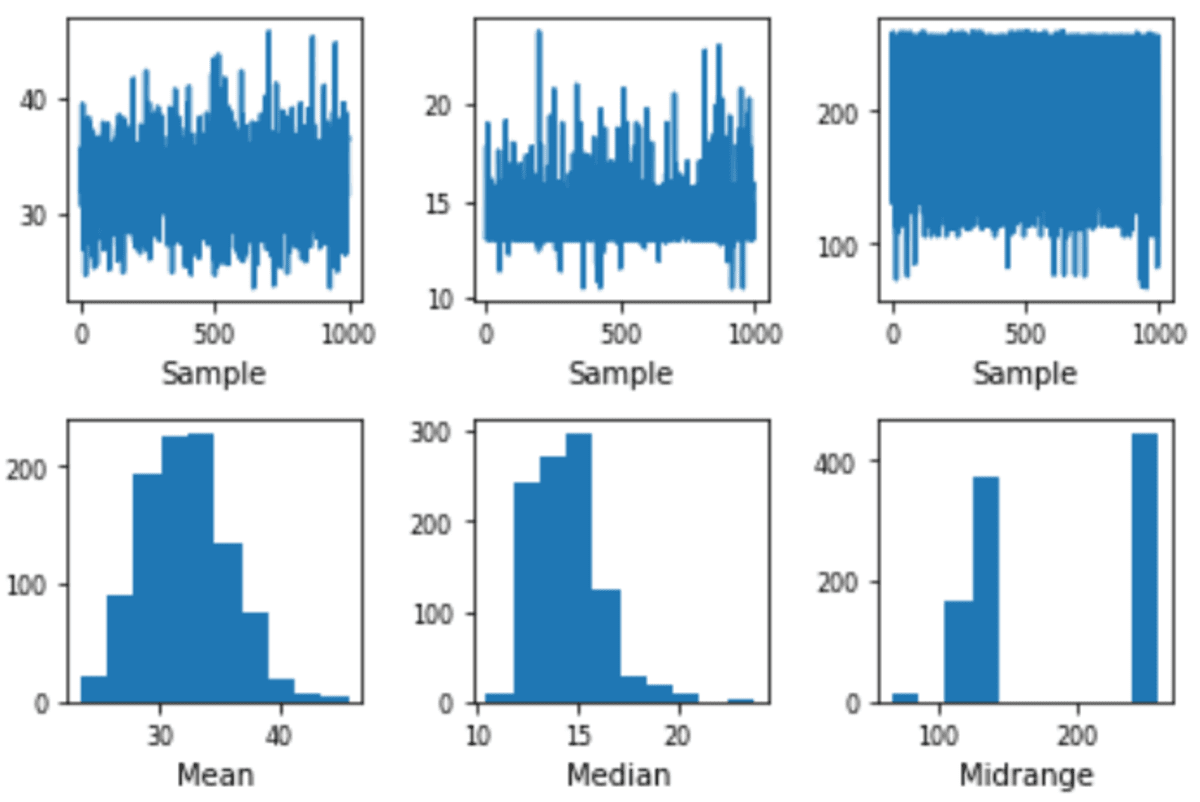
The plot would resampling the info as a lot because the samples parameter with the info quantity is on the scale parameter.
The unfold estimation of the means is near 30 to 40, and the Median is near 12 to fifteen. With this plot, we are able to attempt to estimate the precise inhabitants statistics. Your outcome could possibly be totally different in comparison with mine because the sampling is randomized.
Scatter Matrix plot is a Pandas plotting operate to create a scatter plot from all of the accessible numerical knowledge. Let’s strive the operate to be taught concerning the scatter matrix.
pd.plotting.scatter_matrix(df)
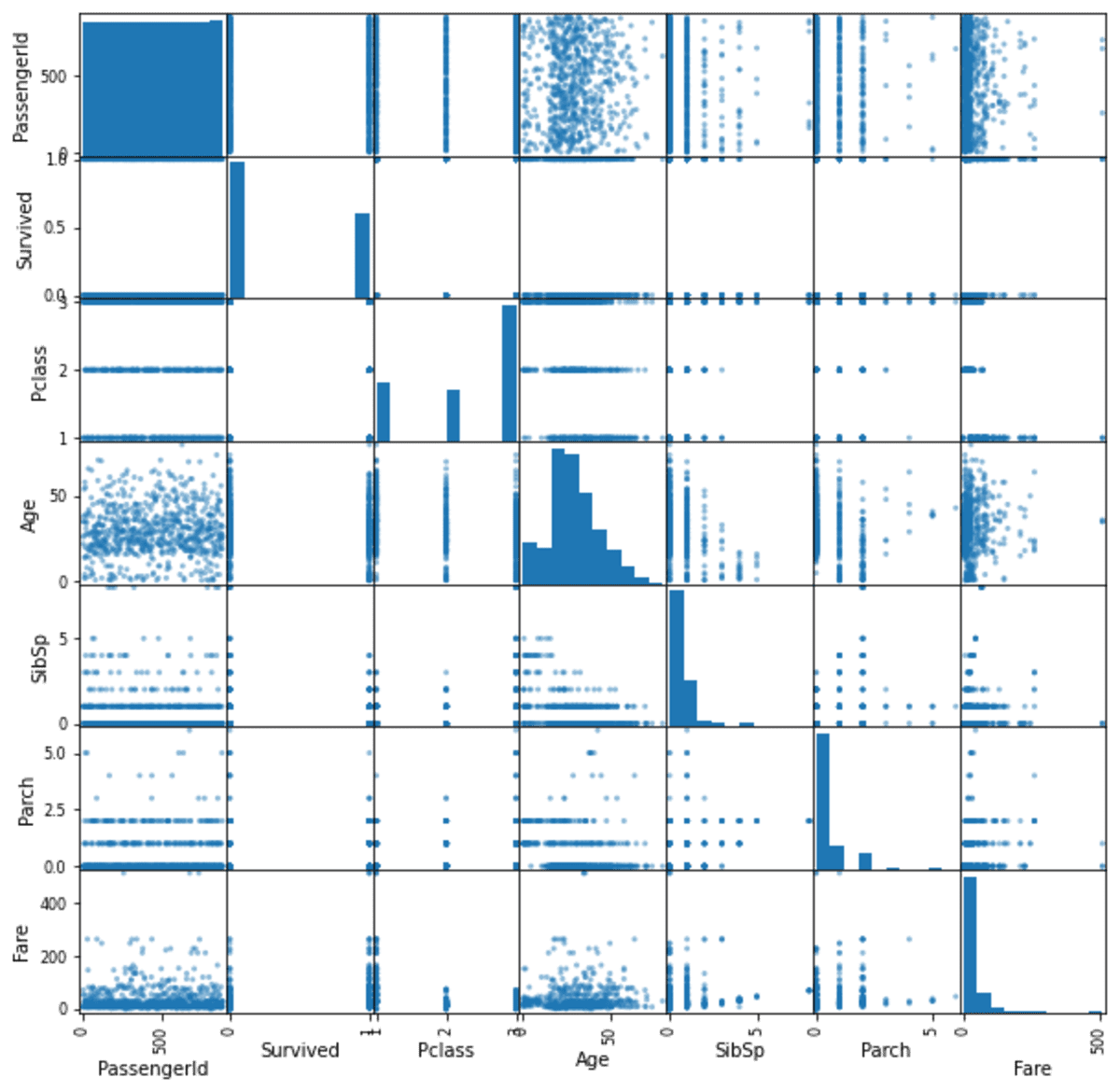
As you may see from the picture above, the scatter matrix operate mechanically detects all of the numerical columns from the info body and create a scatter matrix for every mixture. The operate creates a histogram plot for a similar column to measure the info distribution.
Radviz plot is a plot to visualise N-dimension knowledge right into a 2D plot. Often, knowledge with greater than 3 dimensions can be exhausting to visualise, however we are able to do it with Radviz Plot. Let’s strive it with the info instance.
pd.plotting.radviz(df[['SibSp', 'Parch', 'Pclass', 'Age', 'Fare','Survived']], 'Survived', colour =['blue', 'red'])
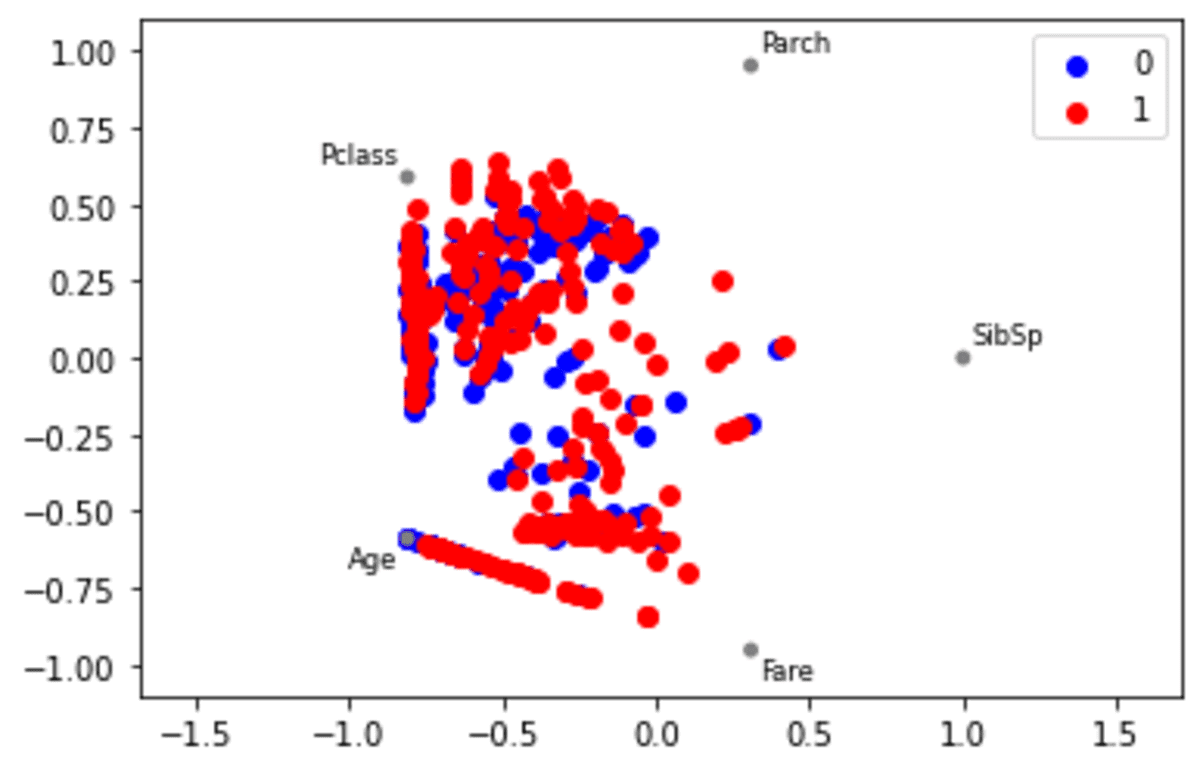
Within the operate above, we solely use the numerical knowledge with the goal to divide the info.
The result’s proven within the picture above. Nonetheless, how might we interpret the plot above? For every variable, it could be evenly represented as a circle. Every knowledge level within the variable can be plotted contained in the circle in line with its values. The extremely correlated variable can be nearer within the circle than the low correlated variables.
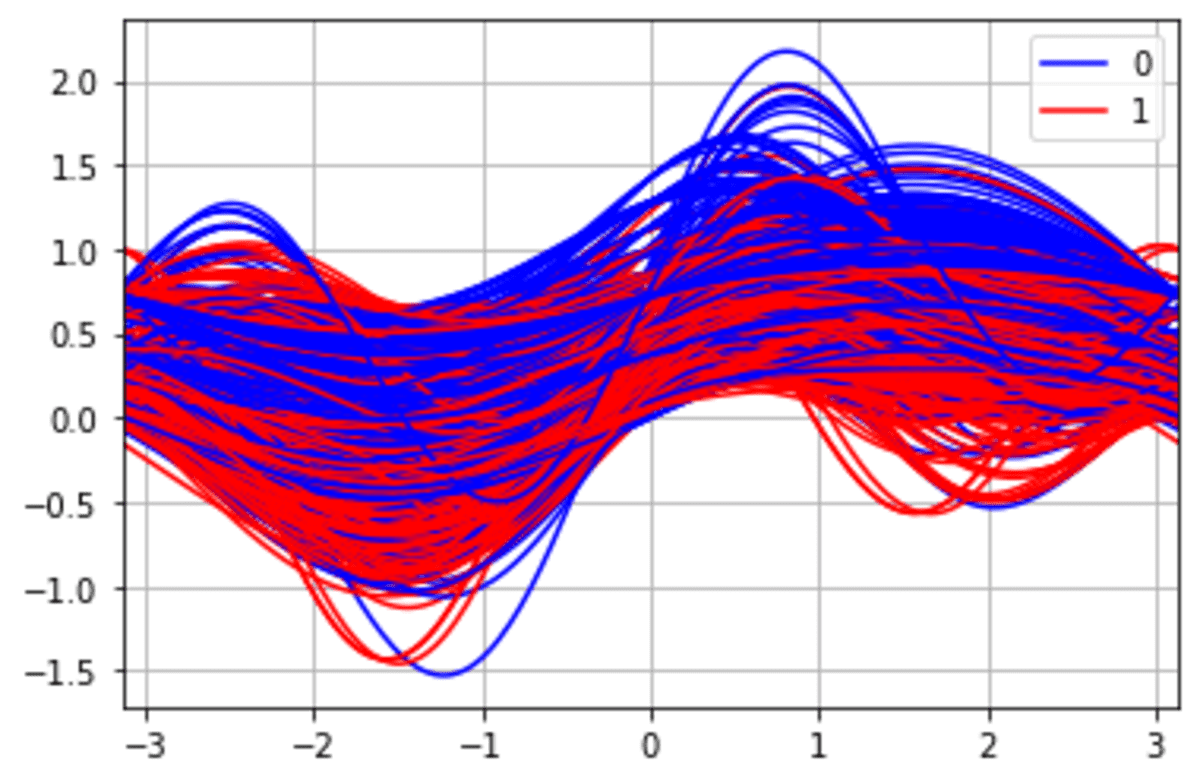
Andrew Curves plotting is a technique to visualise multivariate knowledge to probably establish clusters inside the knowledge. It additionally could possibly be used to establish if there’s any separation inside the knowledge. Let’s strive it out with the info instance.
Andrew Curves work greatest when the info is normalized inside 0 to 1, so we’d preprocess the info earlier than making use of the operate.
from sklearn.preprocessing import MinMaxScaler
df = df.drop(['PassengerId', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis =1)
scaler = MinMaxScaler()
df_scaled = scaler.fit_transform(df.drop('Survived', axis =1))
df_scaled = pd.DataFrame(df_scaled, columns = df.drop('Survived', axis =1).columns)
df_scaled['Survived'] = df['Survived']
pd.plotting.andrews_curves(df_scaled, 'Survived', colour =['blue', 'red'])
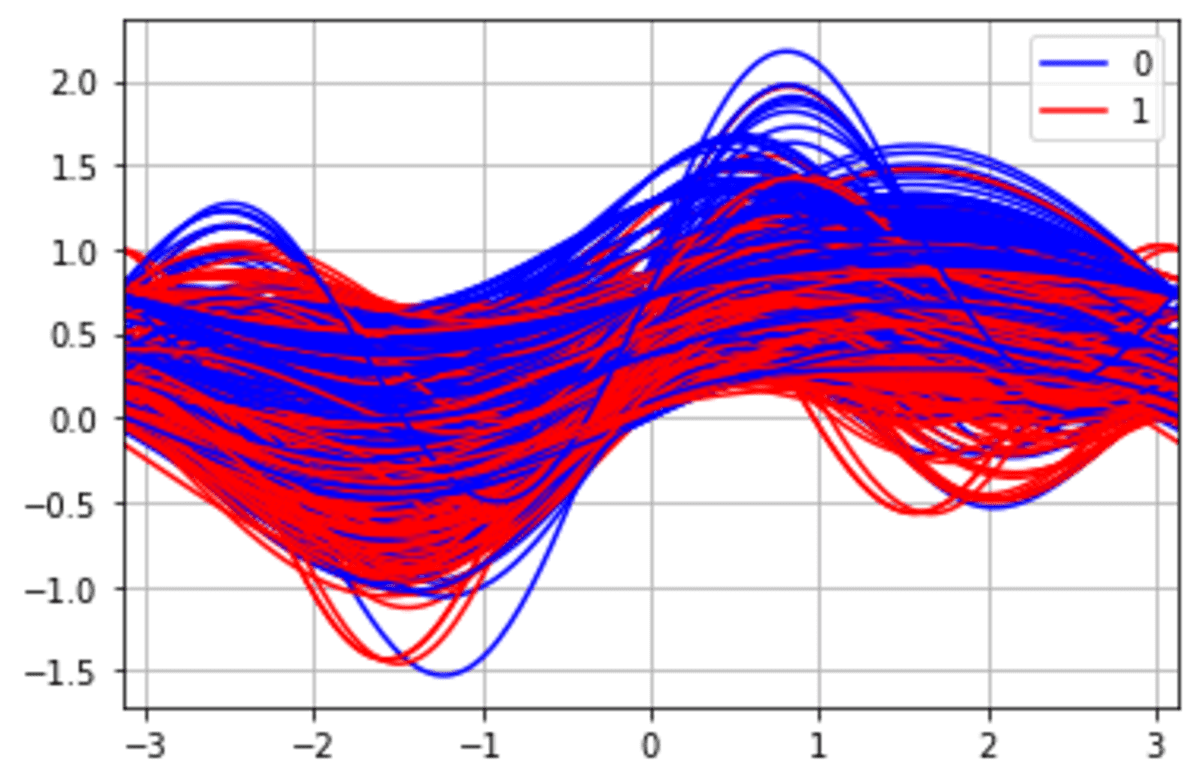
From the picture above, we are able to see a probably totally different cluster for the Survived class.
Lag plot is a particular time-series knowledge plot to examine if the time-series knowledge is correlated to themselves and random. A lag plot works by plotting the time knowledge with their lag. For instance, T1 knowledge with lag 1 can be T1 plotted towards T1+1 (or T2) knowledge. Let’s strive the features to know higher.
We’d create pattern time-series knowledge for this instance.
np.random.seed(34)
x = np.cumsum(np.random.regular(loc=1, scale=5, dimension=100))
s = pd.Collection(x)
s.plot()
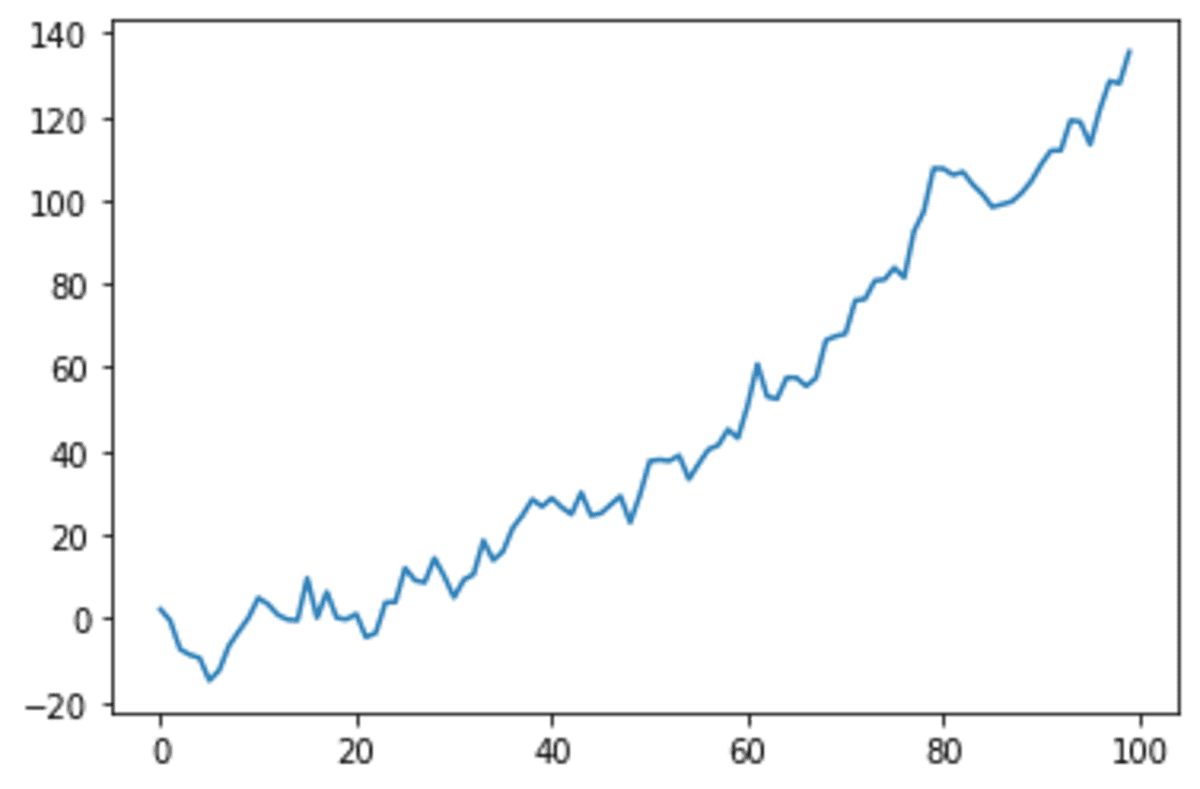
We will see our time collection knowledge exhibiting an growing sample. Let’s see what it appears to be like like after we use the lag plot.
pd.plotting.lag_plot(s, lag=1)
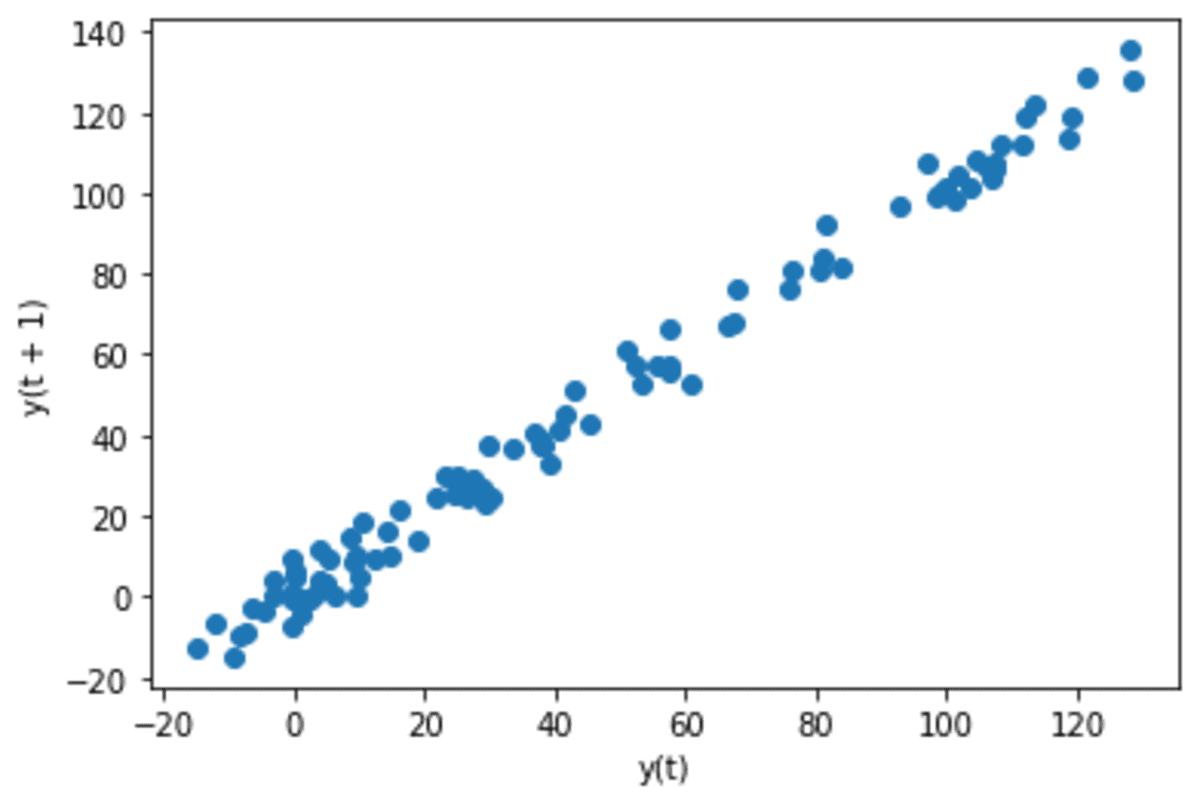
We will see the info reveals a linear sample after we use a lag plot with lag 1. It means there’s an autocorrelation with 1-day variations in knowledge. Let’s see the info if there’s a correlation after we use a month-to-month foundation.
pd.plotting.lag_plot(s, lag=30)
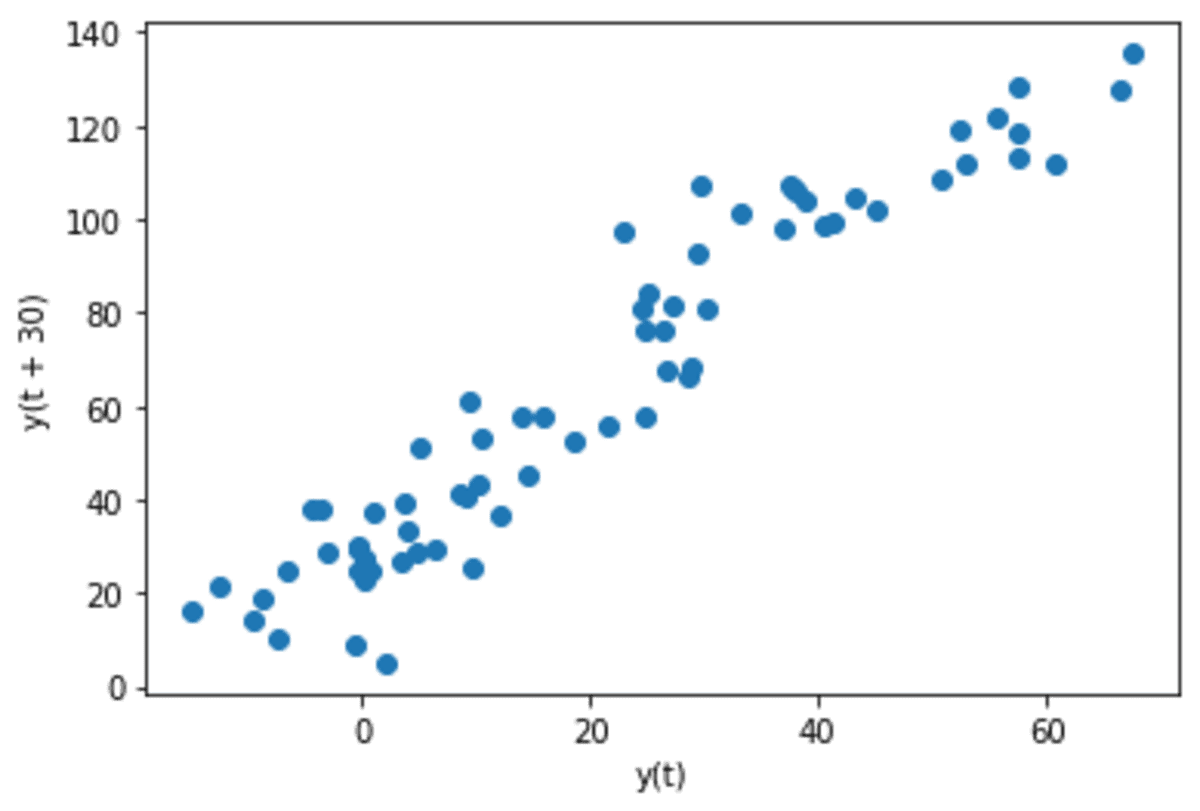
The info now turns into barely extra random though there are nonetheless linearity patterns that exist.
Pandas is an information manipulation bundle that additionally gives numerous distinctive plotting features. On this article, we focus on 5 totally different Pandas plotting features:
- Bootstrap Plot
- Scatter Matrix Plot
- Radviz Plot
- Andrew Curves Plot
- Lag Plot
Cornellius Yudha Wijaya is an information science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Information suggestions through social media and writing media.
[ad_2]
Source link
