

[ad_1]
The efficiency of ML fashions degrades as time passes and knowledge distribution modifications.

A current research from MIT, Harvard, The College of Monterrey, and Cambridge confirmed that 91% of ML models degrade over time. This research is among the first of its variety, the place researchers give attention to learning machine studying fashions’ habits after deployment and the way their efficiency evolves with unseen knowledge.
“Whereas a lot analysis has been carried out on varied sorts and markers of temporal knowledge drifts, there is no such thing as a complete research of how the fashions themselves can reply to those drifts.”
This weblog put up will overview probably the most crucial elements of the analysis, spotlight their outcomes, and stress the significance of those outcomes, particularly for the ML business.
You probably have been beforehand uncovered to ideas like covariate shift or idea drift, you could bear in mind that modifications within the distribution of the manufacturing knowledge might have an effect on the mannequin’s efficiency. This phenomenon is among the challenges of sustaining an ML mannequin in manufacturing.
By definition, ML fashions rely on the information it was educated on, that means that if the distribution of the manufacturing knowledge begins to alter, the mannequin might not carry out in addition to earlier than. And as time passes, the mannequin’s efficiency might degrade an increasing number of. The authors check with this phenomenon as “AI ageing.” I wish to name it mannequin efficiency degradation, and relying on how vital the drop in efficiency is, we might think about it a mannequin failure.
To get a greater understanding of this phenomenon, the authors developed a framework for figuring out temporal mannequin degradation. They utilized the framework to 32 datasets from 4 industries, utilizing 4 commonplace ML fashions, and investigated how temporal mannequin degradation can develop beneath minimal drifts within the knowledge.
To keep away from any mannequin bias, the authors selected 4 totally different commonplace ML strategies (Linear Regression, Random Forest Regressor, XGBoost, and a Multilayer Perceptron Neural Community). Every of those strategies represents totally different mathematical approaches to studying from knowledge. By selecting totally different mannequin sorts, they have been in a position to examine similarities and variations in the best way various fashions can age on the identical knowledge.
Equally, to keep away from area bias, they selected 32 datasets from 4 industries (Healthcare, Climate, Airport Site visitors, and Monetary).
One other crucial determination is that they solely investigated pairs of model-dataset with good preliminary efficiency. This determination is essential since it isn’t worthwhile investigating the degradation of a mannequin with a poor preliminary match.

To determine temporal mannequin efficiency degradation, the authors designed a framework that emulates a typical manufacturing ML mannequin. And ran a number of dataset-model experiments following this framework.
For every experiment, they did 4 issues:
- Randomly choose one 12 months of historic knowledge as coaching knowledge
- Choose an ML mannequin
- Randomly decide a future datetime level the place they may take a look at the mannequin
- Calculate the mannequin’s efficiency change
To raised perceive the framework, we want a few definitions. The latest level within the coaching knowledge was outlined as t_0. The variety of days between t_0 and the purpose sooner or later the place they take a look at the mannequin was outlined as dT, which symbolizes the mannequin’s age.
For instance, a climate forecasting mannequin was educated with knowledge from January 1st to December thirty first of 2022. And on February 1st, 2023, we ask it to make a climate forecast.
On this case
- t_0 = December thirty first, 2022 since it’s the newest level within the coaching knowledge.
- dT = 32 days (days from December thirty first and February 1st). That is the age of the mannequin.
The diagram beneath summarizes how they carried out each “history-future” simulation. We’ve added annotations to make it simpler to observe.

To quantify the mannequin’s efficiency change, they measured the imply squared error (MSE) at time t_0 as MSE(t_0) and on the time of the mannequin analysis as MSE(t_1).
Since MSE(t_0) is meant to be low (every mannequin was generalizing nicely at dates near coaching). One can measure the relative efficiency error because the ratio between MSE(t_0) and MSE(t_1).
E_rel = MSE(t_1)/MSE(t_0)
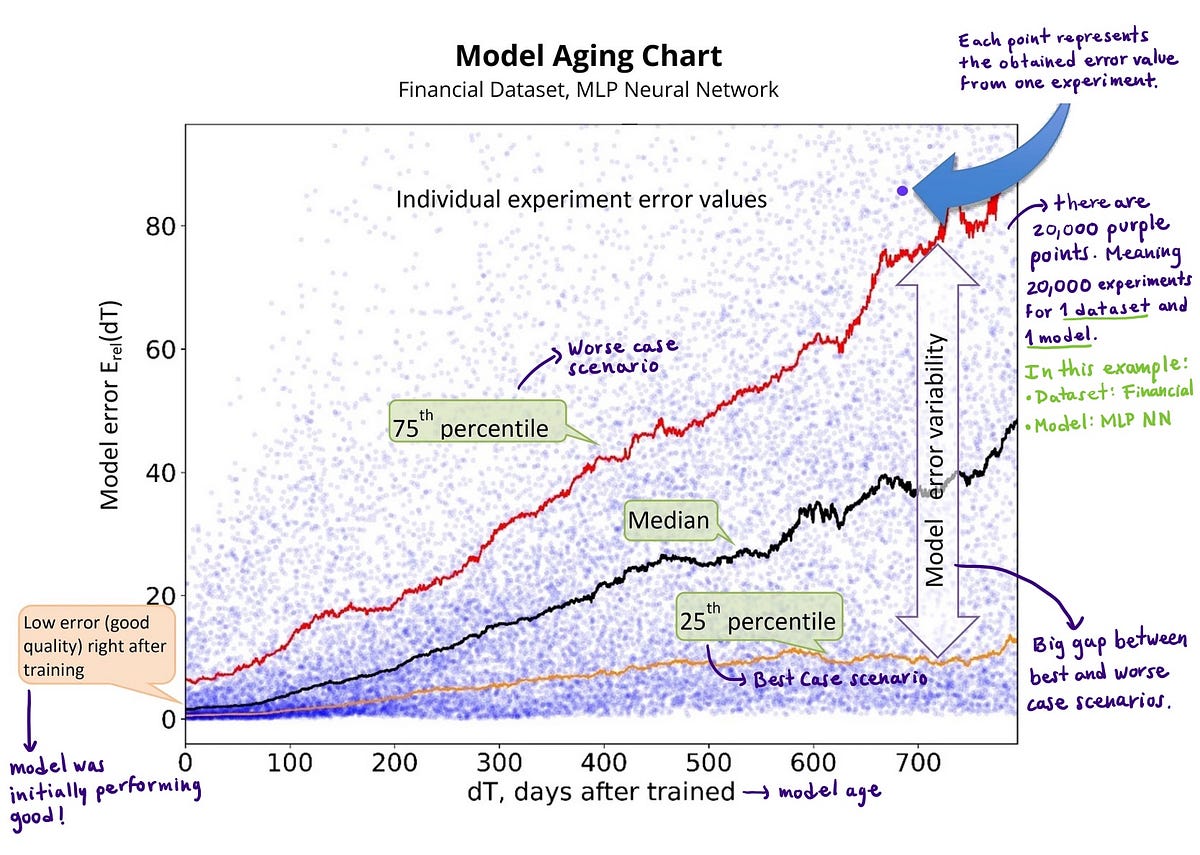
The researchers ran 20,000 experiments of this kind for every dataset-model pair! The place t_0 and dT have been randomly sampled from a uniform distribution.
After working all of those experiments, they reported an ageing mannequin chart for every dataset-model pair. This chart comprises 20,000 purple factors, every representing the relative efficiency error E_rel obtained at dT days after coaching.
The chart summarizes how the mannequin’s efficiency modifications when the mannequin’s age will increase. Key takeaways:
- The error will increase over time: the mannequin turns into much less and fewer performant as time passes. This can be taking place on account of a drift current in any of the mannequin’s options or on account of idea drift.
- The error variability will increase over time: The hole between the perfect and worst-case eventualities will increase because the mannequin ages. When an ML mannequin has excessive error variability, it signifies that it typically performs nicely and typically badly. The mannequin efficiency isn’t just degrading, nevertheless it has erratic habits.
The fairly low median mannequin error should create the phantasm of correct mannequin efficiency whereas the precise outcomes turn into much less and fewer sure.
After performing all of the experiments for all 4 (fashions) x 32 (datasets) = 128 (mannequin, dataset) pairs, temporal mannequin degradation was noticed in 91% of the circumstances. Right here we are going to have a look at the 4 most typical degradation patterns and their influence on ML mannequin implementations.
Though no robust degradation was noticed within the two examples beneath, these outcomes nonetheless current a problem. Trying on the authentic Affected person and Climate datasets, we are able to see that the affected person knowledge has a number of outliers within the Delay variable. In distinction, the climate knowledge has seasonal shifts within the Temperature variable. However even with these two behaviors within the goal variables, each fashions appear to carry out precisely over time.

The authors declare that these and comparable outcomes reveal that knowledge drifts alone can’t be used to elucidate mannequin failures or set off mannequin high quality checks and retraining.
We’ve additionally noticed this in observe. Information drift doesn’t essentially interprets right into a mannequin efficiency degradation. That’s the reason in our ML monitoring workflow, we give attention to efficiency monitoring and use knowledge drift detection instruments solely to analyze believable explanations of the degradation concern since knowledge drifts alone shouldn’t be used to set off mannequin high quality checks.
Mannequin efficiency degradation can even escalate very abruptly. Trying on the plot beneath, we are able to see that each fashions have been performing nicely within the first 12 months. However sooner or later, they began to degrade at an explosive charge. The authors declare that these degradations can’t be defined alone by a specific drift within the knowledge.

Let’s evaluate two mannequin ageing plots made out of the identical dataset however with totally different ML fashions. On the left, we see an explosive degradation sample, whereas on the proper, virtually no degradation was seen. Each fashions have been performing nicely initially, however the neural community appeared to degrade in efficiency sooner than the linear regression (labeled as RV mannequin).

Given this, and comparable outcomes, the authors concluded that Temporal mannequin high quality is determined by the selection of the ML mannequin and its stability on a sure knowledge set.
In observe, we are able to cope with this kind of phenomenon by constantly monitoring the estimated mannequin efficiency. This enables us to deal with the efficiency points earlier than an explosive degradation is discovered.
Whereas the yellow (twenty fifth percentile) and the black (median) traces stay at comparatively low error ranges, the hole between them and the pink line (seventy fifth percentile) will increase considerably with time. As talked about earlier than, this will create the phantasm of an correct mannequin efficiency whereas the actual mannequin outcomes turn into much less and fewer sure.

Neither the information nor the mannequin alone can be utilized to ensure constant predictive high quality. As an alternative, the temporal mannequin high quality is set by the steadiness of a particular mannequin utilized to the particular knowledge at a specific time.
As soon as we have now discovered the underlying explanation for the mannequin ageing drawback, we are able to seek for the perfect method to repair the issue. The suitable resolution is context-dependent, so there is no such thing as a easy repair that matches each drawback.
Each time we see a mannequin efficiency degradation, we must always examine the difficulty and perceive the reason for it. Automated fixes are virtually unimaginable to generalize for each state of affairs since a number of causes may cause the degradation concern.
Within the paper, the authors proposed a possible resolution to the temporal degradation drawback. It’s centered on ML mannequin retraining and assumes that we have now entry to newly labeled knowledge, that there are not any knowledge high quality points, and that there is no such thing as a idea drift. To make this resolution virtually possible, they talked about that one wants the next:
1. Alert when your mannequin should be retrained.
Alerting when the mannequin’s efficiency has been degrading isn’t a trivial process. One wants entry to the newest floor reality or have the ability to estimate the mannequin’s efficiency. Options like DLE and CBPE from NannyML can assist to try this. For instance, DLE (Direct Appears to be like Estimation) and CBPE (Confidence-based Efficiency Estimation) use probabilistic strategies to estimate the mannequin’s efficiency even when targets are absent. They monitor the estimated efficiency and alert when the mannequin has degraded.

2. Develop an environment friendly and strong mechanism for computerized mannequin retraining.
If we all know that there is no such thing as a knowledge high quality concern or idea drift, incessantly retraining the ML mannequin with the newest labeled knowledge may assist. Nonetheless, this will trigger new challenges, similar to lack of mannequin convergence, suboptimal modifications to the coaching parameters, and “catastrophic forgetting” which is the tendency of a synthetic neural community to abruptly neglect beforehand realized info upon studying new info.
3. Have fixed entry to the newest floor reality.
The latest floor reality will enable us to retrain the ML mannequin and calculate the realized efficiency. The issue is that in observe, floor reality is commonly delayed, or it’s costly and time-consuming to get newly labeled knowledge.
When retraining may be very costly, one potential resolution can be to have a mannequin catalog after which use the estimated efficiency to pick out the mannequin with the best-expected efficiency. This might repair the difficulty of various fashions ageing in another way on the identical dataset.
Different widespread options used within the business are reverting your mannequin again to a earlier checkpoint, fixing the difficulty downstream, or altering the enterprise course of. To be taught extra about when it’s best to use every resolution take a look at our earlier weblog put up on How to address data distribution shift.
The research by Vela et al. confirmed that the ML mannequin’s efficiency doesn’t stay static, even after they obtain excessive accuracy on the time of deployment. And that totally different ML fashions age at totally different charges even when educated on the identical datasets. One other related comment is that not all temporal drifts will trigger efficiency degradation. Due to this fact, the selection of the mannequin and its stability additionally turns into one of the vital crucial components in coping with efficiency temporal degradation.
These outcomes give a theoretical backup of why monitoring options are necessary for the ML business. Moreover, it exhibits that ML mannequin efficiency is liable to degradation. That is why each manufacturing ML mannequin should be monitored. In any other case, the mannequin might fail with out alerting the companies.
Vela, D., Sharp, A., Zhang, R., et al. Temporal high quality degradation in AI fashions. Sci Rep 12, 11654 (2022). https://doi.org/10.1038/s41598-022-15245-z
[ad_2]
Source link
