

[ad_1]
Understanding Transformer structure and its key insights in 5 minutes
That is the primary a part of the article’s prolonged model, quickly you can see its continuation here.
Writer’s word. For this very first half, I’ve determined to introduce the notions and ideas essential to get a greater understanding of Transformer fashions and to make it simpler to observe the following chapter. If you’re already aware of Transformers, you’ll be able to verify the final part to get a abstract of this text and be happy to leap to the second half, the place extra arithmetic and complicated notions are offered. Nonetheless, I hope you discover some worth within the explanations of this textual content too. Thanks for studying!
For the reason that launch of the most recent Giant Language Fashions (LLaM), just like the GPT sequence of OpenAI, the open supply mannequin Bloom or Google’s bulletins about LaMDA amongst others, Transformers have demonstrated their big potential and have change into the cutting-edge structure for Deep Studying fashions.
Though a number of articles have been written on transformers and the arithmetic beneath their hood [2] [3] [4], on this sequence of articles I’d prefer to current a whole overview combining what I’ve thought-about the most effective approaches, with my very own viewpoint and private expertise working with Transformer fashions.
This text makes an attempt to supply a deep mathematical overview of Transformer fashions, exhibiting the supply of their energy and explaining the explanation behind every of its modules.
Be aware. The article follows the unique transformer mannequin from the paper Vaswani, Ashish, et al. 2017.
Setting the surroundings. A short introduction to Pure Language Processing (NLP)
Earlier than getting began with the Transformer mannequin, it’s mandatory to know the duty for which they’ve been created, to course of textual content.
Since neural networks work with numbers, with a purpose to feed textual content to a neural community we should first rework it right into a numerical illustration. The act of remodeling textual content (or every other object) right into a numerical kind is known as embedding. Ideally, the embedded illustration is ready to reproduce traits of the textual content such because the relationships between phrases or the emotions of the textual content.
There are a number of methods to carry out the embedding and it’s not the aim of this text to elucidate them (extra info will be present in NLP Deep Studying), however reasonably we should always perceive their normal mechanisms and the outputs they produce. If you’re not aware of embeddings, simply consider them as one other layer within the mannequin’s structure that transforms textual content into numbers.
Probably the most generally used embeddings work on the phrases of the textual content, remodeling every phrase right into a vector of a very excessive dimension (the weather into which the textual content is split to use the embedding are known as tokens). Within the unique paper [1] the embedding dimension for every token/phrase was 512. It is very important word that the vector modulus can be normalized so the neural community is ready to study appropriately and keep away from exploding gradients.
An essential component of embedding is the vocabulary. This corresponds to the set of all tokens (phrases) that can be utilized to feed the Transformer mannequin. The vocabulary isn’t essentially to be simply the phrases used within the sentences, however reasonably every other phrase associated to its subject. As an illustration, if the Transformer shall be used to research authorized paperwork, each phrase associated to the bureaucratic jargon should be included within the vocabulary. Be aware that the bigger the vocabulary (whether it is associated to the Transformer job), the higher the embedding will have the ability to discover relationships between tokens.
Other than the phrases, there are another particular tokens added to the vocabulary and the textual content sequence. These tokens mark particular elements of the textual content like the start <START>, the top <END>, or padding <PAD> (the padding is added in order that all sequences have the identical size). The particular tokens are additionally embedded as vectors.
In arithmetic, the embedding house constitutes a normalized vector house through which every vector corresponds to a selected token. The idea of the vector house is decided by the relationships the embedding layer has been capable of finding among the many tokens. For instance, one dimension would possibly correspond to the verbs that finish in -ing, one other one could possibly be the adjectives with optimistic which means, and so on. Furthermore, the angle between vectors determines the similarity between tokens, forming clusters of tokens which have a semantic relationship.

Be aware 1. Though solely the duty of textual content processing has been talked about, Transformers are in actual fact designed to course of any kind of sequential information.

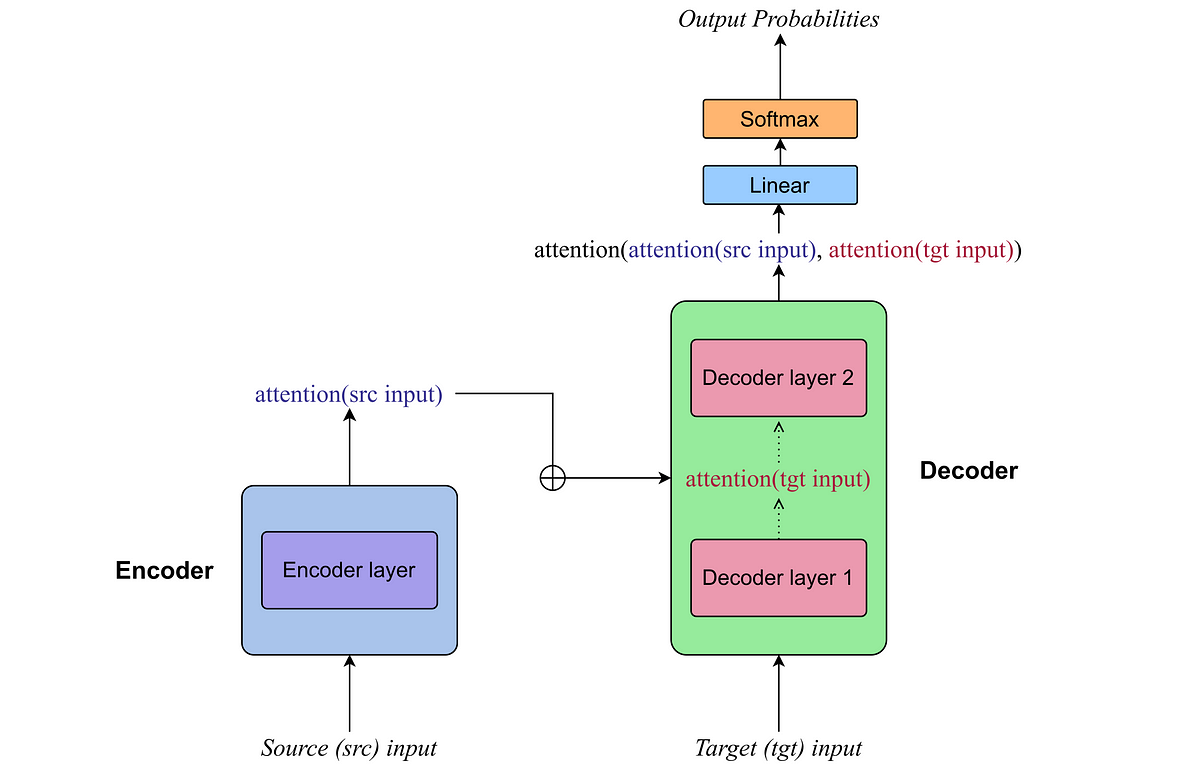
Above, is without doubt one of the most replicated diagrams within the final years of Deep Studying analysis. It summarizes the entire workflow of Transformers, representing every of the elements/modules concerned within the course of.
The next perspective view divides Transformers into Encoder (left blue block within the diagram) and Decoder (proper blue block).
For instance how Transformers work I’ll use the instance job of textual content translation from Spanish to English.
Be aware 2. I haven’t outlined but what consideration is, however primarily consider it as a operate that returns some coefficients that outline the significance of every phrase within the sentence with respect to the others.

Be aware 3. For readability, I’ll use the notation supply enter to consult with the Encoder’s enter (sentence in Spanish) and goal enter to the anticipated output launched within the Decoder (sentence in English). This notation will stay constant for the remainder of the article.
Now let’s have a more in-depth take a look at the Inputs (supply and goal) and the Output of the Transformer:
As we’ve seen, Transformer enter textual content is embedded right into a excessive dimensional vector house, so as a substitute of a sentence, a sequence of vectors is entered. Nonetheless, there exists a greater mathematical construction to signify sequences of vectors, the matrices! And even additional, when coaching a neural community, we don’t practice it pattern by pattern, we reasonably use batches through which a number of samples are packed. The ensuing enter is a tensor of form [N, L, E] the place N is the batch measurement, L the sequence size, and E the embedding dimension.

As for the output of the Transformer, a Linear + Softmax layer is utilized which produces some Output Chances (recall that the Softmax layer outputs a chance distribution over the outlined courses). The output of the Transformer isn’t the translated sentence however a chance distribution over the vocabulary that determines the phrases with the best chance. Be aware that for every place within the sequence size, a chance distribution is generated to pick the following token with a better chance. Since throughout coaching the Transformer processes all of the sentences directly, we get as output a 3D tensor that represents the chance distributions over the vocabulary tokens with form [N, L, V] the place N is the batch measurement, L the sequence size, and V the vocabulary size.

Lastly, the anticipated tokens are those with the best chance.
Be aware 3. As defined within the Introduction to NLP part, all of the sequences after the embedding have the identical size, which corresponds to the longest doable sequence that may be launched/produced in/by the Transformer.
For the ultimate part of the article’s Half 1, I’d prefer to make some extent in regards to the Coaching vs Predicting phases of Transformers.
As defined within the earlier part, Transformers take two inputs (supply and goal). Throughout Coaching, the Transformer is ready to course of all of the inputs directly, which means the enter tensors are solely handed one time by way of the mannequin. The output is successfully the third-dimensional chance tensor offered within the earlier determine.

Quite the opposite, within the Prediction part, there isn’t any goal enter sequence to feed the Transformer (we wouldn’t want a Deep Studying mannequin for textual content translation if we already know the translated sentence). So, what will we enter as goal enter?
It’s at this level that the auto-regressive habits of Transformers involves mild. The Transformer can course of the supply enter sequence directly within the Encoder, however for the Decoder’s module, it enters a loop the place at every iteration it simply produces the following token within the sequence (a row chance vector over the vocabulary tokens). The chosen tokens with increased chance are then entered because the goal enter once more so the Transformer all the time predicts the following token based mostly on its earlier predictions (therefore the auto-regressive which means). However what ought to be the primary token entered on the very first iteration?
Keep in mind the particular tokens from the Introduction to NLP part? The primary component launched as goal enter is the start token <START> that marks the opening of the sentence.


This Half has been an Introduction to the primary notions and ideas essential to get a greater understanding of Transformers fashions. Within the subsequent Half, I’ll delve into every of the modules of the Transformers structure the place a lot of the arithmetic resides.
The primary concepts and ideas behind this text are:
- Transformers work in a normalized vector house outlined by the embedding system and the place every dimension represents a attribute between tokens.
- Transformers inputs are tensors of form [N, L, E] the place N denotes the batch measurement, L is the sequence size (fixed for each sequence due to the padding) and E represents the embedding dimension.
- Whereas the Encoder finds relationships between tokens within the supply embedding house, the Decoder’s job is to study the projection from the supply house into the goal house.
- Transformer’s output is a line vector whose size is the same as the vocabulary’s measurement and the place every coefficient represents the chance of the corresponding listed token being positioned subsequent within the sequence.
- Throughout coaching, Transformer processes all its inputs directly, outputting a [N, L, V] tensor (V is the vocabulary size). However throughout predicting, Transformers are auto-regressive, predicting token by token all the time based mostly on their earlier predictions.
Quickly the following article’s half shall be obtainable here
[ad_2]
Source link
