

[ad_1]
Resolution-making and knowledge-intensive search are two important abilities for large-scale pure language brokers in unfamiliar settings. OpenAI’s GPT-3 and Google’s PaLM are simply two examples of LLMs which have proven spectacular efficiency on varied benchmarks. These fashions’ human-like skills to understand duties in specified settings signify a serious step ahead in pure language processing.
The excessive syntactic limitations that would result in false-negative errors in complicated duties will be overcome by brokers if they’re grounded in pure language. Nonetheless, as a consequence of their giant and infrequently unbounded state areas, pure language RL brokers current a major problem for studying optimum insurance policies.
Numerous decision-making approaches have been proposed to assist pure language brokers make selections in a text-based setting with out the good thing about a realized coverage. Nonetheless, the mannequin turns into extra susceptible to hallucinating over longer sequences, decreasing the accuracy of those strategies because the variety of subtasks will increase.
Pure language brokers can resolve duties extra intuitively because of the large-scale LLMs’ superior human-like qualities. Human-in-the-loop (HITL) strategies have been extensively used to extend efficiency by rerouting the agent’s reasoning hint after errors. Though this technique improves efficiency with little human involvement, it isn’t autonomous as a result of it requires trainers to watch the trajectory at every time interval.
Researchers from Northeastern College and the Massachusetts Institute of Expertise imagine that if given an opportunity to shut the trial-and-error loop independently, LLMs would make good use of self-optimization primarily based on pure language.
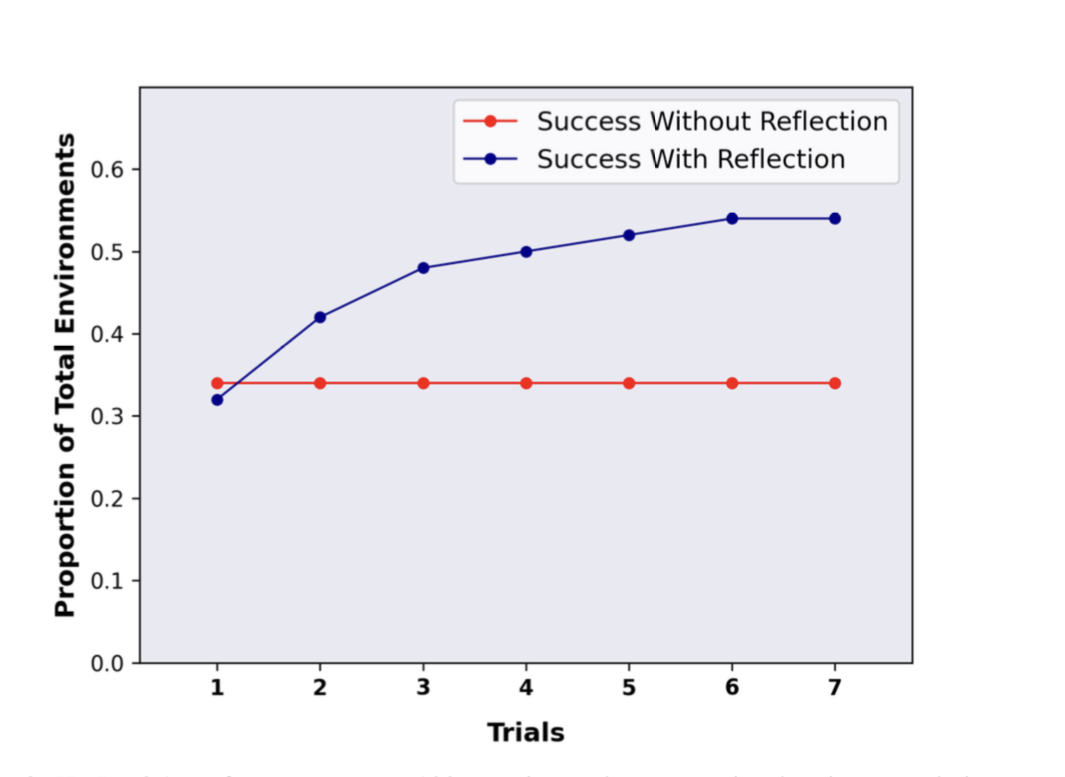
To confirm their speculation, the crew implements a self-reflective LLM and a simple heuristic for figuring out hallucination and ineffective motion execution inside an LLM-based agent utilizing an method known as Reflexion. They then put the agent by way of its paces on two totally different learning-from-error benchmarks—the text-based AlfWorld and the question-answering HotPotQA. Consequently, effectivity in decision-making and different knowledge-based duties is elevated.
The ReAct problem-solving method is enhanced by the Reflexion agent’s capability to replicate on its efficiency, resulting in a 97% success discovery price on the AlfWorld benchmark in simply 12 autonomous trials. It is a important enchancment over the 75% accuracy achieved by the bottom ReAct agent. 100 questions had been taken from HotPotQA, and a ReAct agent primarily based on Reflexion was examined. In comparison with a baseline ReAct agent, the agent outperformed it by 17% because of the iterative refinement of its content material search and extraction primarily based on recommendation from its reminiscence. Importantly, Reflexion will not be constructed to attain near-perfect accuracy scores; fairly, it goals to point out how studying from trial and error can facilitate discovery in duties and environments beforehand thought unattainable to resolve.
The crew highlights that their Reflexion will be utilized in tougher issues, akin to the place the agent must be taught to generate novel concepts, examine beforehand unseen state areas, and assemble extra exact motion plans primarily based on its expertise historical past.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to affix our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in varied fields. She is obsessed with exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
