

[ad_1]
Giant Language Fashions (LLMs) have proven they’ll adapt to focus on duties throughout inference by a course of often called few-shot demonstrations, typically often called in-context studying. This functionality has develop into more and more apparent as mannequin sizes scale up, with LLMs displaying rising options. One rising expertise is the capability to generalize to unknown duties by following instructions. Instruction tuning, or RLHF, is likely one of the instruction studying approaches recommended to boost this functionality. Prior analysis, nonetheless, largely targeting instruction-learning strategies primarily based on fine-tuning. The mannequin is multi-task fine-tuned on quite a few duties with directions, necessitating many backpropagation procedures.
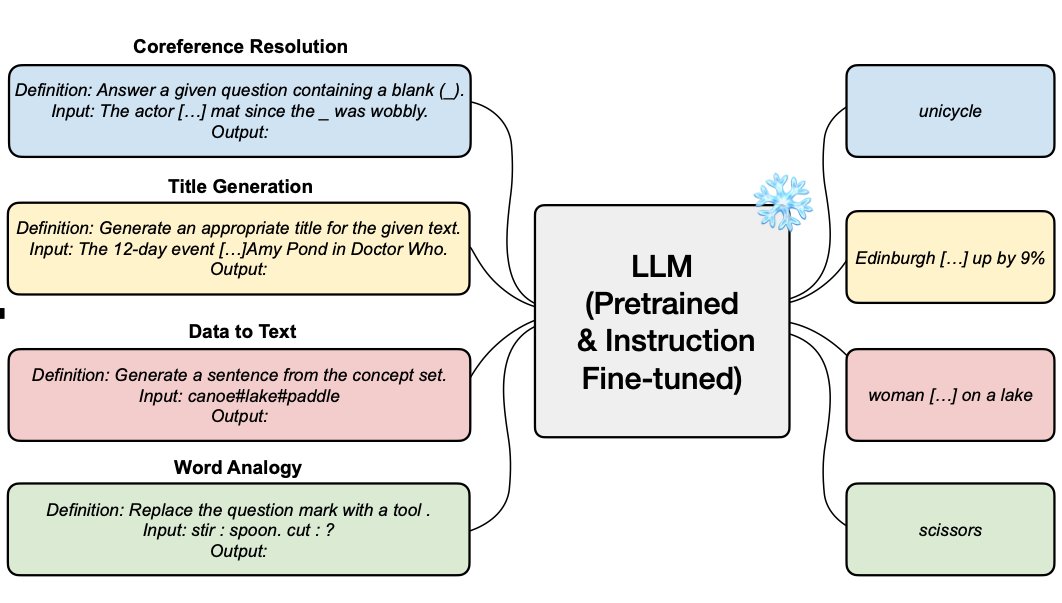
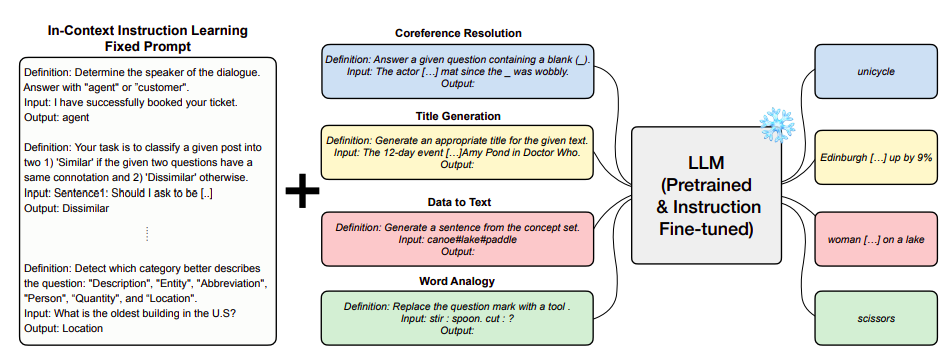
A gaggle of researchers from KAIST and LG Analysis reveals that In-Context Instruction Studying (ICIL), which entails studying to comply with directions throughout inference by way of in-context studying, is advantageous for each pretrained fashions which are available and fashions which were particularly tuned to comply with directions, as proven in Determine 1. The immediate utilized by ICIL includes many cross-task examples, every of which is an occasion of a job’s schooling, enter, and output. Since they utterly exclude the capabilities used for demonstrations from the analysis set and since they make use of the identical set of protests for all analysis duties, treating them as a single fastened immediate, as illustrated in Determine 2, ICIL is a zero-shot studying strategy.

They create a set instance set utilizing an easy heuristic-based sampling technique that works nicely for numerous downstream duties and mannequin sizes. They’ll consider and duplicate baseline zero-shot efficiency for brand new goal duties or fashions with out relying on exterior instruments by prepending the identical fastened demonstration set for all jobs. Determine 1 reveals that ICIL significantly improves the generalization efficiency on the zero-shot problem of varied pretrained LLMs that aren’t fine-tuned to obey directions.
Their knowledge exhibit that the number of classification duties that function clear response choices within the instruction is what makes ICIL profitable. Importantly, even smaller LLMs with ICIL carry out higher than bigger language fashions with out ICIL. For instance, the 6B-sized ICIL GPT-J outperforms the 175B-sized Commonplace Zero-shot GPT-3 Davinci by 30. Second, they exhibit how including ICIL to instruction-fine-tuned LLMs enhances their capability to comply with zero-shot directions, significantly for fashions with greater than 100B parts. This implies that the influence of ICIL is additive to the influence of instruction modification.
That is true even for technology goal duties, opposite to earlier analysis suggesting that few-shot in-context studying requires retrieving examples similar to the goal job. Much more surprisingly, they discover that efficiency will not be noticeably impacted when random phrases are substituted for the enter occasion distribution of every instance. Primarily based on this strategy, they suggest that LLMs, reasonably than relying on the difficult connection between instruction, enter, and output, study the correspondence between the response possibility supplied within the instruction and the manufacturing of every demonstration throughout inference. The aim of ICIL, in response to this principle, is to help LLMs in specializing in the goal instruction to find the alerts for the response distribution of the goal job.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with folks and collaborate on fascinating tasks.
[ad_2]
Source link
