

[ad_1]
Picture mixing is a main technique in pc imaginative and prescient, one of the crucial recognized branches within the synthetic intelligence element. The aim is to mix two or extra pictures to supply a novel mixture that comes with the best features of every enter picture. This technique is extensively utilized in varied software fields, together with image modifying, pc pictures, and medical imaging.
Picture mixing is continuously utilized in synthetic intelligence actions equivalent to image segmentation, object identification, and picture super-resolution. It’s essential in enhancing picture readability, which is crucial for a lot of makes use of, equivalent to robotics, automated driving, and surveillance.
Through the years, a number of picture mixing methods have been created, primarily counting on warping a picture by way of 2D affine transformation. Nonetheless, these approaches don’t account for the discrepancy in 3D geometric options like pose or form. 3D alignment is rather more difficult to realize, because it requires inferring the 3D construction from a single view.
To handle this difficulty, a 3D-aware picture mixing technique primarily based on generative Neural Radiance Fields (NeRFs) has been proposed.
The aim of generative NeRFs is to be taught a method to synthesize pictures in 3D utilizing solely collections of 2D single-view pictures. Due to this fact, the authors undertaking the enter pictures to the amount density illustration of generative NeRFs. To scale back the dimensionality and complexity of knowledge and operations, the 3D-aware mixing is then carried out on these NeRFs’ latent illustration areas.
Concretely, the formulated optimization downside considers the latent code’s influence in synthesizing the blended picture. The aim is to edit the foreground primarily based on the reference pictures whereas preserving the background of the unique picture. As an example, if the 2 thought of pictures have been faces, the framework should exchange the facial traits and options of the unique picture with those from the reference picture whereas maintaining the remaining unchanged (hair, neck, years, environment, and so forth.).
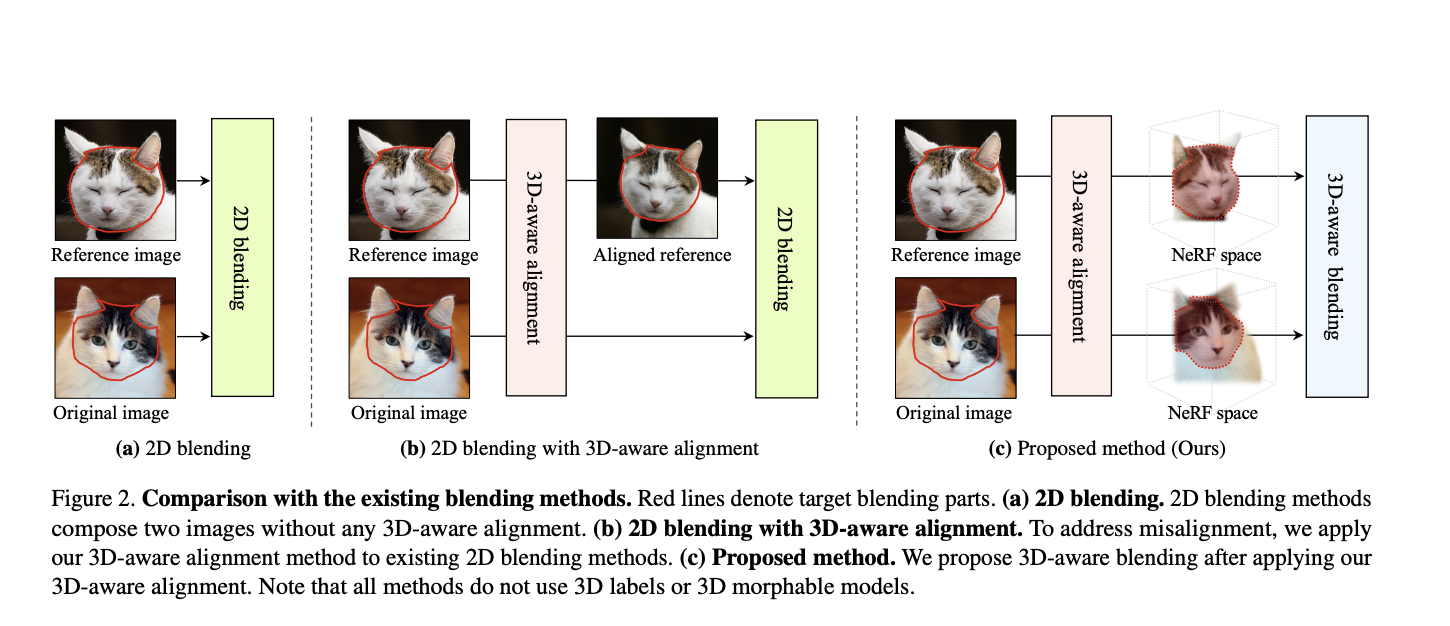
An outline of the structure in comparison with earlier methods is proposed within the image beneath.

The primary technique consists of the only 2D mixing of two 2D pictures with out alignment. An enchancment may be discovered by supporting this 2D mixing technique with the 3D-aware alignment with generative NeRFs. To additional exploit 3D info, the ultimate structure infers on two pictures in NeRFs’ latent illustration areas as a substitute of 2D pixel house.
3D alignment is achieved by way of a CNN encoder, which infers the digicam pose of every enter picture, and by way of the latent code of the picture itself. As soon as the reference picture is appropriately rotated to mirror the unique picture, the NeRF representations of each pictures are computed. Lastly, the 3D transformation matrix (scale, translation) is estimated from the unique picture and utilized to the reference picture to acquire a semantically-accurate mix.
The outcomes on unaligned pictures with completely different poses and scales are reported beneath.

In accordance with the authors and their experiments, this technique outperforms each basic and learning-based strategies relating to each photorealism and faithfulness to the enter pictures. Moreover, exploiting latent-space representations, this technique can disentangle coloration and geometric modifications throughout mixing and create view-consistent outcomes.
This was the abstract of a novel AI framework for 3D-aware Mixing with Generative Neural Radiance Fields (NeRFs).
In case you are or wish to be taught extra about this framework, you could find beneath a hyperlink to the paper and the undertaking web page.
Take a look at the Paper, Github, and Project. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to affix our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Daniele Lorenzi obtained his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Data Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s at the moment working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embrace adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
[ad_2]
Source link
