


[ad_1]
On account of latest developments within the underlying modeling strategies, generative fashions of images have attracted curiosity like by no means earlier than. The simplest fashions of right this moment are primarily based on diffusion fashions, autoregressive transformers, and generative adversarial networks. Significantly desired options of diffusion fashions (DMs) embrace their resilient and scalable coaching purpose and tendency to wish fewer parameters than their transformer-based equivalents. The paucity of large-scale, generic, and publicly accessible video datasets and the excessive computational price concerned with coaching on video knowledge are the important thing explanation why video modeling has lagged. On the similar time, the image area has made large strides.
Though there’s a wealth of analysis on video synthesis, most efforts, together with earlier video DMs, solely produce low-resolution, steadily brief movies. They create prolonged, high-resolution movies by making use of video fashions to precise points. They think about two pertinent real-world video technology points: (i) text-guided video synthesis for producing inventive content material and (ii) video synthesis of high-resolution real-world driving knowledge, which has nice potential as a simulation engine in autonomous driving. To do that, they depend on latent diffusion fashions (LDMs), which may reduce the numerous computational load when studying from high-resolution photos.

They generate temporally coherent movies utilizing pre-trained picture diffusion fashions. The mannequin first generates a batch of samples which can be impartial of each other. The samples are temporally aligned and create coherent movies after temporal video fine-tuning.
Researchers from LMU Munich, NVIDIA, Vector Institute, the College of Toronto, and the College of Waterloo suggest Video LDMs and increase LDMs to high-resolution video creation, a course of requiring a lot computing energy. In distinction to earlier analysis on DMs for video creation, their Video LDMs are initially pre-trained on photos solely (or use current pre-trained picture LDMs), permitting us to benefit from big picture datasets. After including a time dimension to the latent house DM, they convert the LDM picture generator right into a video generator by fixing the pre-trained spatial layers and coaching simply the temporal layers on encoded image sequences or movies (Fig. 1). To determine temporal consistency in pixel house. They regulate LDM’s decoder in the same method (Fig. 2).
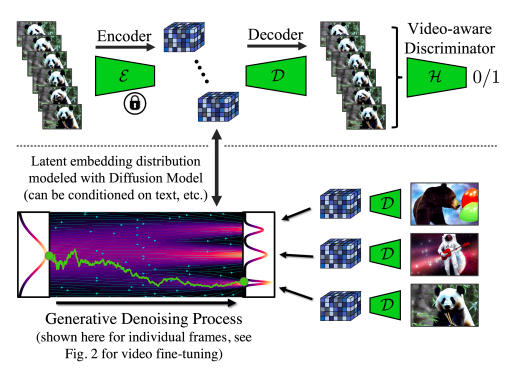
In addition they temporally align pixel house and latent DM upsamplers, steadily used for picture super-resolution, making them into time-consistent video super-resolution fashions to additional enhance the spatial decision. Their method, which builds on LDMs, might produce globally coherent and prolonged movies utilizing little reminiscence and processing energy. The video upsampler solely has to perform regionally for synthesis at extraordinarily excessive resolutions, leading to little coaching and computing calls for. To attain cutting-edge video high quality, they take a look at their know-how utilizing 5121024 precise driving situation movies and synthesize movies which can be a number of minutes lengthy.
Moreover, they improve a potent text-to-image LDM often called Secure Diffusion such that it might be used to create text-to-video with a decision of as much as 1280 x 2048. They will make the most of a fairly small coaching set of captioned movies since they should prepare the temporal alignment layers in such a situation. They current the primary occasion of personalised text-to-video creation by transferring the realized temporal layers to variously configured text-to-image LDMs. They anticipate that their work will pave the best way for more practical digital content material technology and simulation of autonomous driving.
The next are their contributions:
(i) They supply a sensible technique for growing LDM-based video manufacturing fashions with excessive decision and long-term consistency. Their vital discovery is to make use of pre-trained picture DMs to generate movies by including temporal layers that may prepare photos to align constantly all through time (Figs. 1 and a pair of).
(ii) They additional fine-tune super-resolution DMs, that are broadly used within the literature concerning timing.
(iii) They will produce a number of minute-long movies and obtain state-of-the-art high-resolution video synthesis efficiency on actual driving situation recordings.
They (i) improve the publicly accessible Secure Diffusion text-to-image LDM into a strong and expressive text-to-video LDM (ii), (iii) present that the realized temporal layers could also be built-in with different picture mannequin checkpoints (equivalent to DreamBooth), and (iv) do the identical for the realized temporal layers.
Try the Paper and Project. Don’t neglect to affix our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra. If in case you have any questions concerning the above article or if we missed something, be happy to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
