


[ad_1]
That is the third and ultimate installment in this blog series evaluating two main open supply pure language processing software program libraries: John Snow Labs’ NLP for Apache Spark and Explosion AI’s spaCy. Within the earlier two components, we walked by the code for coaching tokenization and part-of-speech fashions, working them on a benchmark knowledge set, and evaluating the outcomes. On this half, we examine the accuracy and efficiency of each libraries on this and extra benchmarks, and supply suggestions on which use circumstances match every library finest.
Accuracy
Listed here are the accuracy comparisons from the fashions coaching in Part 1 of this blog series:

Be taught quicker. Dig deeper. See farther.
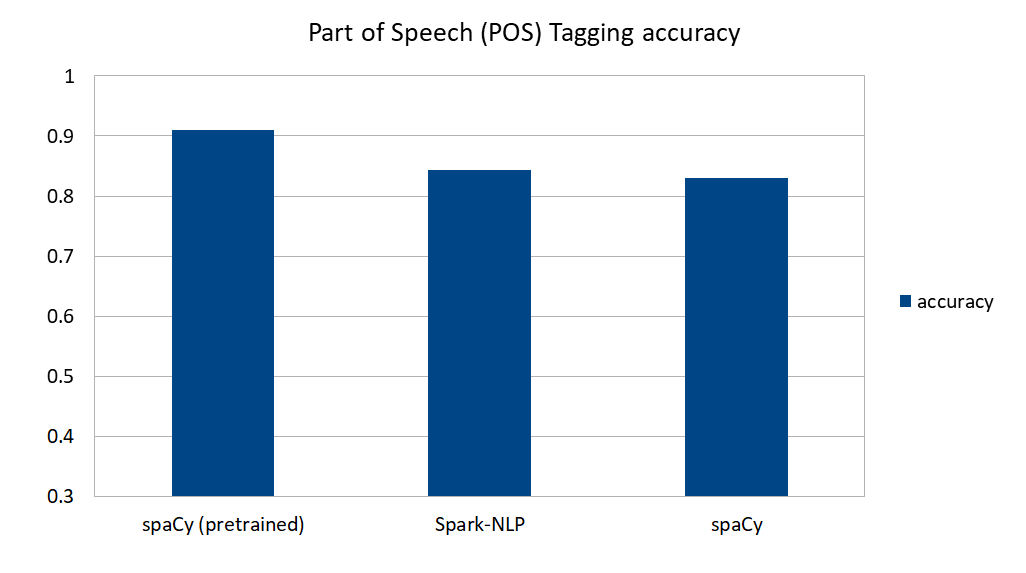
spaCy’s pre-trained mannequin does an amazing job predicting part-of-speech tags in English textual content. In case your textual content is commonplace, news- or article-based textual content (i.e., not domain-specific textual content like authorized paperwork, monetary statements, or medical information), and in one of many seven languages supported by spaCy, this can be a nice approach to go. Be aware that pretrained outcomes right here embrace our customized tokenizer, in any other case accuracy (and notably the ratio of matched tokens) would go down (see Determine 2).
spaCy’s self-trained mannequin and Spark-NLP carry out equally when skilled utilizing the identical coaching knowledge, at about 84% accuracy.
A significant impression of spaCy’s accuracy appears to come back not from skilled knowledge however from the English vocab content material, the place Spark-NLP assumes nothing on language—it’s absolutely language agnostic—and solely learns from regardless of the annotators on the pipeline get to know. Because of this the identical code and algorithms, on coaching knowledge from one other language, ought to work with out change.
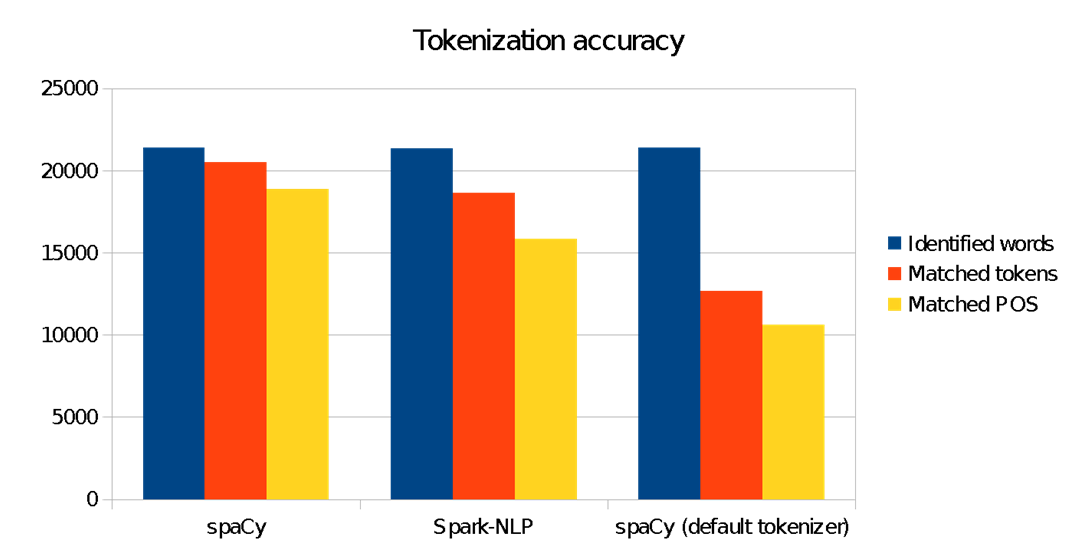
We see right here that our modified spacy tokenizer makes important impression to raised match our goal ANC corpus tokens. Utilizing “out-of-the-box” spaCy for this benchmark would ship inferior outcomes. This is quite common in pure language understanding: domain-specific fashions should be skilled to study the nuances, context, jargon, and grammar of the enter textual content.
Efficiency
Though issues seems joyful after we practice and predict about 77 KB of .txt recordsdata (leading to 21,000 phrases to foretell and examine), after we practice in opposition to twice the variety of recordsdata, and predict 9,225 recordsdata versus 14, issues don’t look so joyful anymore. After all, this isn’t “huge knowledge” by any measure, however extra real looking than a toy/debugging situation. Listed here are the details:
Spark-NLP 75mb prediction Time to coach: 4.798381899 seconds Time to foretell + gather: 311.773622473 seconds Whole phrases: 13,441,891
Coaching on spaCy was just a little bit extra troublesome as a result of I confronted a number of points on bizarre characters and textual content format in coaching knowledge—regardless that I’d already cleaned it within the coaching algorithm we noticed earlier than. After working it round, I obtained an exponential enhance within the period of time to coach, so I needed to estimate the period of time it could take, primarily based on the way it scaled as I elevated the variety of recordsdata within the coaching folder, which returned about two hours or extra.
SpaCy 75mb prediction Time to coach: 386.05810475349426 seconds Time to foretell + gather: 498.60224294662476 seconds Whole phrases: 14,340,283
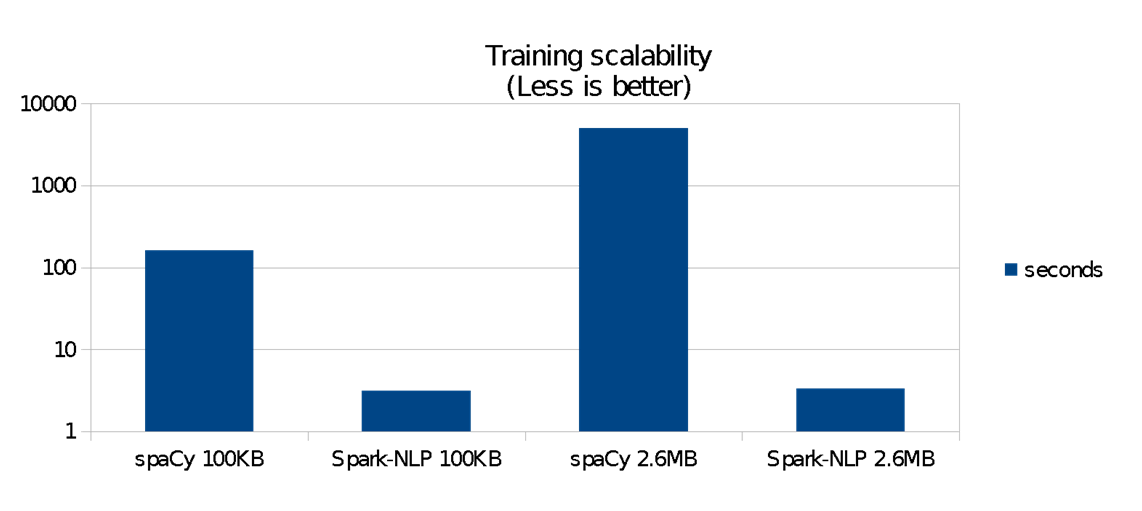
Determine 3 reveals that for this 75mb benchmark:
- Spark-NLP was greater than 38 occasions quicker to coach 100 KB of information and about 80 occasions quicker to coach 2.6 MB. Scalability distinction is important.
- Spark-NLP’s coaching itself didn’t develop considerably when knowledge grew from 100 KB to 2.6 MB
- spaCy’s coaching time grows exponentially as we enhance the information measurement
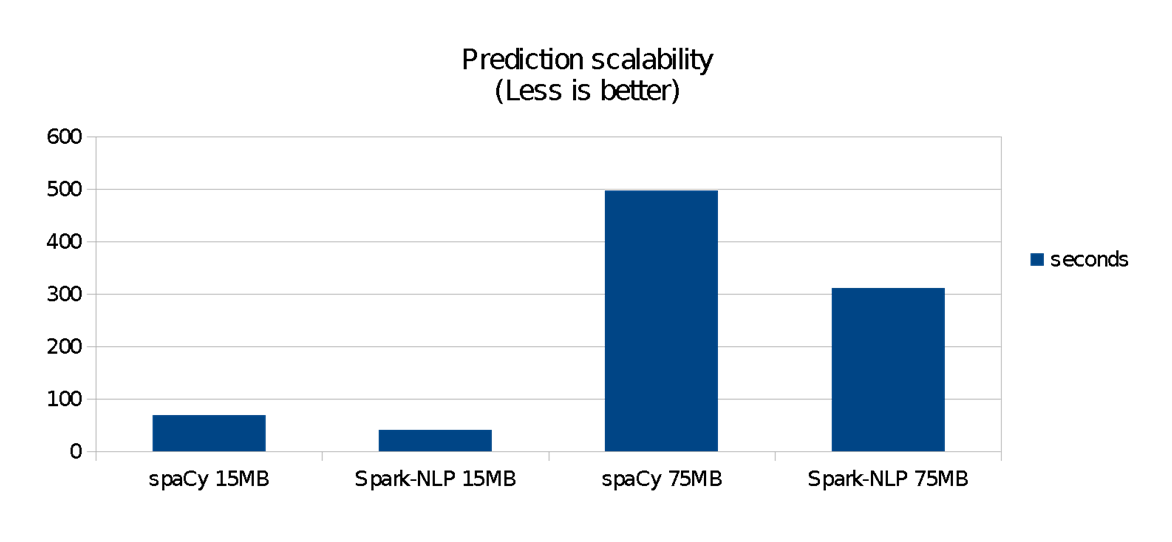
Determine 4 reveals the runtime efficiency comparability of working the Spark-NLP pipeline—i.e., utilizing the fashions after the coaching part is completed. spaCy is quick on small knowledge units, but it surely doesn’t scale in addition to Spark-NLP does. For these benchmarks:
- spaCy was quicker on 140 KB knowledge units (each libraries completed in lower than a second)
- Spark-NLP was 1.4 occasions quicker on a 15 MB knowledge set (roughly 40 versus 70 seconds)
- Spark-NLP was 1.6 occasions quicker on a 75 MB knowledge set, taking about half the time to finish (roughly 5 versus 9 minutes)
spaCy is extremely optimized for single-machine execution. It’s written from the bottom up in Cython, and was validated in 2015 (two years earlier than Spark-NLP grew to become obtainable) as having the quickest syntactic parser when in comparison with different libraries written in Python, Java, and C++. spaCy doesn’t have the overhead of the JVM and Spark that Spark-NLP has, which provides it a bonus for small knowledge units.
Alternatively, the heavy optimization that was carried out on Spark over time—particularly for single-machine, standalone mode—shines right here by taking the lead in knowledge units as small as a number of megabytes. Naturally, this benefit turns into extra substantial as the information measurement grows, or because the complexity of the pipeline (extra naturl language processing (NLP) phases, including machine studying (ML) or deep studying (DL) phases) grows.
Scalability
Exterior of those benchmarks, Spark scales as Spark does. How properly depends upon the way you partition your knowledge, whether or not you will have huge or tall tables (the latter are higher in Spark), and most significantly, whether or not you utilize a cluster. Right here, for instance, every part is on my native machine, and I’m working a groupBy filename operation, which suggests my desk is wider than taller, since for each filename there may be numerous phrases. If I may, I might most likely additionally keep away from calling a gather(), which hits onerous on my driver reminiscence, versus storing the end in distributed storage.
On this case, for instance, if I carried out the groupBy operation after the remodel() step—principally merging the POS and tokens after the prediction—I’d be reworking a a lot taller desk than the earlier one (960,302 traces as a substitute of 9,225, which was the variety of recordsdata). I even have management over whether or not I oversubscribe my CPU cores into Spark (e.g., native[6]) and the variety of partitions I inject into the remodel operation. There may be normally a bell form in efficiency when tuning Spark efficiency; in my case, the optimum was about six subscribed cores and 24 partitions.
On spaCy, the parallel algorithm I confirmed within the earlier sections doesn’t appear to considerably impression efficiency, whereas solely gaining a number of seconds out of the overall prediction time.
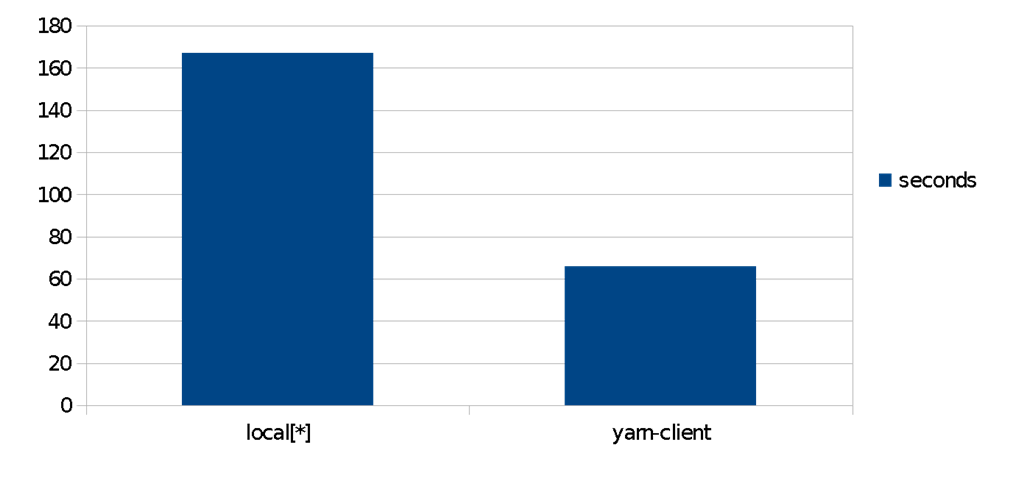
For an Amazon EMR cluster, in a easy comparability of the identical algorithms, we discover a 2.5x speedup within the time for POS prediction when using a distributed yarn cluster in opposition to a local-only counterpart on the identical node. Knowledge units on this situation have been put in HDFS datanodes. In apply, this implies you may obtain completely different price/efficiency tradeoffs, utilizing configuration solely, with linear scaling. It is a core good thing about Spark, Spark ML, and Spark-NLP.
Conclusion
The use circumstances for the 2 libraries are fairly completely different. In case your wants are towards plugging in a small knowledge set and getting output rapidly, then spaCy is a winner: you obtain your mannequin per language, course of the information, and go it line by line to the NLP object. It accommodates a big vocabulary set of methods on the language plus a bunch of state-of-the-art skilled fashions that may reply again with extremely optimized C++ (Cython) efficiency. If you wish to parallelize your job, customise a element (like we did for the tokenizer), or practice fashions to suit your domain-specific knowledge, then spaCy makes you undergo its API and write extra code.
Alternatively, when you have a big job forward, then Spark-NLP shall be far quicker, and from a sure scale, the one selection. It robotically scales as you plug in bigger knowledge units or develop your Spark cluster. It’s between one and two orders of magnitude quicker for coaching NLP fashions, holding for a similar degree of accuracy.
spaCy comes with a set of beautifully tuned fashions for quite a lot of frequent NLP duties. Spark-NLP doesn’t (on the time of penning this submit) include pre-trained fashions. spaCy fashions are “black field” and are normally inside 1% of the cutting-edge, in case your textual content is just like what the fashions have been skilled on. When coaching domain-specific fashions with Spark-NLP, pipelines are language agnostic, and their result’s strictly the sum of their components. Each annotator works on the information offered to it, and every one among them will talk with different annotators to realize a ultimate end result. You possibly can inject a spell checker, a sentence detector, or a normalizer, and it’ll have an effect on your consequence with out having to write down extra code or customized scripts.
We hope you will have loved this overview of both libraries, and that it’s going to aid you ship your subsequent NLP challenge quicker and higher. In case you are concerned with studying extra, there shall be hands-on, half-day tutorials on “Pure language understanding at scale with spaCy and Spark ML” on the upcoming Strata Data San Jose in March and Strata Data London in Could.
[ad_2]
Source link
