

[ad_1]
NLP Tutorial
Creating a brand new dataset by utilizing NLP translation

Pure language processing fashions are at present a scorching matter. The discharge of ‘Consideration Is All You Want’ by Google [1] has spurred the event of many Transformer fashions like BERT, GPT-3, and ChatGPT which have obtained a whole lot of consideration everywhere in the world. Whereas many language fashions are educated on English or a number of languages, fashions and datasets for particular languages may be tough to seek out or of questionable high quality.
NLP has an enormous quantity of purposes together with however not restricted to translation, info extraction, summarization and query answering, the latter of which is one thing I’ve personally been engaged on. As an Utilized Synthetic Intelligence pupil, I’ve been engaged on query answering NLP fashions and have discovered it difficult to discover a helpful Dutch dataset for coaching functions. To deal with this situation, I’ve developed a translation answer that may be utilized to numerous NLP issues and just about all languages, which can be of curiosity to different college students. I really feel like this additionally has an important worth for the AI growth and analysis group. There are principally no Dutch datasets obtainable particularly for particular duties like query answering. By translating a big and well-known dataset, I’ve been in a position to create a Dutch query answering mannequin with comparatively low effort.
In case you are excited about studying extra about my course of, the challenges I confronted, and the potential purposes of this answer, please proceed studying. This text is aimed toward college students with a primary NLP background. Nonetheless, I’ve additionally included a refresher and introductions to numerous ideas for many who are usually not but acquainted within the discipline or just want a refresher.
To correctly clarify my answer for utilizing translated datasets, I’ve divided this text into two foremost sections, the interpretation of a dataset and the coaching of a query answering mannequin. I’ve written this text in a manner that intends to indicate you my progress in the direction of the answer but additionally as a step-by-step information. The article consists of the next chapters:
- Refresher on NLP and a brief history of NLP
- The problem, the dataset and question answering
- Translating the dataset
- Building a question answering model
- What has been achieved and what has not been achieved?
- Future plans
- Sources
To get a greater understanding of the varied components of this answer, I need to begin with refresher on NLP and its current historical past. The languages we all know may be cut up in two teams, formal and pure. Formal language refers to languages which have particularly been designed for particular duties like math and programming. A pure or atypical language is a language that has naturally been developed and advanced by people with none type of planning forward. This will take a number of types just like the completely different sorts of human speech we all know and even signal language [2].
NLP in its broadest type is the appliance of computational strategies to pure languages. By combining rule-based modelling of language with AI fashions, we’ve been in a position to get computer systems to ‘perceive’ our human language in a manner that permits it to course of it each in textual content and voice type [3]. The best way this understanding works — if it could even be known as understanding — is up for debate. However current developments like ChatGPT have proven that we people do typically really feel just like the output of those fashions makes it really feel sentient and like has a excessive stage of understanding [4].
After all, this understanding didn’t come out of nowhere. NLP has an enormous historical past relationship again to the Forties after World Struggle II [5]. Throughout this era, folks realized the significance of translation and hoped to create a machine that might achieve this mechanically. Nonetheless, this proved to be fairly the problem. Round 1960, NLP analysis cut up into rule-based and stochastic. Rule-based, or symbolic lined primarily formal languages and the technology of syntax. Most of the linguistic researchers and pc scientists on this group noticed this as the start of synthetic intelligence analysis. Stochastic analysis centered extra on statistics and issues like sample recognition between texts.
Since then, many extra developments on NLP have been made and lots of extra areas of analysis have emerged. Nonetheless, the precise textual content ensuing from NLP fashions has at all times been fairly restricted and didn’t have many real-world purposes. That’s, till the early 2000s. After this era developments in NLP made massive leaps each few years which led to the place we at the moment are.
Now that I’ve given a brief refresher on NLP it’s time to introduce the precise downside that I’ve been engaged on. Briefly, my objective was to coach a Dutch query answering machine studying mannequin. Nonetheless, the dearth of appropriate datasets made this fairly tough which is I created my very own by utilizing translation. On this article I’ll undergo the creation of a dataset and the coaching of the machine studying mannequin step-by-step so you possibly can observe alongside and both replicate the complete answer or choose the components which might be of significance to you.
This text may be cut up into two foremost parts. The primary one being the creation of a Dutch dataset and the second being the coaching of a query answering machine studying mannequin. On this chapter I’ll give some background info on them, introduce my options and clarify my selections.
The dataset
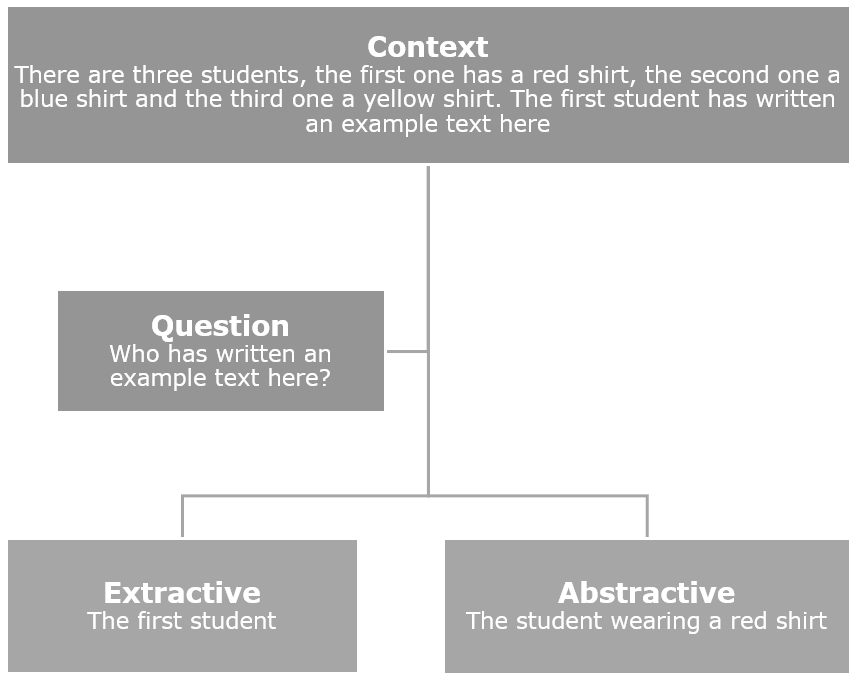
If we need to discover a helpful Dutch dataset you will need to take a look at what is precisely wanted to coach a query answering mannequin. There are two foremost approaches to the technology of solutions to questions. The primary one being extractive and the second being abstractive.
· Extractive query answering fashions are educated to extract a solution from the context (the supply textual content) [7]. Older approaches used to do that by coaching a mannequin to output a begin and finish index of the placement of the reply within the context. Nonetheless, the introduction of Transformers has made this method out of date.
· Abstractive query answering fashions are educated to generate new textual content based mostly on the context and the query [8].
Determine 1 exhibits an instance of the output extractive and abstractive fashions may give.
Though completely different approaches are potential, these days each extractive and abstractive query answering fashions are sometimes based mostly on Transformers like BERT [8], [9].

Based mostly on the details about extractive and abstractive fashions, we now know that we’d like a dataset with contexts, questions, solutions and, optionally, begin and finish indices of the placement of the reply within the context. I’ve explored the next choices to be able to discover a appropriate dataset.
- I’ve used A 2020 paper by Cambazoglu et al. [10] to get a transparent picture of what datasets can be found for query answering. Their analysis has resulted in a desk with probably the most outstanding query answering datasets. Sadly, none of those massive datasets are within the Dutch language.
- An alternative choice was Huggingface which hosts a big assortment of datasets [11]. At first look, there are a couple of query answering datasets obtainable for the Dutch language. Nonetheless, additional inspection exhibits that these datasets are sometimes incomplete, embody web site domains as an alternative of contexts or are a mixture of varied languages. These are fully unusable or too incomplete for use for our objective.
Concluding from these observations, there are virtually no public datasets that can be utilized to coach a Dutch query answering mannequin. Creating our personal dataset manually would take far an excessive amount of time so what different choices do we’ve? Firstly we might merely use an English mannequin, translate the enter from Dutch to English after which translate the output again to Dutch. Nonetheless, a fast check with Google Translate and this method has proven that the outcomes are removed from fascinating and nearly really feel passive aggressive. Maybe an excessive amount of info and context obtained misplaced throughout the double translation step? That results in the second choice, translating the complete dataset and coaching on it. Throughout my analysis I’ve come throughout a couple of cases the place this was talked about. For instance a submit by Zoumana Keita on Towardsdatascience [16] makes use of translation for information augmentation. Chapter three will dive into my execution of the interpretation of a dataset.
Lastly we have to choose what dataset to make use of for our translation method. Since we determined to translate the complete dataset, it doesn’t matter what language the unique dataset is in. The Stanford Question Answering Dataset (SQuAD) [12] appears to be fairly standard and is utilized by Paperswithcode for the query answering benchmark [13]. It additionally comprises a big quantity (100.000+) of questions with solutions and upon nearer inspection doesn’t appear to have any surprising information. That is the dataset we will likely be working with.
The machine studying mannequin
Now we’ve decided how we’re going to get a dataset; we have to determine what sort of machine studying mannequin will likely be appropriate for the objective of answering questions. Within the earlier chapter we’ve established that we will select between an extractive mannequin and an abstractive mannequin. In my analysis I’ve used an abstractive mannequin as a result of it’s based mostly on a more recent expertise and offers extra fascinating outcomes. Nonetheless, simply in case anybody needs to take this method for an extractive mannequin I’ll cowl that as properly. That is additionally in keeping with the number of the dataset because it comprises the beginning indices of solutions.
Coaching a Transformer from scratch could be, to say the least, inefficient. The e book switch Studying for Pure Language Processing by P. Azunre [14] goes in-depth on why switch studying is completed and exhibits a lot of examples on tips on how to do it. Numerous massive NLP fashions are hosted on Huggingface [15] and can be found for switch studying. I’ve chosen the t5-v1_1-base mannequin as a result of it’s multi-task educated on a number of languages. Chapter 4 will cowl the switch studying of this mannequin.
On this chapter I will likely be exhibiting how I’ve translated the dataset by giving snippets of code and explaining them. The code ensuing from these code blocks in succession is the complete dataset translation script I’ve written. Be at liberty to observe alongside or take particular components which might be of use to you.
Imports
The answer makes use of a couple of modules. To start with, we have to translate textual content in a manner that’s as quick as potential. In my analysis I’ve tried utilizing varied translation AI fashions from Huggingface however by far the quickest translator was the Googletrans module which makes use of the Google Translate API. The answer additionally makes use of Timeout from httpx to outline a timeout for the translations, json for SQuAD dataset parsing, Pandas for dataframes and Time to measure how lengthy every thing is taking.
from googletrans import Translator, constants
from httpx import Timeoutimport json
import pandas as pd
import time
Initialization
To start with we must always outline a couple of constants that will likely be used all through the script. For ease-of-access I’ve added the supply language and translation language right here.
The Googletrans module gives us with a Translator that may have a customized timout outlined. I’ve used a comparatively lengthy timeout as a result of translations saved timing out throughout my assessments. I’ll present a bit extra info on this situation additional alongside within the information.
src_lang = "en"
dest_lang = "nl"translator = Translator(timeout = Timeout(60))
Studying the SQuAD dataset
The next code extracts contexts, questions and solutions from the practice and validation json information. That is executed by studying the information as json format and looping by the info inside in a manner that extracts the three lists. For every query and reply, the context is copied and added to the contexts listing. This fashion we will simply entry a query with its related context and reply by utilizing an index.
def read_squad(path):
with open(path, 'rb') as f:
squad_dict = json.load(f)
contexts, questions, solutions = [], [], []
for group in squad_dict['data']:
for passage in group['paragraphs']:
context = passage['context']for qa in passage['qas']:
query = qa['question']
if 'plausible_answers' in qa.keys():
entry = 'plausible_answers'
else:
entry = 'solutions'
for reply in qa[access]:
contexts.append(context)
questions.append(query)
solutions.append(reply['text'])
return contexts, questions, solutions
train_c, train_q, train_a = read_squad('squad-train-v2.0.json')
val_c, val_q, val_a= read_squad('squad-dev-v2.0.json')
Timing
The next code gives us with a really tough estimation of how lengthy every translation takes.
def time_translation(entries, title):
start_time = time.time()
translation = translator.translate(entries[0], dest=dest_lang, src= src_lang)
period = time.time() - start_time
total_duration = len(entries)*period
print(f"translating {title} takes {total_duration/60/60} hours")time_translation(train_c, "practice contexts")
time_translation(train_q, "practice questions")
time_translation(train_a, "practice solutions")
time_translation(val_c, "validation contexts")
time_translation(val_q, "validation questions")
time_translation(val_a, "validation solutions")
Translating
Keep in mind how I discussed translations timing out? Throughout my analysis I saved bumping into the problem the place translations had been timing out and the ensuing dataset obtained corrupted. It seems that the Googletrans module shouldn’t be 100% dependable because it makes use of the Google Translate API. The best way I’ve discovered round that is to create a small wrapper perform that retains attempting to translate till it has been profitable. After doing this I now not skilled the timing out downside.
def get_translation(textual content):
success = False
translation = ""
whereas not success:
translation = translator.translate(textual content, dest=dest_lang, src=src_lang).textual content
success = True
return translation
Due to the way in which we’ve extracted contexts from the dataset, they’ve been duplicated for every query and reply pair. Merely translating all contexts could be redundant and really sluggish so the next translation perform compares the earlier context to the present one first. In the event that they match, the earlier translation is used.
def translate_context(contexts, title):
start_time = time.time()
context_current = ""
translated_contexts = []
index = 0for context in contexts:
index+=1
if context != context_current:
context_current = context
print(f"[{index}/{len(contexts)}]")
get_translation(context)
context_translated = get_translation(context)
translated_contexts.append(context_translated)
else:
translated_contexts.append(context_translated)
period = time.time() - start_time
print(f"Translating {title} took {spherical(period, 2)}s")
return translated_contexts
Translating the questions and solutions is fairly simple since we simply have to loop by the lists to translate all of them.
def translate_qa(enter, title):
start_time = time.time()
input_translated = []
index = 0
for textual content in enter:
text_nl = get_translation(textual content)
input_translated.append(text_nl)
index+=1
print(f"[{index}/{len(input)}]")
period = time.time() - start_time
print(f"Translating {title} took {spherical(period, 2)}s")
return input_translated
Now we will use the capabilities we’ve outlined to translate all components of the dataset.
train_c_translated = translate_context(train_c, "practice contexts")
train_q_translated = translate_qa(train_q, "practice questions")
train_a_translated = translate_qa(train_a, "practice solutions")val_c_translated = translate_context(val_c, "val contexts")
val_q_translated = translate_qa(val_q, "val questions")
val_a_translated = translate_qa(val_a, "val solutions")
Exporting
All that’s left is exporting the translations for later use. We are able to do that by changing the lists to dataframes after which utilizing the to_csv perform. One factor to remember is that the Googletrans module outputs translations with characters that aren’t included in utf-8 encoding. That’s the reason we use utf-16 encoding right here. It might make sense to transform it to utf-8 in some unspecified time in the future since that is perhaps extra helpful in an AI mannequin. Nonetheless, since we’re simply engaged on the dataset right here we will determine to depart that step for later after we are doing the info preprocessing for coaching our mannequin.
def save_data(information, title, header):
data_df = pd.DataFrame(information)
data_df.to_csv(title + "_pdcsv.csv", encoding='utf-16', index_label = "Index", header = [header])save_data(train_c_translated, "train_contexts", "contexts")
save_data(train_q_translated, "train_questions", "questions")
save_data(train_a_translated, "train_answers", "solutions")
save_data(val_c_translated, "val_contexts", "contexts")
save_data(val_q_translated, "val_questions", "questions")
save_data(val_a_translated, "val_answers", "solutions")
Determining tips on how to practice a query answering mannequin turned out to be a little bit of a problem. Nonetheless, by taking inspiration from a Pocket book by P. Suraj [17], I used to be in a position to create a Transformer based mostly mannequin that may be educated on query answering. Consistent with the Pocket book I’ve used Torch to create the mannequin.
Imports
Beginning with the imports, the next modules are used. We additionally outline some variables that outline the max in- and output size of the mannequin.
import pandas as pd
import unicodedataimport torch
from torch.utils.information import DataLoader
from transformers import T5Tokenizer
from transformers import T5ForConditionalGeneration
from transformers import AdamW
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from datetime import datetime
max_text_length = 512
max_output_length = 256
Loading information
Now we will load the dataset that we’ve beforehand created. Since we used Pandas to export a csv we will now simply load it and convert it to an array. I’ve additionally outlined a perform that will likely be used in a while to transform any coaching or enter information to utf-8 which is the format we are going to practice the mannequin on.
def load_data(path):
df = pd.read_csv(path, encoding='utf-16')
df = df.drop('Index', axis=1)
information = df.values.tolist()
information = [a[0] for a in information]
return informationdef to_utf8(textual content):
attempt:
textual content = unicode(textual content, 'utf-8')
besides NameError:
cross
textual content = unicodedata.normalize('NFD', textual content).encode('ascii', 'ignore').decode("utf-8")
return str(textual content)
Now we will really load the info. For the coaching of the mannequin I solely used the practice information and cut up this with a check dimension of 0.2.
contexts_csv = 'train_contexts_pdcsv.csv'
questions_csv = 'train_questions_pdcsv.csv'
answers_csv = 'train_answers_pdcsv.csv'contexts = load_data(contexts_csv)
questions = load_data(questions_csv)
solutions = load_data(answers_csv)
c_train, c_val, q_train, q_val, a_train, a_val = train_test_split(contexts,
questions, solutions,
test_size=0.2,
random_state=42)
Making ready information
Like I discussed earlier than, it’s potential to coach an extractive mannequin and an abstractive mannequin. Throughout my analysis I developed each an extractive and an abstractive mannequin. On this article I simply cowl the abstractive model however, for anybody , I will even clarify how I preprocessed my information for the extractive mannequin. This was essential to create the start- and endindices of the solutions in contexts.
Abstractive
The dataset doesn’t want a lot preprocessing to be able to practice an abstractive mannequin. We merely convert all practice information to utf-8. The final three strains may be uncommented to lower the scale of the trainset, this may enhance coaching time and may assist with debugging.
def clean_data(contexts, questions, solutions):
cleaned_contexts, cleaned_questions, cleaned_answers = [], [], []
for i in vary(len(solutions)):
cleaned_contexts.append(to_utf8(contexts[i]))
cleaned_questions.append(to_utf8(questions[i]))
cleaned_answers.append(to_utf8(solutions[i]))
return cleaned_contexts, cleaned_questions, cleaned_answerscc_train, cq_train, ca_train = clean_data(c_train, q_train, a_train);
cc_val, cq_val, ca_val = clean_data(c_val, q_val, a_val);
print("Unique information dimension: " + str(len(q_train)))
print("Filtered information dimension: " + str(len(cq_train)))
#cc_train = cc_train[0:1000]
#cq_train = cq_train[0:1000]
#ca_train = ca_train[0:1000]
Extractive
In lots of circumstances, extractive fashions want begin and finish indices of the reply within the context. Nonetheless, since we translated our dataset utilizing a Transformer a couple of points can happen. For instance, solutions is perhaps worded otherwise than within the context or the place or size of the reply might need modified. To resolve this, we will attempt to discover the reply within the context and, if the reply is discovered, add it to the cleaned solutions. Due to this, we even have details about the beginning index and the tip index is solely the beginning index plus the size of the reply.
def clean_data(contexts, questions, solutions):
cleaned_contexts, cleaned_questions, cleaned_answers = [], [], []
for i in vary(len(solutions)):
index = contexts[i].discover(solutions[i])
if(index != -1):
#print(str(index) + " + " + str(index+len(solutions[i])))
cleaned_contexts.append(contexts[i])
cleaned_questions.append(questions[i])
cleaned_answers.append({
'textual content':solutions[i],
'answer_start': index,
'answer_end': index+len(solutions[i])
})
return cleaned_contexts, cleaned_questions, cleaned_answerscc_train, cq_train, ca_train = clean_data(c_train, q_train, a_train);
cc_val, cq_val, ca_val = clean_data(c_val, q_val, a_val);
Tokenizer
The subsequent step is tokenizing, since we’re utilizing t5-v1_1-base, we will merely import the tokenizer from Huggingface. Then we are going to tokenize the contexts with the questions in order that the tokenizer will add them along with finish of string tokens. We additionally specify the beforehand outlined max_text_length. Lastly the tokenized solutions are added to the encodings because the goal.
tokenizer = T5Tokenizer.from_pretrained('google/t5-v1_1-base')
train_encodings = tokenizer(cc_train, cq_train, max_length=max_text_length, truncation=True, padding=True)
val_encodings = tokenizer(cc_val, cq_val, max_length=max_text_length, truncation=True, padding=True)def add_token_positions(encodings, solutions):
tokenized = tokenizer(solutions, truncation=True, padding=True)
encodings.replace({'target_ids': tokenized['input_ids'], 'target_attention_mask': tokenized['attention_mask']})
add_token_positions(train_encodings, ca_train)
add_token_positions(val_encodings, ca_val)
Dataloader
We’ll use a Dataloader to coach the PyTorch mannequin as follows. In right here the batch dimension may also be specified. The server I educated on had restricted reminiscence so I had to make use of a batch dimension of two. If potential, a much bigger batch dimension could be preferable.
class SquadDataset(torch.utils.information.Dataset):
def __init__(self, encodings):
self.encodings = encodings
print(encodings.keys())def __getitem__(self, idx):
return {key: torch.tensor(val[idx]) for key, val in self.encodings.objects()}
def __len__(self):
return len(self.encodings.input_ids)
train_dataset = SquadDataset(train_encodings)
val_dataset = SquadDataset(val_encodings)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
The mannequin we use is T5ForConditionalGeneration based mostly on T5-v1_1-base. If CUDA is put in on the PC or server that’s used for coaching, we will attempt to put it to use to considerably improve coaching pace. We additionally inform the mannequin that we’re going to practice it.
The optimizer we use is AdamW with a studying charge of 1e-4. That is based mostly on the T5 documentation [18] which mentions that it’s a good worth to make use of in our state of affairs:
Usually, 1e-4 and 3e-4 work properly for many issues (classification, summarization, translation, query answering, query technology).
Lastly we outline a perform that saves our mannequin for later utilization after it’s executed coaching.
mannequin = T5ForConditionalGeneration.from_pretrained('google/t5-v1_1-base')
cuda = torch.cuda.is_available()
machine = torch.machine('cuda') if cuda else torch.machine('cpu')
mannequin.to(machine)
mannequin.practice()optimizer = AdamW(mannequin.parameters(), lr=1e-4)
def save_model():
now = datetime.now()
date_time = now.strftime(" %m %d %Y %H %M %S")
torch.save(mannequin.state_dict(), "answer_gen_models/nlpModel"+date_time+".pt")
The precise coaching of the mannequin will likely be executed in three epochs, the Pocket book I’ve used [17] and the T5 documentation each state that it is a good quantity of epochs to coach on. On my PC which has a RTX 3090 this might take about 24 hours per epoch. The server I’ve used took benefit of an Nvidia Tesla T4 and took about 6 hours per epoch.
The Tqdm module is used for visible suggestions on the coaching state. It gives us with information concerning the elapsed time and the estimated time coaching will take. The steps between the 2 commented arrows are essential for our objective of query answering, that is the place we outline what enter to present the mannequin. The opposite steps taken on this code block are fairly simple for the coaching of a PyTorch mannequin.
for epoch in vary(3):
loop = tqdm(train_loader, depart=True)
for batch in loop:
optim.zero_grad()# >
input_ids = batch['input_ids'].to(machine)
attention_mask = batch['attention_mask'].to(machine)
target_ids = batch['target_ids'].to(machine)
target_attention_mask = batch['target_attention_mask'].to(machine)
outputs = mannequin(input_ids, attention_mask=attention_mask,
labels=target_ids,
decoder_attention_mask=target_attention_mask)
# >
loss = outputs[0]
loss.backward()
optimizer.step()
loop.set_description(f'Epoch {epoch}')
loop.set_postfix(loss=loss.merchandise())
save_model()
Outcomes
In case you have adopted alongside, congratulations! You may have created your personal Dutch dataset and educated a Dutch query answering mannequin! In case you are like me, you in all probability can’t wait to attempt the mannequin to see what outcomes it provides. You should utilize the next code to judge the mannequin. Curiously sufficient, you may discover that the mannequin shouldn’t be solely able to answering Dutch questions! It is usually considerably able to answering questions in numerous (largely Germanic) languages. That is more than likely as a result of the truth that the unique T5-v1_1-base mannequin has been educated on 4 completely different languages.
mannequin = T5ForConditionalGeneration.from_pretrained('google/t5-v1_1-base')
mannequin.load_state_dict(torch.load("answer_gen_models/some_model.pt"))cuda = torch.cuda.is_available()
machine = torch.machine('cuda') if cuda else torch.machine('cpu')
mannequin.to(machine)
mannequin.eval()
def check(context, query):
enter = tokenizer([to_utf8(context)],
[to_utf8(question)],
max_length=max_text_length,
truncation=True,
padding=True)
with torch.no_grad():
input_ids = torch.tensor(enter['input_ids']).to(machine)
attention_mask = torch.tensor(enter['attention_mask']).to(machine)
out = mannequin.generate(input_ids,
attention_mask=attention_mask,
max_length=max_output_length,
early_stopping=True)
print([tokenizer.decode(ids,
skip_special_tokens=True) for ids in out][0])
check("Dit is een voorbeeld", "Wat is dit?")
Listed below are some instance contexts and questions along with the solutions which were generated by the mannequin:
Context We zijn met de klas van de grasp Utilized Synthetic Intelligence naar keulen geweest.
Query Waar is de klas heen geweest?
Reply Keulen
Context De grote bruine vos springt over de luie hond heen.
Query Waar springt de vos overheen?
Reply Luie hond
Context The large brown fox jumps over the lazy canine.
Query What does the fox do?
Reply Jumps over the lazy canine
Context Twee maal twee is tien.
Query Wat is twee maal twee?
Reply Tien
So, to summarize, we’ve chosen an English dataset for query answering, translated it to Dutch utilizing the Google Translate API and we’ve educated a PyTorch encoder-decoder mannequin based mostly on T5-v1_1-base. What precisely have we achieved with this and might this be utilized in real-life conditions?
To start with, you will need to understand that we’ve not correctly evaluated the mannequin as that was not a part of the scope of this text. Nonetheless, to have the ability to correctly interpret our outcomes and to have the ability to say one thing about its usability, I recommend trying into metrics like Rouge [19] or a human analysis. The method I’ve taken is a human analysis. Desk 2 exhibits the common score between one and 5 that 5 folks have given the generated solutions of assorted context sources and questions. The typical rating is 2.96. This quantity alone doesn’t inform us a lot however we will conclude from the desk that the mannequin we created can in some circumstances generate close to good solutions. Nonetheless, it does additionally very often generate solutions that the panel of human evaluators contemplate to be full nonsense.

It is usually essential to notice that, by translating a dataset, we’ve more than likely launched a bias. The AI behind Google Translate has been educated on a dataset which, since it’s based mostly on pure language, naturally comprises a bias. By translating our information with it, this bias will likely be handed on to any mannequin that’s educated with the dataset. Earlier than a dataset created like this can be utilized in a real-life state of affairs, it ought to be evaluated totally to point what biases there are and the way they affect the outcomes.
Nonetheless, this answer may be very fascinating to people who find themselves experimenting with AI, growing a brand new sort of machine studying mannequin or are merely studying about NLP. It’s a very accessible solution to get an enormous dataset in any language for nearly any NLP downside. Many college students shouldn’t have entry to massive datasets as a result of they’re solely accessible to massive corporations or are too costly. With an method like this, any massive English dataset may be reworked right into a dataset in a selected language.
Personally I’m excited about seeing the place I can take this method. I’m at present engaged on a query technology mannequin that’s utilizing precisely the identical method and dataset. I wish to examine the utilization of those two fashions mixed so I can be taught extra about potential biases or errors which were launched. That is in keeping with chapter 5 during which I talked concerning the want for analysis. I’ve created a human analysis by asking 5 folks to charge the outcomes of the created mannequin. Nonetheless, I intend to be taught extra about completely different metrics which may hopefully inform me extra about how the mannequin works, why it generates sure outcomes and what biases it comprises.
I’ve additionally realized that model 2.0 of the Stanford Query and Reply dataset contains questions that can’t be answered. Despite the fact that it isn’t straight associated to the answer provided on this article, I’m curious concerning the variations in outcomes after I apply the answer of this text to the complete SQuAD 2.0 dataset.
[1] A. Vaswani et al., “Consideration Is All You Want,” 2017.
[2] D. Khurana, A. Koli, Ok. Khatter, and S. Singh, “Pure language processing: cutting-edge, present developments and challenges,” Multimedia Instruments and Functions, Jul. 2022, doi: 10.1007/s11042–022–13428–4.
[3] “What’s Pure Language Processing? | IBM,” www.ibm.com. https://www.ibm.com/topics/natural-language-processing (accessed Jan. 11, 2023).
[4] E. Holloway, “Sure, ChatGPT Is Sentient — As a result of It’s Actually People within the Loop,” Thoughts Issues, Dec. 26, 2022. https://mindmatters.ai/2022/12/yes-chatgpt-is-sentient-because-its-really-humans-in-the-loop/ (accessed Jan. 18, 2023).
[5] “NLP — overview,” cs.stanford.edu. https://cs.stanford.edu/people/eroberts/courses/soco/projects/2004-05/nlp/overview_history.html (accessed Jan. 18, 2023).
[6] S. Ruder, “A Assessment of the Latest Historical past of Pure Language Processing,” Sebastian Ruder, Oct. 01, 2018. https://ruder.io/a-review-of-the-recent-history-of-nlp/ (accessed Jan. 18, 2023).
[7] S. Varanasi, S. Amin, and G. Neumann, “AutoEQA: Auto-Encoding Questions for Extractive Query Answering,” Findings of the Affiliation for Computational Linguistics: EMNLP 2021, 2021.
[8] “What’s Query Answering? — Hugging Face,” huggingface.co. https://huggingface.co/tasks/question-answering (accessed Jan. 18, 2023).
[9] R. E. López Condori and T. A. Salgueiro Pardo, “Opinion summarization strategies: Evaluating and lengthening extractive and abstractive approaches,” Knowledgeable Methods with Functions, vol. 78, pp. 124–134, Jul. 2017, doi: 10.1016/j.eswa.2017.02.006.
[10] B. B. Cambazoglu, M. Sanderson, F. Scholer, and B. Croft, “A evaluate of public datasets in query answering analysis,” ACM SIGIR Discussion board, vol. 54, no. 2, pp. 1–23, Dec. 2020, doi: 10.1145/3483382.3483389.
[11] “Hugging Face — The AI group constructing the long run.,” huggingface.co. https://huggingface.co/datasets?language=language:nl&task_categories=task_categories:question-answering&sort=downloads (accessed Jan. 18, 2023).
[12] “The Stanford Query Answering Dataset,” rajpurkar.github.io. https://rajpurkar.github.io/SQuAD-explorer/ (accessed Jan. 18, 2023).
[13] “Papers with Code — Query Answering,” paperswithcode.com. https://paperswithcode.com/task/question-answering (accessed Jan. 18, 2023).
[14] P. Azunre, Switch Studying for Pure Language Processing. Simon and Schuster, 2021.
[15] “Hugging Face — On a mission to unravel NLP, one commit at a time.,” huggingface.co. https://huggingface.co/models (accessed Jan. 18, 2023).
[16] Z. Keita, “Knowledge Augmentation in NLP Utilizing Again Translation With MarianMT,” Medium, Nov. 05, 2022. https://towardsdatascience.com/data-augmentation-in-nlp-using-back-translation-with-marianmt-a8939dfea50a (accessed Jan. 18, 2023).
[17] P. Suraj, “Google Colaboratory,” colab.analysis.google.com. https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb (accessed Jan. 25, 2023).
[18] “T5,” huggingface.co. https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5Model (accessed Jan. 25, 2023).
[19] “ROUGE — a Hugging Face Area by evaluate-metric,” huggingface.co. https://huggingface.co/spaces/evaluate-metric/rouge (accessed Jan. 25, 2023).
All photos except in any other case famous are by the writer.
[ad_2]
Source link
