

[ad_1]
We’ve got beforehand had an extended take a look at a number of introductory natural language processing (NLP) topics, from approaching such duties, to preprocessing textual content information, to getting began with a pair of in style Python libraries, and past. I hoped to maneuver on to exploring some various kinds of NLP duties, however had it identified to me that I had uncared for to the touch on a vastly necessary facet: information illustration for pure language processing.
Simply as in different kinds of machine studying duties, in NLP we should discover a strategy to characterize our information (a collection of texts) to our methods (e.g. a textual content classifier). As Yoav Goldberg asks, “How can we encode such categorical information in a manner which is amenable for us by a statistical classifier?” Enter the phrase vector.
Supply: Yandex Data School Natural Language Processing Course
First, past “turning phrases right into a numeric illustration,” what are we involved in doing whereas we carry out this information encoding? Extra exactly, what’s it that we’re encoding?
We should go from a set of categorical options in uncooked (or preprocessed) textual content — phrases, letters, POS tags, phrase association, phrase order, and so forth. — to a collection of vectors. Two choices for reaching this encoding of textual information are sparse vectors (or one-hot encodings) and dense vectors.
These 2 approaches differ in just a few basic methods. Learn on for a dialogue.
Previous to the wide-spread use of neural networks in NLP — in what we are going to seek advice from as “conventional” NLP — vectorization of textual content usually occurred by way of one-hot encoding (notice that this persists as a helpful encoding observe for numerous workouts, and has not fallen out of style because of using neural networks). For one-hot encoding, every phrase, or token, in a textual content corresponds to a vector aspect.
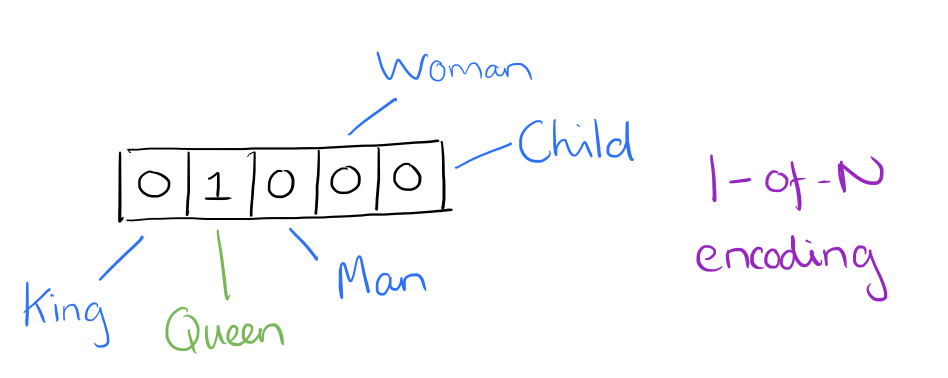
Supply: Adrian Colyer
We might contemplate the picture above, for instance, as a small excerpt of a vector representing the sentence “The queen entered the room.” Be aware that solely the aspect for “queen” has been activated, whereas these for “king,” “man,” and so forth. haven’t. You may think about how otherwise the one-hot vector illustration of the sentence “The king was as soon as a person, however is now a toddler” would seem in the identical vector aspect part pictured above.
The results of a one-hot encoding course of on a corpus is a sparse matrix. Think about if you happen to had a corpus with 20,000 distinctive phrases: a single quick doc in that corpus of, maybe, 40 phrases could be represented by a matrix with 20,000 rows (one for every distinctive phrase) with a most of 40 non-zero matrix components (and doubtlessly far-fewer if there are a excessive variety of non-unique phrases on this assortment of 40 phrases). This leaves loads of zeroes, and might find yourself taking a considerable amount of reminiscence to deal with these spare representations.
Past potential reminiscence capability points, a significant downside of one-hot encoding is the shortage of which means illustration. Whereas we seize the presence and absence of phrases in a specific textual content properly with this strategy, we will not simply decide any which means from easy presence/absence of those phrases. A part of this drawback is that we lose positional relationships between phrases, or phrase order, utilizing one-hot encoding. This order find yourself being paramount in representing which means in phrases, and is addressed under.
The idea of phrase similarity is troublesome to extract as properly, since phrase vectors are statistically orthogonal. Take, for instance, the phrase pairs “canine” and “canine,” or “automotive” and “auto.” Clearly these phrase pair are related in several methods, respectively. In a linear system, utilizing one-hot encoding, conventional NLP instruments equivalent to stemming and lemmatization can be utilized in preprocessing to assist expose the similarity between the primary phrase pair; nevertheless, we’d like a extra strong strategy to sort out uncovering similarity between the second phrase pair.
The foremost advantage of one-hot encoded phrase vectors is that it captures binary phrase co-occurrence (it’s alternately described as a bag of phrases), which is sufficient to carry out a variety of NLP duties together with textual content classification, one of many area’s most helpful and widespread pursuits. The sort of phrase vector is helpful for linear machine studying algorithms in addition to neural networks, although they’re mostly related to linear methods. Variants on one-hot encoding that are additionally helpful to linear methods, and which assist fight among the above points, are n-gram and TF-IDF representations. Although they aren’t the identical as one-hot encoding, they’re related in that they’re easy vector representations versus embeddings, that are launched under.
Sparse phrase vectors appear to be a wonderfully acceptable manner of representing sure textual content information specifically methods, particularly contemplating binary phrase co-occurrence. We will additionally use associated linear approaches to sort out among the best and most blatant drawbacks of one-hot encodings, equivalent to n-grams and TF-IDF. However getting tho the guts of the which means of textual content, and the semantic relationship between tokens, stays troublesome with out taking a special strategy, and phrase embedding vectors are simply such an strategy.
In “conventional” NLP, approaches equivalent to handbook or discovered part-of-speech (POS) tagging can be utilized to find out which tokens in a textual content carry out which kinds of perform (noun, verb, adverb, indefinite article, and so forth.). It is a type of handbook function task, and these options can then be used for a wide range of approaches to NLP capabilities. Think about, for instance, named entity recognition: if we’re searching for named entities inside a passage of textual content, it will be cheap to first take a look at solely nouns (or noun phrases) in an try at identification, as named entities are nearly solely a subset of all nouns.
Nevertheless, let’s contemplate if we as an alternative represented options as dense vectors — that’s, with core options embedded into an embedding house of dimension d dimensions. We will compress, if you’ll, the variety of dimensions used to characterize 20,000 distinctive phrases right down to, maybe, 50 or 100 dimensions. On this strategy, every function now not has its personal dimension, and is as an alternative mapped to a vector.
As acknowledged earlier, it seems that which means is said to not binary phrase co-occurrence, however to phrase positional relationships. Consider it this manner: if I say that the phrases “foo” and “bar” happen collectively in a sentence, figuring out which means is troublesome. Nevertheless; if I say “The foo barked, which startled the younger bar,” it turns into a lot simpler to find out meanings of those phrases. The place of the phrases and their relationship to phrases round them are necessary.
“You shall know a phrase by the corporate it retains.”
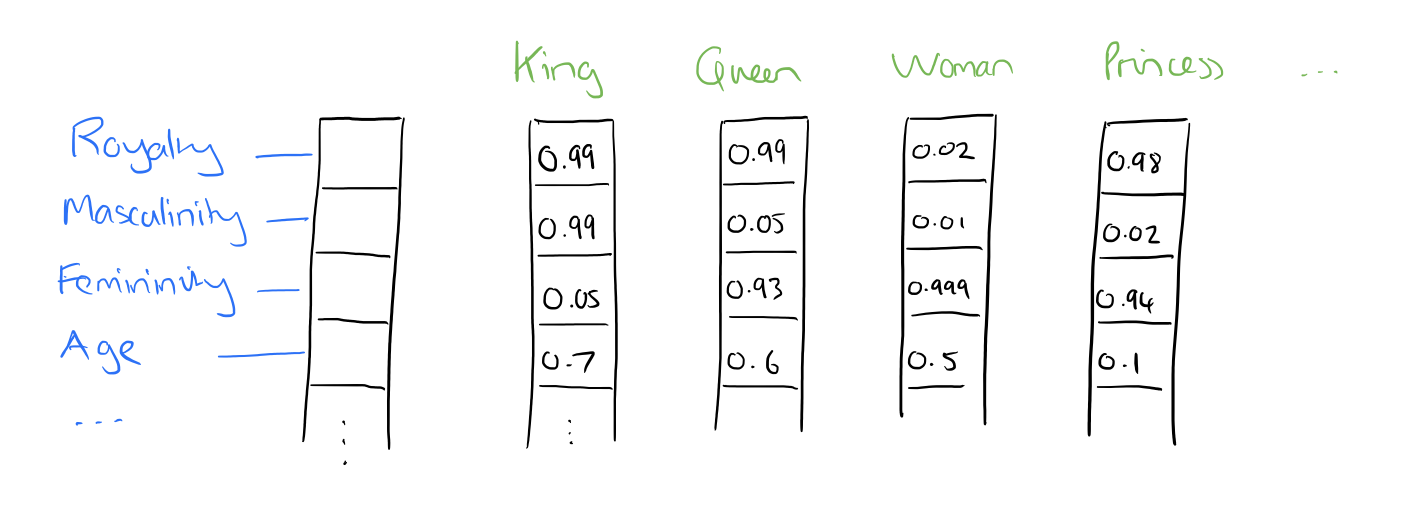
Supply: Adrian Colyer
So, what precisely are these options? We go away it to a neural community to find out the necessary facets of relationships between phrases. Although human interpretation of those options wouldn’t be exactly potential, the picture above gives an perception into what the underlying course of could appear like, regarding the well-known King – Man + Lady = Queen example.
How are these options discovered? That is achieved by utilizing a 2-layer (shallow) neural community — phrase embeddings are sometimes grouped along with “deep studying” approaches to NLP, however the course of of making these embeddings doesn’t use deep studying, although the discovered weights are sometimes utilized in deep studying duties afterwords. The favored authentic word2vec embedding strategies Steady Bag of Phrases (CBOW) and Skip-gram relate to the duties of predicting a phrase given its context, and predicting the context given a phrase (notice that context is a sliding window of phrases within the textual content). We do not care concerning the output layer of the mannequin; it’s discarded after coaching, and the weights of the embedding layer are then used for subsequent NLP neural community duties. It’s this embedding layers which is analogous to the ensuing phrase vectors within the one-hot encoding strategy.
There you’ve the two main approaches to representing textual content information for NLP duties. We are actually prepared to take a look at some sensible NLP duties subsequent time round.
References
- Natural Language Processing, Nationwide Analysis College Increased College of Economics (Coursera)
- Natural Language Processing, Yandex Knowledge College
- Neural Network Methods for Natural Language Processing, Yoav Goldberg
Matthew Mayo (@mattmayo13) is a Knowledge Scientist and the Editor-in-Chief of KDnuggets, the seminal on-line Knowledge Science and Machine Studying useful resource. His pursuits lie in pure language processing, algorithm design and optimization, unsupervised studying, neural networks, and automatic approaches to machine studying. Matthew holds a Grasp’s diploma in laptop science and a graduate diploma in information mining. He may be reached at editor1 at kdnuggets[dot]com.
[ad_2]
Source link
