


[ad_1]
It is extremely vital to know the way LIME reaches to its closing outputs for explaining a prediction achieved for textual content information. On this article, I’ve shared that idea by enlightening the elements of LIME.

Picture by Ethan Medrano on Unsplash
Few weeks again I wrote a blog on how totally different interpretability instruments can be utilized to interpret sure predictions achieved by the black-box fashions. In that article I shared the arithmetic behind LIME, SHAP and different interpretability instruments, however I didn’t go a lot into particulars of implementing these ideas on unique information. On this article, I considered sharing how LIME works on textual content information in a step-by-step method.
The information that’s used for the entire evaluation is taken from here . This information is for predicting whether or not a given tweet is about an actual catastrophe(1) or not(0). It has the next columns:

Source
As the principle focus of this weblog is to interpret LIME and its totally different elements so we are going to rapidly construct a binary textual content classification mannequin utilizing Random Forest and can focus primarily on LIME interpretation.
First, we begin with importing the mandatory packages. Then we learn the information and begin preprocessing like cease phrases removing, Lowercase, lemmatization, punctuation removing, whitespace removing and so forth. All of the cleaned preprocessed textual content are saved in a brand new ‘cleaned_text’ column which will likely be additional used for evaluation and the information is cut up into practice and validation set in a ratio of 80:20.
Then we rapidly transfer to changing the textual content information into vectors utilizing TF-IDF vectoriser and becoming a Random Forest classification mannequin on that.

Picture by writer
Now let’s start the principle curiosity of this weblog which is learn how to interpret totally different elements of LIME.
First let’s see what’s the closing output of the LIME interpretation for a selected information occasion. Then we are going to go deep dive into the totally different elements of LIME in a step-by-step method which can lastly end result the specified output.

Picture by writer
Right here labels=(1,) is handed as an argument which means we would like the reason for the category 1. The options (phrases on this case) highlighted with orange are the highest options that trigger a prediction of sophistication 0 (not catastrophe) with likelihood 0.75 and sophistication 1(catastrophe) with likelihood 0.25.
NOTE: char_level is without doubt one of the arguments for LimeTextExplainer which is a boolean figuring out that we deal with every character as an unbiased prevalence within the string. Default is False so we don’t think about every character independently and IndexedString operate is used for tokenization and indexing the phrases within the textual content occasion, in any other case IndexedCharacters operate is used.
So, you have to be to know the way these are calculated. Proper?
Let’s see that.
LIME begins with creating some perturbed samples across the neighbourhood of information focal point. For textual content information, perturbed samples are created by randomly eradicating among the phrases from the occasion and cosine distance is used to calculate the space between the unique and perturbed samples as default metric.
This returns the array of 5000 perturbed samples(every perturbed pattern is of size of the unique occasion and 1 means the phrase in that place of the unique occasion is current within the perturbed pattern), their corresponding prediction chances and the cosine distances between the unique and perturbed samples.A snippet of that’s as follows:

Picture by writer
Now after creating the perturbed samples within the neighbourhood it’s time to provide weights to these samples. Samples which might be close to from the unique occasion are given greater weightage than the samples removed from the unique occasion. Exponential kernel with kernel width 25 is used as default to provide these weightage.
After that vital options(as per num_features: max variety of options to be defined) are chosen by studying a domestically linear sparse mannequin from perturbed information. There are a number of strategies for selecting the vital options utilizing the native linear sparse mannequin like ‘auto’(default), ‘forward_selection’, ‘lasso_path’, ‘highest_weights’. If we select ‘auto’ then ‘forward_selection’ is used if num_features≤6, else ‘highest_weights’ is used.

Picture by writer
Right here we will see that the options chosen are [1,5,0,2,3] that are the indices of the vital phrases(or options) within the unique occasion. As right here num_features=5 and methodology=‘auto’, ‘forward_selection’ methodology is used for choosing the vital options.
Now let’s see what’s going to occur if we select methodology as ‘lasso_path’.

Picture by writer
Identical. Proper?
However you could be to go deep dive into this means of choice. Don’t fear, I’ll make that simple.
It makes use of the idea of Least angle regression for choosing the highest options.
Let’s see what’s going to occur if we choose methodology as ‘highest_weights’.

Picture by writer
Hold on. We’re going deeper within the choice course of.
So now the vital options we’ve chosen by utilizing any one of many strategies. However lastly we must match a neighborhood linear mannequin to clarify the prediction achieved by the black-box mannequin. For that Ridge Regression is used as default.
Let’s test how the outputs will seem like lastly.
If we choose methodology as auto, highest_weights and lasso_path respectively the output will seem like this:
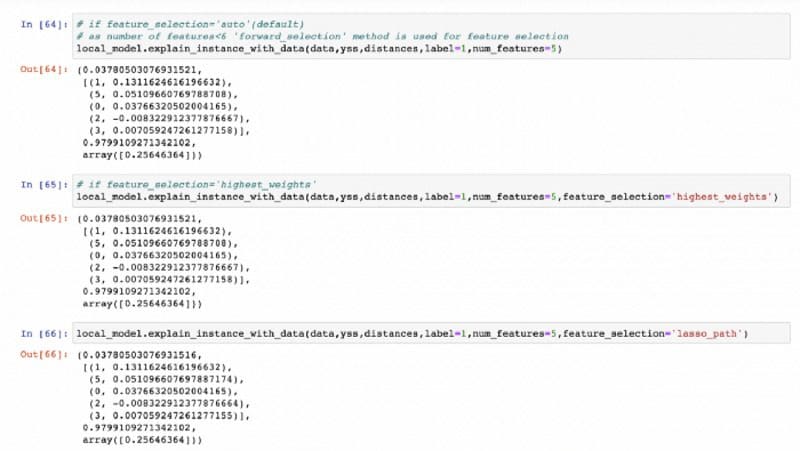
Picture by writer
These return a tuple (intercept of the native linear mannequin, vital options indices and its coefficients, R² worth of the native linear mannequin, native prediction by the reason mannequin on the unique occasion).
If we examine the above picture with

Picture by writer
then we will say that the prediction chances given within the left most panel is the native prediction achieved by the reason mannequin. The options and the values given within the center panel are the vital options and their coefficients.
NOTE: As for this explicit information occasion the variety of phrases(or options) is simply 6 and we’re deciding on the highest 5 vital options , all of the strategies are giving the identical set of high 5 vital options. However it might not occur for longer sentences.
In the event you like this text please hit suggest. That may be superb.
To get the complete code please go to my GitHub repository. For my future blogs please comply with me on LinkedIn and Medium.
Conclusion
On this article, I attempted to clarify the ultimate consequence of LIME for textual content information and the way the entire clarification course of occurs for textual content in a step-by-step method. Related explanations will be achieved for tabular and picture information. For that I’ll extremely suggest to undergo this.
References
- GitHub repository for LIME : https://github.com/marcotcr/lime
- Documentation on LARS: http://www.cse.iitm.ac.in/~vplab/courses/SLT/PDF/LAR_hastie_2018.pdf
- https://towardsdatascience.com/python-libraries-for-interpretable-machine-learning-c476a08ed2c7
Ayan Kundu is a knowledge scientist with 2+ years of expertise within the subject of banking and finance and likewise a passionate learner to assist the group as a lot as attainable. Observe Ayan on LinkedIn and Medium.
[ad_2]
Source link
