

[ad_1]
A hands-on instance of methods to apply geospatial index
Geospatial Indexing is an indexing method that gives a sublime solution to handle location-based information. It makes geospatial information may be searched and retrieved effectively in order that the system can present the most effective expertise to its customers. This text goes to reveal how this works in follow by making use of a geospatial index to real-world information and demonstrating the efficiency acquire by doing that. Let’s get began. (Notice: You probably have by no means heard of the geospatial index or wish to study extra about it, take a look at this article)
The information used on this article is the Chicago Crime Data which is part of the Google Cloud Public Dataset Program. Anybody with a Google Cloud Platform account can entry this dataset without cost. It consists of roughly 8 million rows of information (with a complete quantity of 1.52 GB) recording incidents of crime that occurred in Chicago since 2001, the place every document has geographic information indicating the incident’s location.
Not solely that we’ll use the info from Google Cloud, but additionally we’ll use Google Large Question as an information processing platform. Large Question supplies the job execution particulars for each question executed. This contains the quantity of information used and the variety of rows processed which shall be very helpful as an instance the efficiency acquire after optimization.
What we’re going to do to reveal the facility of the geospatial index is to optimize the efficiency of the location-based question. On this instance, we’re going to make use of Geohash as an index due to its simplicity and native help by Google BigQuery.
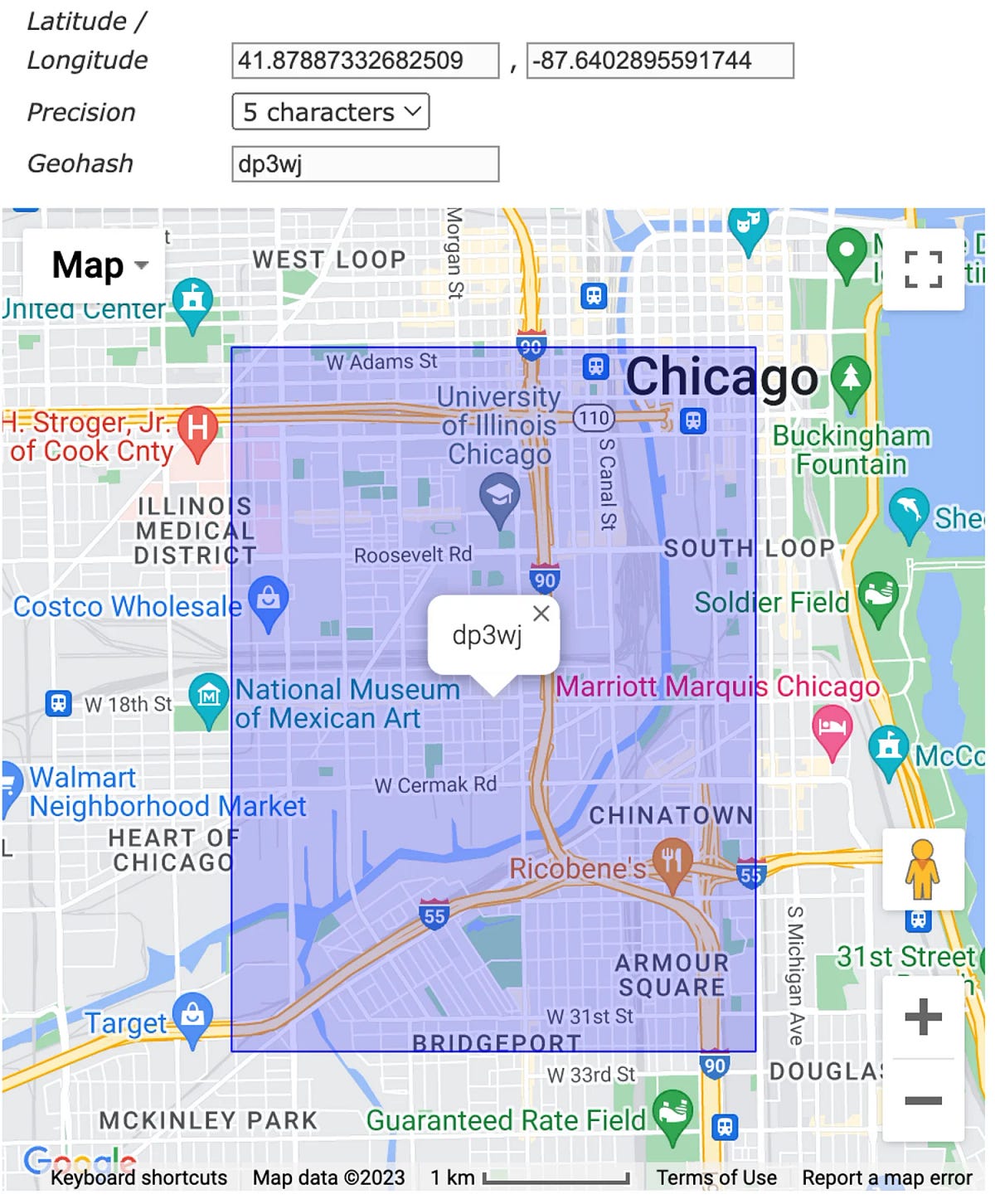
We’re going to retrieve all data of crimes that occurred inside 2 km of the Chicago Union Station. Earlier than the optimization, let’s see what the efficiency seems like once we run this question on the unique dataset:
-- Chicago Union Station Coordinates = (-87.6402895591744 41.87887332682509)
SELECT
*
FROM
`bigquery-public-data.chicago_crime.crime`
WHERE
ST_DISTANCE(ST_GEOGPOINT(longitude, latitude), ST_GEOGFROMTEXT("POINT(-87.6402895591744 41.87887332682509)")) <= 2000
Under is what the job info and execution particulars appear like:


From the variety of Bytes processed and Information learn, you’ll be able to see that the question scans the entire desk and processes each row with a purpose to get the ultimate end result. This implies the extra information we now have, the longer the question will take, and the dearer the processing value shall be. Can this be extra environment friendly? After all, and that’s the place the geospatial index comes into play.
The issue with the above question is that though many data are distant from the point-of-interest(Chicago Union Station), it needs to be processed anyway. If we will get rid of these data, that will make the question much more environment friendly.
Geohash may be the answer to this difficulty. Along with encoding coordinates right into a textual content, one other energy of geohash is the hash additionally comprises geospatial properties. The similarity between hashes can infer geographical similarity between the areas they signify. For instance, the 2 areas represented by wxcgh and wxcgd are shut as a result of the 2 hashes are very comparable, whereas accgh and dydgh are distant from one another as a result of the 2 hashes are very totally different.
We will use this property with the clustered table to our benefit by calculating the geohash of each row upfront. Then, we calculate the geohash of the Chicago Union Station. This manner, we will get rid of all data that the hashes aren’t shut sufficient to the Chicago Union Station’s geohash beforehand.
Right here is methods to implement it:
- Create a brand new desk with a brand new column that shops a geohash of the coordinates.
CREATE TABLE `<project_id>.<dataset>.crime_with_geohash_lv5` AS (
SELECT *, ST_GEOHASH(ST_GEOGPOINT(longitude, latitude), 5) as geohash
FROM `bigquery-public-data.chicago_crime.crime`
)
2. Create a clustered desk utilizing a geohash column as a cluster key
CREATE TABLE `<project_id>.<dataset>.crime_with_geohash_lv5_clustered`
CLUSTER BY geohash
AS (
SELECT *
FROM `<project_id>.<dataset>.crime_with_geohash_lv5`
)
By utilizing geohash as a cluster key, we create a desk during which the rows that share the identical hash are bodily saved collectively. If you concentrate on it, what truly occurs is that the dataset is partitioned by geolocation as a result of the nearer the rows geographically are, the extra probably they may have the identical hash.
3. Compute the geohash of the Chicago Union Station.
On this article, we use this website however there are many libraries in varied programming languages that mean you can do that programmatically.

4. Add the geohash to the question situation.
SELECT
*
FROM
`<project_id>.<dataset>.crime_with_geohash_lv5_clustered`
WHERE
geohash = "dp3wj" AND
ST_DISTANCE(ST_GEOGPOINT(longitude, latitude), ST_GEOGFROMTEXT("POINT(-87.6402895591744 41.87887332682509)")) <= 2000
This time the question ought to solely scan the data situated within the dp3wj because the geohash is a cluster key of the desk. This supposes to avoid wasting numerous processing. Let’s have a look at what occurs.


From the job data and execution particulars, you’ll be able to see the variety of bytes processed and data scanned diminished considerably(from 1.5 GB to 55 MB and 7M to 260k). By introducing a geohash column and utilizing it as a cluster key, we get rid of all of the data that clearly don’t fulfill the question beforehand simply by one column.
Nevertheless, we aren’t completed but. Have a look at the variety of output rows rigorously, you’ll see that it solely has 100k data the place the right end result will need to have 380k. The end result we bought remains to be not appropriate.
5. Compute the neighbor zones and add them to the question.
On this instance, all of the neighbor hashes are dp3wk, dp3wm, dp3wq, dp3wh, dp3wn, dp3wu, dp3wv, and dp3wy . We use on-line geohash explore for this however, once more, this may completely be written as a code.

Why do we have to add the neighbor zones to the question? As a result of geohash is simply an approximation of location. Though we all know Chicago Union Station is within the dp3wj , we nonetheless do not know the place precisely it’s within the zone. On the prime, backside, left, or proper? We don’t know. If it is on the prime, it is doable some information within the dp3wm could also be nearer to it than 2km. If it is on the precise, it is doable some information within the dp3wn zone could nearer than 2km. And so forth. That is why all of the neighbor hashes should be included within the question to get the right end result.
Notice that geohash stage 5 has a precision of 5km. Subsequently, all zones apart from these within the above determine shall be too removed from the Chicago Union Station. That is one other essential design alternative that needs to be made as a result of it has a big impact. We’ll acquire little or no if it’s too coarse. However, utilizing too high quality precision-level will make the question refined.
Right here’s what the ultimate question seems like:
SELECT
*
FROM
`<project_id>.<dataset>.crime_with_geohash_lv5_clustered`
WHERE
(
geohash = "dp3wk" OR
geohash = "dp3wm" OR
geohash = "dp3wq" OR
geohash = "dp3wh" OR
geohash = "dp3wj" OR
geohash = "dp3wn" OR
geohash = "dp3tu" OR
geohash = "dp3tv" OR
geohash = "dp3ty"
) AND
ST_DISTANCE(ST_GEOGPOINT(longitude, latitude), ST_GEOGFROMTEXT("POINT(-87.6402895591744 41.87887332682509)")) <= 2000
And that is what occurs when executing the question:


Now the result’s appropriate and the question processes 527 MB and scans 2.5M data in complete. Compared with the unique question, utilizing geohash and clustered desk saves the processing useful resource round 3 instances. Nevertheless, nothing comes without cost. Making use of geohash provides complexity to the way in which information is preprocessed and retrieved comparable to the selection of precision stage that needs to be chosen upfront and the extra logic of the SQL question.
On this article, we’ve seen how the geospatial index may help enhance the processing of geospatial information. Nevertheless, it has a value that must be nicely thought-about upfront. On the finish of the day, it’s not a free lunch. To make it work correctly, an excellent understanding of each the algorithm and the system necessities is required.
[ad_2]
Source link
