

[ad_1]
Latest technological breakthroughs have considerably expanded the variety of methods wherein synthetic intelligence and machine studying will be built-in into our lives. A widely known instance is the widespread use of digital assistants like Amazon Alexa, Google Assistant, and Samsung Bixby in each day life. These digital brokers are extraordinarily useful in performing even the smallest duties, corresponding to setting a reminder for somebody’s birthday, to extra advanced duties, like helping folks with disabilities in navigating their houses and different environment. Nonetheless, although digital assistants are virtually in all places now, a variety of arduous work and analysis goes into growing them behind the scenes. This class of coaching digital assistants to make use of pure language and parse it utilizing a mannequin to grasp the consumer intent and attain the duty at hand typically comes underneath the task-oriented dialogue parsing job. Understanding what the consumer needs and the data the mannequin wants to finish that job with superb accuracy, nonetheless, is a difficult job.
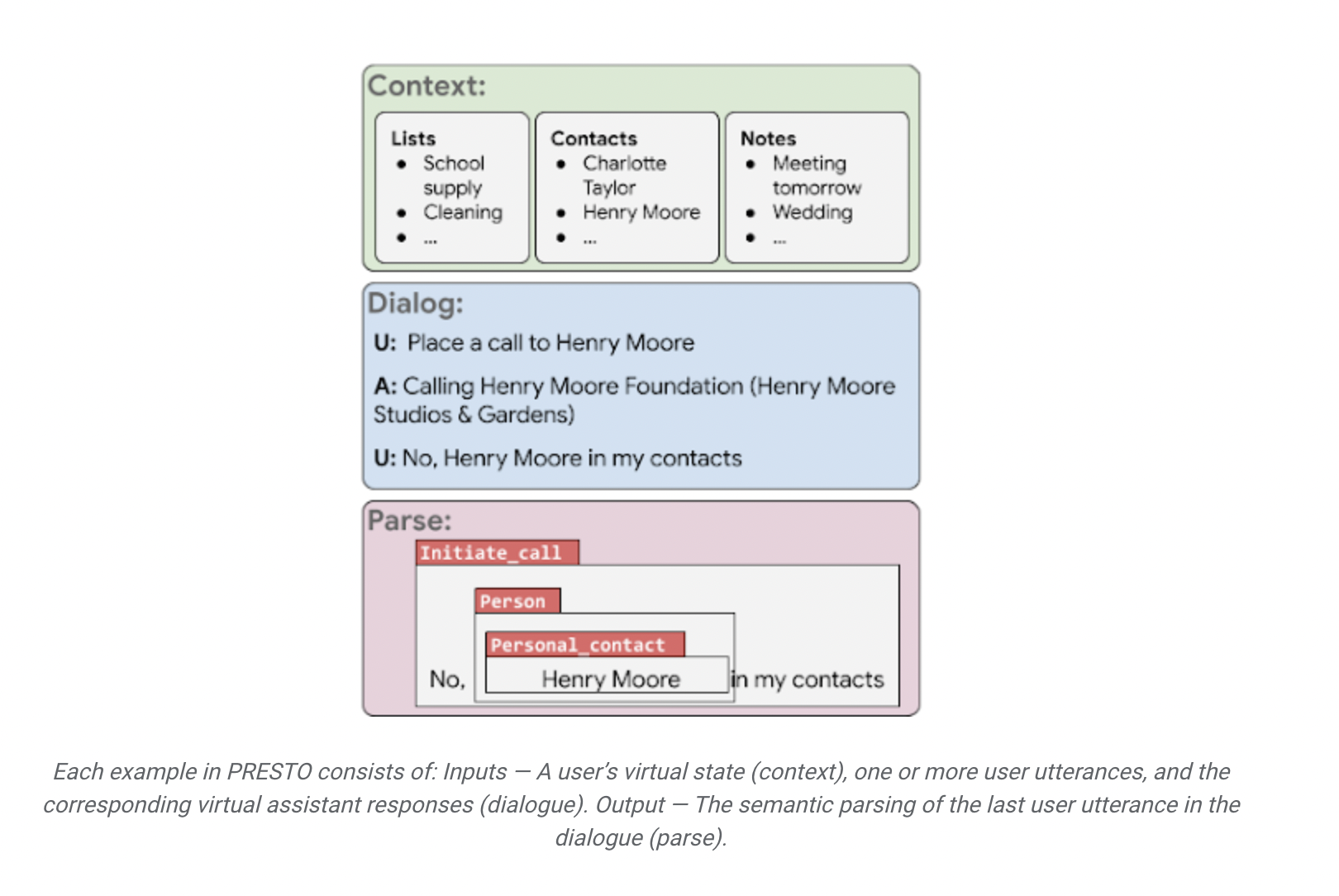
Previously, utilizing special-purpose datasets like MultiWOZ, SMCalFlow, and so forth., made it potential to deal with task-oriented conversations. Nonetheless, experiments demonstrated a number of drawbacks related to such datasets as a result of they lack speech phenomena. These embody a number of revisions to the consumer dialogue, code-mixing, and the usage of structured contexts, corresponding to notes, contacts, and so forth. For example, a digital assistant could sometimes misread the consumer’s context and dial the wrong quantity. Because of this, the consumer might want to rephrase their speech to appropriate the assistant’s error. Additionally, the digital assistant should be educated sufficient to grasp that with a purpose to full the work at hand efficiently, it wants entry to the consumer’s saved contacts. Because of this, fashions developed utilizing such datasets steadily carry out poorly, which causes buyer discontent basically. To resolve this drawback, a workforce from Google Analysis has labored on growing a brand new multilingual dataset, PRESTO, for parsing real looking task-oriented dialogues. The dataset contains over 550K real looking multilingual conversations between people and digital assistants, together with a various set of conversational eventualities {that a} consumer would possibly encounter whereas interacting with a digital agent. These embody disfluencies, code-mixing, and consumer revisions. Nonetheless, this isn’t all! PRESTO is the one large-scale human-generated dialog dataset with associated structured context, corresponding to customers’ contacts and notes related to every information level.
The PRESTO dataset spans six languages: English, French, German, Hindi, Japanese, and Spanish. One of the crucial commendable features of the dataset is that, not like earlier datasets that solely translated utterances from English to different languages, all conversations had been captured by native audio system of the languages talked about above. That is particularly helpful for capturing speech patterns and different refined variations between native audio system of various languages and English audio system after they converse. Furthermore, with a purpose to create a singular dataset, Google Researchers additionally included surrounding structured context. Earlier interactions with digital brokers have demonstrated that customers steadily use data corresponding to notes, contacts, and so forth. Nonetheless, if an agent can not entry these sources, parsing errors can happen, which is able to immediate the consumer to revise their utterance. To forestall this type of consumer dissatisfaction, PRESTO contains three kinds of structured context: notes, contacts, and consumer utterances and their parses. These lists, notes, and contacts had been created by the native audio system of every language, making it a extremely distinctive and priceless dataset.
Furthermore, assuming the necessity arises for a consumer to revise or amend their utterance whereas chatting with a digital assistant. In that case, PRESTO additionally contains annotations that reveal which conversations had some consumer revision. The need for modifications usually outcomes from one in every of two conditions: both the digital assistant misunderstood the consumer’s intent, or the consumer modified their thoughts mid-utterance. Having express annotations for such revisions considerably helps practice higher digital brokers by enhancing their pure language comprehension. Code-mixing is one other frequent drawback related to utterances that PRESTO seeks to handle. Previous investigations have proven that many bilingual customers have a tendency to change languages whereas chatting with digital assistants. PRESTO handles this by annotating code-mixed utterances, which account for about 14% of the dataset, with the help of its bilingual information contributors. The dataset moreover contains conversations with disfluencies within the type of repeated phrases or filler phrases in all six languages to supply a extra diversified dataset.
For his or her experiments, the Google researchers employed mT5-based fashions that had been skilled on PRESTO. To judge their dataset, the workforce developed express check units to individually examine mannequin efficiency, specializing in every phenomenon: consumer revisions, code-switching, disfluencies, and so forth. The outcomes confirmed that when the focused phenomena will not be included within the coaching set, zero-shot efficiency is poor, which necessitates the usage of such utterances to boost efficiency. Additionally, the findings confirmed that whereas some phenomena, like code-mixing, require a considerable amount of coaching information, others, corresponding to consumer revisions and disfluencies, are easier to mannequin with few-shot samples.
In a nutshell, PRESTO represents a major step ahead within the examine of parsing refined and real looking consumer utterances. The dataset accommodates a lot of conversations that fantastically illustrate a variety of ache factors that customers steadily expertise of their common talks with digital assistants and that are lacking from different datasets within the NLP subject. By addressing points that customers coping with digital brokers face each day, Google Analysis hopes that the tutorial group will use their dataset to advance the present state of pure language understanding analysis.
Try the Github and Blog. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t neglect to hitch our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Khushboo Gupta is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Expertise(IIT), Goa. She is passionate concerning the fields of Machine Studying, Pure Language Processing and Internet Improvement. She enjoys studying extra concerning the technical subject by collaborating in a number of challenges.
[ad_2]
Source link
