

[ad_1]
Self-supervised studying has just lately made vital strides, ushering in a brand new age for voice recognition.
In distinction to earlier research, which primarily targeting enhancing the standard of monolingual fashions for broadly used languages, “common” fashions have turn into extra prevalent in newer analysis. This could possibly be a single mannequin that excels at many roles, covers many different areas, or helps many languages. The article highlights the boundaries of language extension.
A common speech mannequin is a machine studying mannequin educated to acknowledge and perceive spoken language throughout totally different languages and accents. It’s designed to course of and analyze massive quantities of speech information. It may be utilized in varied purposes, similar to speech recognition, pure language processing, and speech synthesis.
One well-known instance of a common speech mannequin is the Deep Speech mannequin developed by Mozilla, which makes use of deep studying strategies to course of speech information and convert it into textual content. This mannequin has been educated on massive datasets of speech information from varied languages and accents and might acknowledge and transcribe spoken language with excessive accuracy.
Common speech fashions are important as a result of they permit machines to work together with people extra naturally and intuitively and may also help to bridge the hole between totally different languages and cultures. They’ve many potential purposes, from digital assistants and voice-controlled units to speech-to-text transcription and language translation.
To extend inclusion for billions of individuals worldwide, Google unveiled the 1,000 Languages Initiative, an bold plan to develop a machine studying (ML) mannequin to assist the world’s high one thousand languages. A major challenge is assist languages with comparatively few audio system or little obtainable information as a result of lower than twenty million folks communicate a few of these languages. To implement this, the staff carried out ASR(Automated Speech Recognition) on the info. Nonetheless, there are two main issues confronted by the staff.
- Scalability is an issue with conventional supervised studying methods.
- One other space for enchancment is that whereas the staff will increase the language protection and high quality, fashions should advance computationally effectively. This necessitates a versatile, efficient, and generalizable studying algorithm.
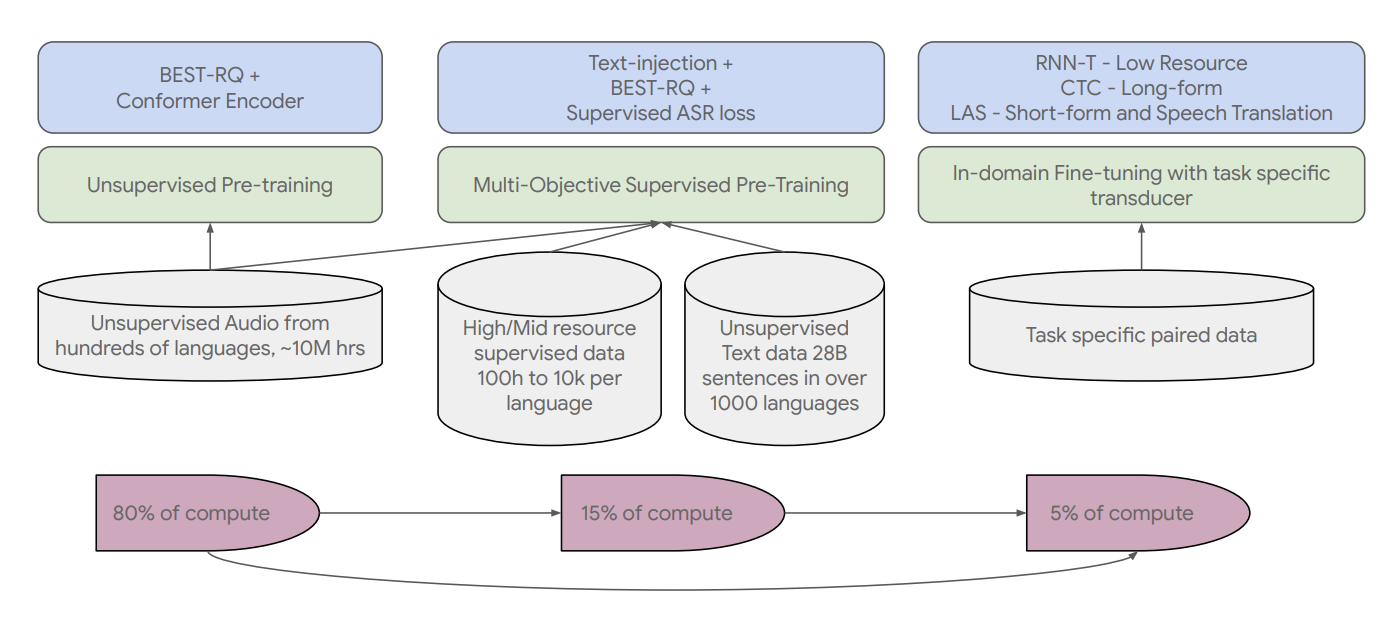
The standard encoder-decoder structure utilized by USM can embody a CTC, RNN-T, or LAS decoder because the decoder. USM employs the Conformer, a convolution-augmented transformer, because the encoder. The Conformer block, which incorporates consideration, feed-forward, and convolutional modules, is the central a part of the conformer. The voice sign’s log-mel spectrogram is used because the enter. Convolutional sub-sampling is then used to create the ultimate embeddings, obtained by making use of a sequence of Conformer blocks and a projection layer.
The coaching course of begins with a stage of unsupervised studying on speech audio that features tons of of various languages. The mannequin’s high quality and language protection could be elevated with an extra pre-training stage utilizing textual content information within the second elective step. If textual content information is accessible will decide whether or not the second step must be included. With this second elective step, USM performs greatest. With minimal supervised information, the coaching pipeline’s remaining stage includes fine-tuning downstream duties (similar to automated voice recognition or automated speech translation).
By pre-training, the encoder incorporates greater than 300 languages. The pre-trained encoder’s effectivity is proven by fine-tuning the multilingual voice information from YouTube Caption. Lower than three thousand hours of information are current in every language within the 73 languages included within the supervised YouTube information. Regardless of the minimal educated information, the mannequin achieves an unprecedented benchmark of a mean phrase error charge (WER; decrease is best) of lower than 30% throughout all 73 languages.
Creating USM is crucial in attaining Google’s objective of organizing and facilitating world entry to data. The scientists assume that USM’s base mannequin structure and coaching pipeline present a framework that may be developed to increase speech modeling to the following 1,000 languages.
Try the Paper, Project and Blog. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd 12 months undergraduate, at present pursuing her B.Tech from Indian Institute of Know-how(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Knowledge science and AI and an avid reader of the newest developments in these fields.
[ad_2]
Source link
