

[ad_1]
Transferring pre-trained imaginative and prescient backbones has enhanced efficiency on numerous imaginative and prescient duties, very similar to pure language processing. Bigger datasets, scalable infrastructures, and modern coaching strategies have boosted its rise. Regardless of this, language fashions have considerably outperformed imaginative and prescient fashions when it comes to emergent capabilities at giant scales. The very best dense language mannequin has 540B parameters, the most important dense imaginative and prescient mannequin has simply 4B parameters, and a reasonably parameterized mannequin for an entry-level aggressive language mannequin typically includes over 10B parameters.
Language fashions have greater than a trillion parameters, but the largest recorded sparse imaginative and prescient fashions solely have 15B. Sparse fashions present the identical tendency. The largest dense ViT mannequin so far, ViT-22B, is offered on this work. They establish pathological coaching instabilities that impede scaling the default recipe to 22B parameters and present architectural enhancements that allow it. Furthermore, they fastidiously design the mannequin to supply model-parallel coaching with hitherto unheard-of effectivity. A radical evaluation suite of duties, spanning from classification to dense output duties, is used to find out if ViT-22B meets or exceeds the present state-of-the-art.
With 22 billion parameters, ViT-22B is the largest imaginative and prescient transformer mannequin out there. As an illustration, ViT-22B obtains an accuracy of 89.5% on ImageNet even when utilized as a frozen visible function extractor. It achieves 85.9% accuracy on ImageNet within the zero-shot state of affairs utilizing a textual content tower educated to match these visible attributes. The mannequin can be a superb teacher; utilizing it as a distillation goal, they educate a ViT-B pupil who scores an industry-leading 88.6% on ImageNet. Enhancements in dependability, uncertainty estimates, and equity tradeoffs accompany this efficiency. Lastly, the mannequin’s properties extra carefully match how individuals see issues, yielding a beforehand unheard-of kind bias of 87%.
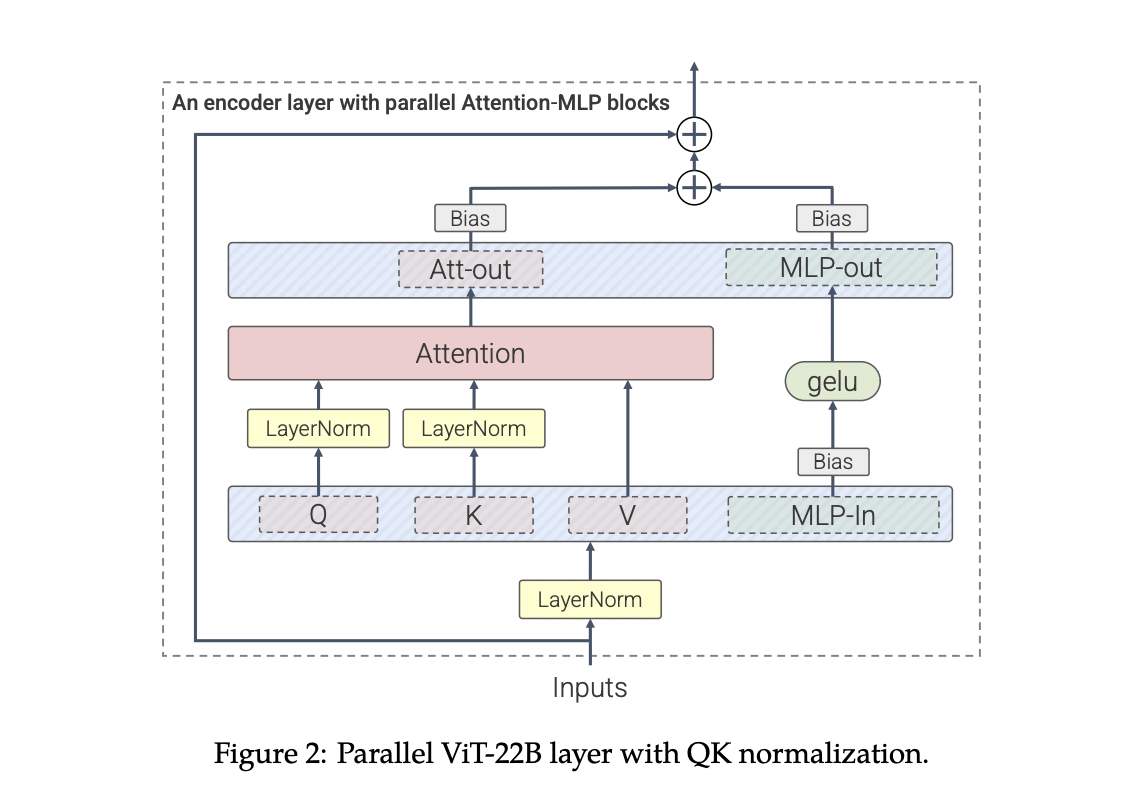
ViT-22B is a Transformer-based encoder mannequin with parallel layers, question/key (QK) normalization, and omitted biases to extend effectivity and coaching stability at scale. Its structure is much like that of the unique Imaginative and prescient Transformer.
Overlapping layers. As an alternative of sequentially making use of the Consideration and MLP blocks as within the conventional Transformer, ViT-22B does it in parallel. The linear projections from the MLP and a spotlight blocks enable for various parallelization.
Normalization of QK. After just a few thousand steps, they noticed diverging coaching loss whereas rising ViT past earlier efforts. Notably, fashions with about 8B parameters confirmed comparable instability. It was introduced on by abnormally excessive consideration logit values, which produced consideration weights that have been virtually one-hot and had nearly no entropy. They use the strategy of making use of LayerNorm on the queries and keys earlier than the computation of the dot-product consideration to handle this and exclude biases from LayerNorms and QKV projections. After PaLM, all LayerNorms have been utilized with out bias or centering, and the bias phrases from the QKV projections have been eradicated.
They display how the unique design could also be improved to realize excessive {hardware} utilization and coaching stability, producing a mannequin that outperforms the SOTA on a number of benchmarks. Specifically, glorious efficiency could also be obtained by creating embeddings with the frozen mannequin, then coaching skinny layers on prime of these embeddings. Their analyses additional display that ViT-22B outperforms earlier fashions in equity and robustness and is extra much like individuals when it comes to form and texture bias. The code and dataset are but to be launched.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with individuals and collaborate on fascinating tasks.
[ad_2]
Source link
